
前言
上周启动居家开会的时候,看到有人通过「虚拟形象」功能,给自己带上了口罩、眼镜之类,于是想到了是不是也可以搞一个简单的虚拟形象系统。
大致想来,分为以下几个部分:

卷积神经网络(CNN)
下面讲解一下三层CNN网络模型:
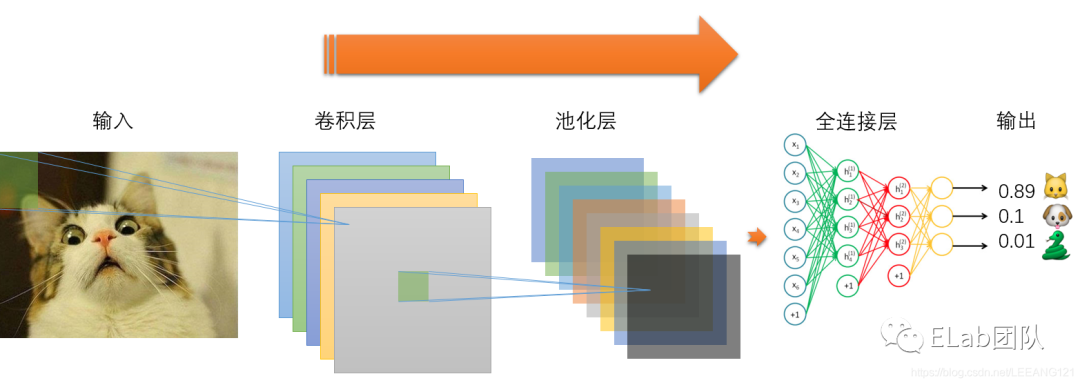
卷积层——提取特征
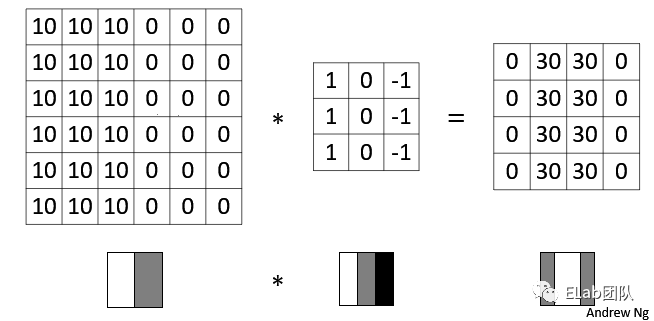
卷积层的运算过程如下图,用一个卷积核扫完整张图片:
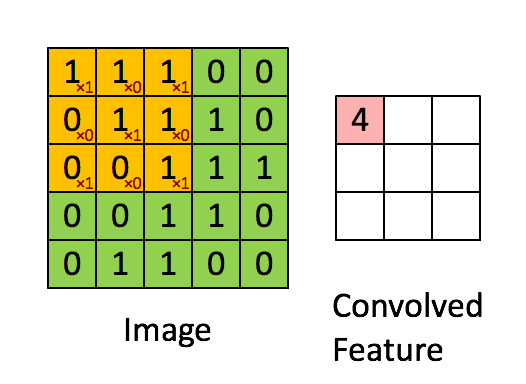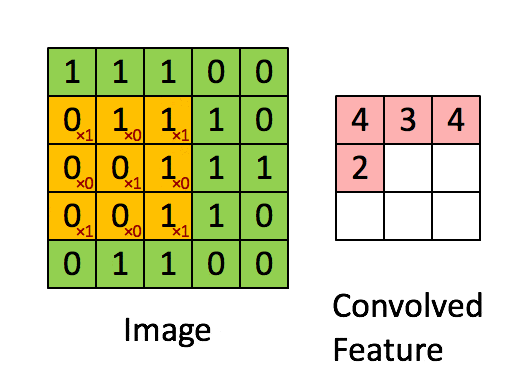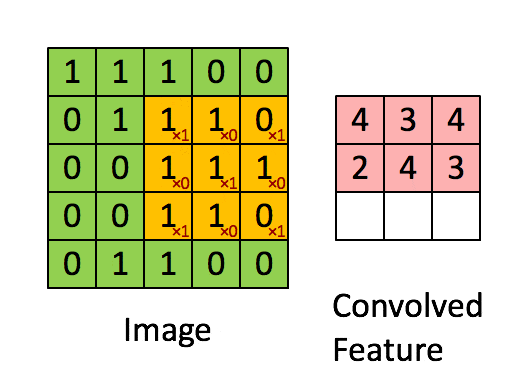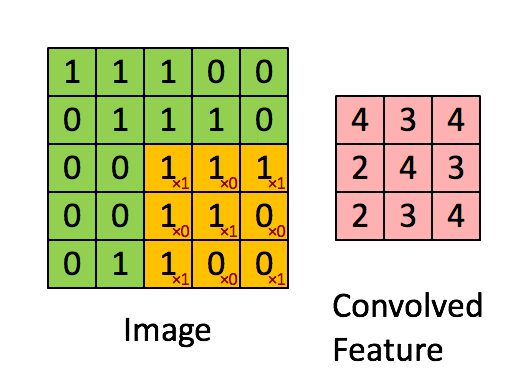
通过动图能够更好的理解卷积过程,使用一个卷积核(过滤器)来过滤图像的各个小区域,从而得到这些小区域的特征值。
在具体应用中,往往有多个卷积核,每个卷积核代表了一种图像模式(特征规则),如果某个图像块与此卷积核卷积出的值大,则认为此图像块十分接近于此卷积核。如果有N个卷积核,那么就认为图像中有N种底层纹理(特征),即用这N种基础纹理就能描绘出一副图像。
总结: 卷积 层的通过卷积核的过滤提取出图片中局部的特征。
疑问:上图卷积后,存在边缘数据特征提取减少,大家能想到什么方式处理呢?
池化层(下采样)——数据降维,避免过拟合
池化层通常也被叫做下采样,目的是降低数据的维度,减少数据处理量。其过程大致如下:
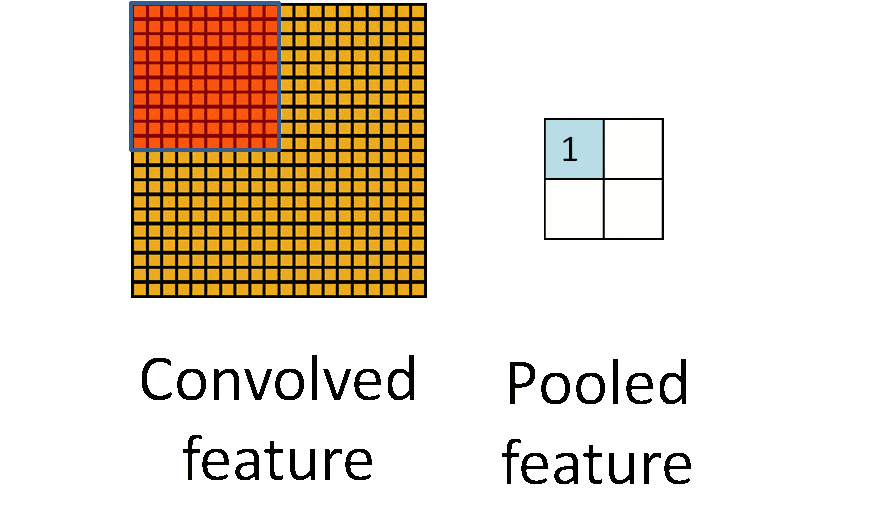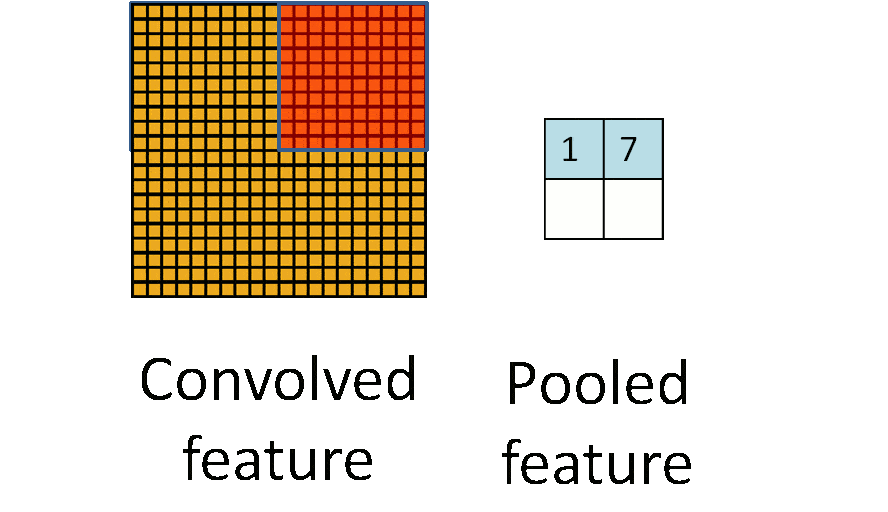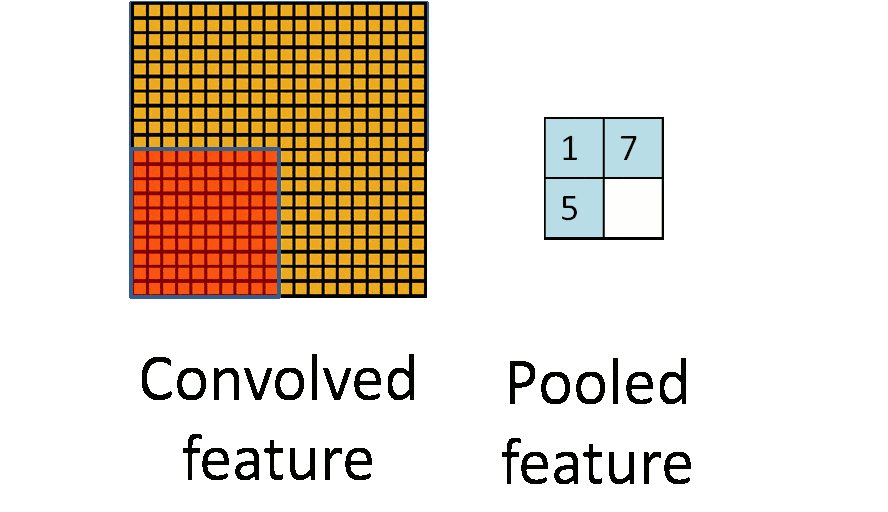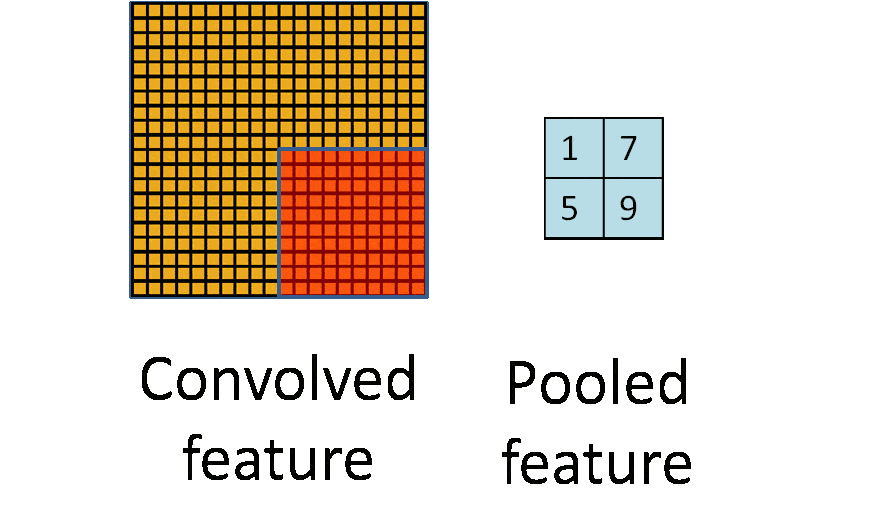
上图输入时是20×20的,先进行卷积采样,卷积核为10×10,采用最大池化的方式,输出为一个2×2大小的特征图。这样可将数据维度减少了10倍,方便后续模块处理。
总结:池化层相比 卷积 层可以更有效的降低数据维度,不仅可减少运算量,还可以避免 过拟合 。
过拟合是指训练误差和测试误差之间的差距太大。换句换说,就是模型复杂度高于实际问题,模型在训练集上表现很好,但在测试集上却表现很差。模型对训练集”死记硬背”(记住了不适用于测试集的训练集性质或特点),没有理解数据背后的规律,泛化能力差。
全连接层——输出结果
全链接层是将我们最后一个池化层的输出连接到最终的输出节点上。假设,上述CNN的最后一个池化层的输出大小为 [5×5×4],即 5×5×4=100 个节点。对于当前任务(仅识别🐱、🐶、🐍),我们的输出会是一个三维向量,输出层共 3 个节点,如输出[0.89, 0.1, 0.001],表示0.89的概率为猫。在实际应用中,通常全连接层的节点数会逐层递减,最终变为n维向量。
举个例子
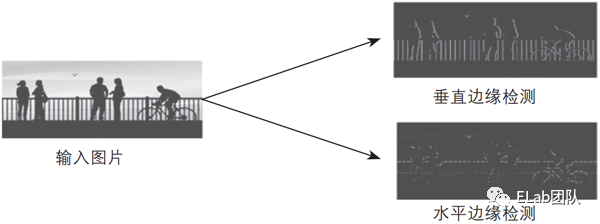
假设我们有2个检测的特征为「水平边缘」和「垂直边缘」。「垂直边缘」卷积过程如下:
最终结果如下:
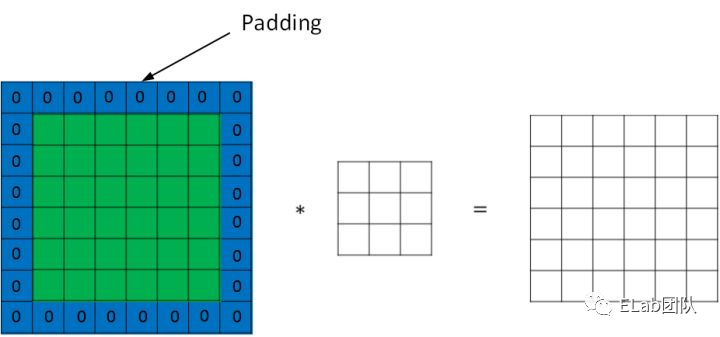
Q&A环节
没错啦,前面的问题的答案就是边缘填充。
face-api.js
face-api.js 是基于 tensorflow.js 实现的,内置了一些训练好的模型,这些模型应该是这个方案的核心,通过这些预先训练好的模型,我们可以直接使用而不需要自己再去标注、训练,极大的降低了成本。
主要提供的功能如下:
- 人脸检测:获取一张或多张人脸的边界,可用于确认人脸的位置、数量和大小
- 人脸特征检测:包含68个人脸特征点位,获取眉毛、眼睛、鼻子、嘴、嘴唇、下巴等的位置和形状
- 人脸识别:返回人脸特征向量,可用于辨别人脸
- 人脸表情识别:获取人脸表情特征
- 性别和年龄检测:判断年龄和性别。其中“性别”是判断人脸的女性化或男性化偏向,与真实性别不一定挂钩
人脸检测
针对人脸检测,face-api 提供了 SSD Mobilenet V1 和 The Tiny Face Detector 两个人脸检测模型:
- SSD Mobilenet V1:能够计算图像中每个人脸的位置,并返回边界框以及每个框内包含人脸的概率,但是这个模型有 5.4M,加载需要比较长的时间,弱网环境下加载过于耗时。
- The Tiny Face Detector :这个模型性能非常好,可以做实时的人脸检测,且只有190kB,但是检测准确性上不如 SSD Mobilenet V1,且在检测比较小的人脸时不太可靠。相对而言,比较适合移动端或者设备资源优先的条件下。
人脸特征检测
针对人脸特征检测, 提供了 68 点人脸特征检测模型,检测这 68 个点的作用是为了后续的人脸对齐,为后续人脸识别做准备,这里提供了两个大小的模型供选择:350kb和80kb,大的模型肯定是更准确,小的模型适合对精确度要求不高,对资源要求占用不高的场景。其输出的区域特征点区间固定如下:
| 区域 | 区间 |
|---|---|
| 下巴 | [1, 16] |
| 左眉 | [18, 22] |
| 右眉 | [23, 27] |
| 鼻梁 | [28, 31] |
| 鼻子 | [32, 26] |
| 左眼 | [37, 42] |
| 右眼 | [43, 48] |
| 外嘴唇 | [49, 60] |
| 内嘴唇 | [61, 68] |

人脸识别
经过人脸检测以及人脸对齐以后,将检测到的人脸输入到人脸识别网络进行识别,从而获得一个128维的人脸特征向量。通过计算两个向量之间的距离(余弦值),就可以判断相似度。
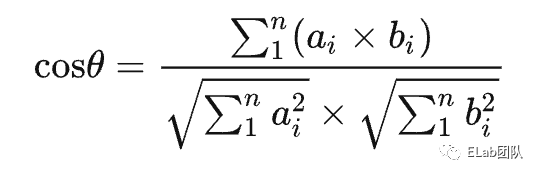
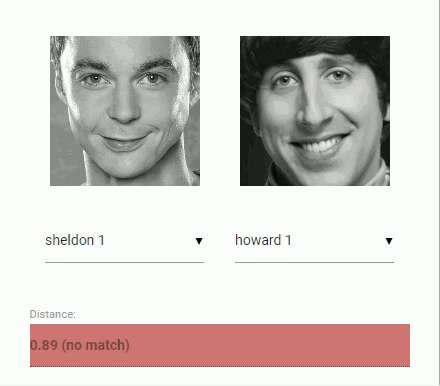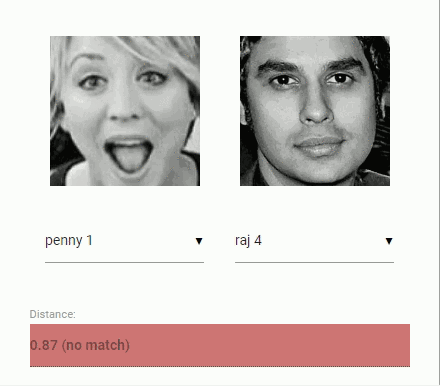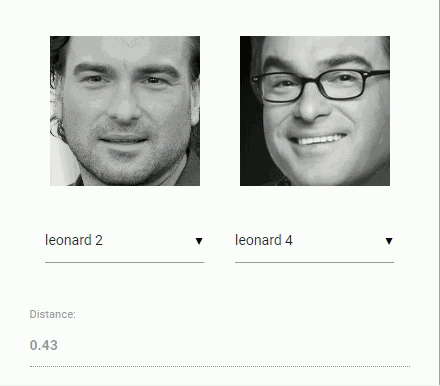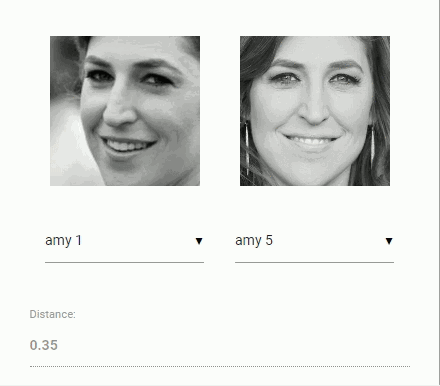
虚拟形象系统
获取人脸图像
目前主流浏览器提供了WebRTC能力,我们可以调用getUserMedia方法指定设备采集音视频数据。其中constrains详情参考 MediaTrackConstraints – Web APIs | MDN[1]。
const constraints = { audio: true, video: { width: 1280, height: 720 } };
const setLocalMediaStream = (mediaStream: MediaStream) => {
videoRef.current.srcObject = mediaStream;
}
navigator
.mediaDevices
.getUserMedia(constraints)
.then(setLocalMediaStream)获取人脸特征
根据官方文档介绍,The Tiny Face Detector模型与人脸特征识别模型组合的效果更好,故本文使用的人脸检测模型是The Tiny Face Detector。
这个模型有两个参数可以调整,包括 inputSize 和 scoreThreshold,默认值是 416 和 0.5。
inputSize:表示检测范围(人脸边框),值越小检测越快,但是对小脸的检测准确不足,可能会检测不出,如果是针对视频的实时检测,可以设置比较小的值。scoreThreshold:是人脸检测得分的阈值,假如在照片中检测不到人脸,可以将这个值调低。
- 首先我们要选择并加载模型(这里使用官网训练好的模型和权重参数)
// 加载人脸检测模型
await faceApi.nets.tinyFaceDetector.loadFromUri(
'xxx/weights/',
);
// 加载特征检测模型
await faceApi.nets.faceLandmark68Net.loadFromUri(
'xxx/weights/',
);- 转换人脸检测模型。face-api的人脸检测模型默认是
SSD Mobilenet v1,这里需要显式调整为The Tiny Face Detector模型。
const options = new faceApi.TinyFaceDetectorOptions({
inputSize,
scoreThreshold,
});
// 人脸68点位特征集
const result = await faceApi
.detectSingleFace(videoEl, options) // 人脸检测
.withFaceLandmarks(); // 特征检测形象绘制
经过上述计算,我们已经拿到了人脸68点位特征集。需要先计算点位相对坐标信息,然后进行形象绘制。
const canvas = canvasRef.current;
const canvasCtx = canvas.getContext('2d');
const dims = faceApi.matchDimensions(canvas, videoEl, true);
const resizedResult = faceApi.resizeResults(result, dims);本文使用的是一张256*256的口罩图片,选取1号和16号点位绘制口罩,根据两点位之间的距离缩放口罩大小。

这里主要调研了两种方式,分别是canvas绘制和媒体流绘制。
canvas绘制
首先想到的一种方式,video和canvas大小和位置固定,定时抓取video媒体流中图片,进行识别人脸,然后绘制在canvas上。
const { positions } = resizedResult.landmarks;
const leftPoint = positions[0];
const rightPoint = positions[16];
const length = Math.sqrt(
Math.pow(leftPoint.x - rightPoint.x, 2) +
Math.pow(leftPoint.y - rightPoint.y, 2),
);
canvasCtx?.drawImage(
mask,
0,
0,
265,
265,
leftPoint.x,
leftPoint.y,
length,
length,
);媒体流绘制
canvas提供了一个api叫做 captureStream[2],会返回一个继承MediaStream的实例,实时视频捕获画布上的内容(媒体流)。我们可以在canvas上以固定帧率进行图像绘制,获取视频轨道。

这样我们仅需保证video和canvas大小一致,位置无需固定,甚至canvas可以离屏不渲染。
const stream = canvasRef.current.captureStream()!;
mediaStream = res[0].clone();
mediaStream.addTrack(stream.getVideoTracks()[0]);
videoRef.current!.srcObject = mediaStream;对比
- canvas绘制兼容性更好,但在实时通信场景下,需传递点位信息或端重复计算,容易受网络波动以及硬件设备影响,导致实际绘制出现偏差(依赖端能力)
- 媒体流绘制兼容性较差,但是在直播等场景下效果会更好,在输出端做好已经做好媒体流融合,接收端依托媒体能力播放即可。同时内容也不易篡改
实际效果
因为这里仅使用了2个点位的信息,所以效果一般般。我们完全可以充分利用68个点位全面换肤,实现各种效果。
延伸思考
- 测评场景下:判断人脸数量、是否是用户本人,自动提醒用户,异常状态记录日志,监控人员可以后台查看
- 学习场景下:判断用户是否离开屏幕等,提醒用户返回学习状态。
- 弹幕场景下:检测人脸,解决弹幕遮挡问题
…(欢迎补充)
本文为来自 字节教育-成人与创新前端团队 成员的文章,授权 ELab 发布。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
