
本文是T-CSVT 2022接收论文《DMVC: Decomposed Motion Modeling for Learned Video Compression》的解读。该论文由北京大学马思伟课题组完成。针对端到端视频压缩中的运动建模,该论文提出了一种高效的运动分解方法,将视频相邻帧之间的运动自适应分解为内在运动信息和扩展运动信息。通过渐进式的运动补偿方式,提升帧间预测的效率。实验证明,提出的方法在多个指标上达到领先性能,在MS-SSIM指标上可以超越传统编码方法VVC。
论文地址:https://ieeexplore.ieee.org/document/10003249
代码地址:https://github.com/Linkeyboard/DMVC
引言
参考混合编码框架发展的历史,目前大多数的端到端视频编码方法仍然采用以运动矢量(Motion Vector, MV)为核心的帧间预测,结合反向映射实现运动补偿。相比于传统方法中的块级匹配搜索,目前端到端方法中应用的MV是像素级别的稠密光流。光流可以通过预训练的光流网络显式生成或者隐式导出。前者依赖于预训练的光流网络首先生成稠密光流,随后利用非线性变换进行压缩。而在后一种框架中,编码器只负责提取高维特征,解码器在特征解码的同时推导出所需的重建光流,整个过程在码率和失真的指导下端到端优化。
虽然像素级的光流可以有效建模相邻帧像素之间的时域相关性,但是这种稠密光流在复杂的编码场景下仍然存在着不足。首先,根据亮度守恒假设,光流只能标识参考帧中已存在的相似样本,这种内在特性使得光流无法处理低时延场景下的不确定性,例如遮挡问题,或者场景内新出现的物体。而且,这种稠密光流场存在大量的时空域冗余,限制了光流的高效压缩。在此背景下,一种高效且紧凑的运动表示方法成为端到端视频压缩的核心问题。
相较于基于MV 的端到端视频压缩方法,本文提出从时空预测的角度来设计运动预测和运动补偿模块。具体来说,运动可以自适应地分解为两部分,分别是内在运动信息和扩展运动信息。内在运动指的是一段时间内有规律的连续运动,可以从连续的已解码帧中预测推演,不需要消耗额外的码率。利用内在运动信息,可以通过ConvLSTM等时序模型进行时域转换,获得初始的预测信号。而扩展运动针对第一步时域转换的不足,进行调整和增强,以边信息的形式进一步提升帧间预测效果。在码率和失真的约束下,这两部分可以进行联合优化。
方法简介
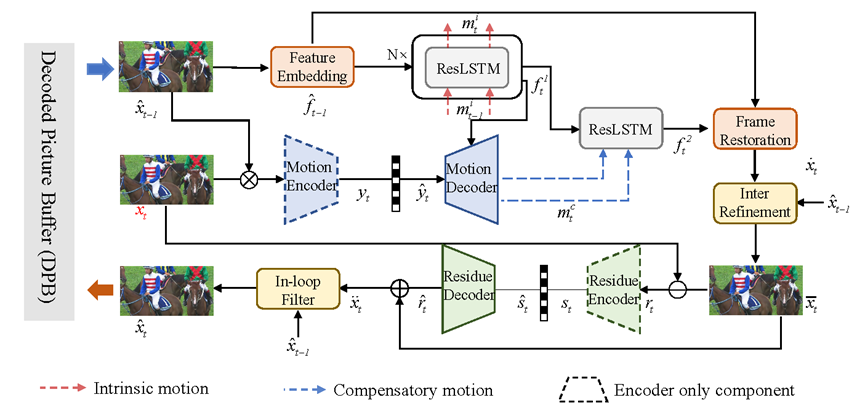
本文所提出的端到端视频编码方法(DMVC)基本框架如图1所示,主要包括以下几部分,特征提取和复原模块,内在运动模块,扩展运动模块,残差编码模块,增强模块。
- 帧间预测过程是在特征空间进行的,本文首先引入了一组结构对称的特征提取和复原模块。特征提取模块将原始的RGB三通道输入映射到特征空间,在空域下采样的过程中,不同尺度的特征被保存下来对应连接到后续特征增强模块中。
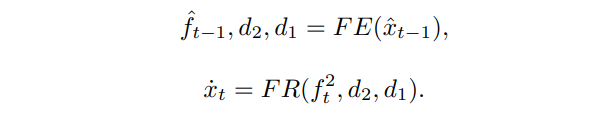
2. 由于连续运动场之间的时空相关性,可以利用ConvLSTM等时序单元从已解码重构帧中隐式推导一段时间内的内在运动,进行初始的时域转换。在ConvLSTM单元的内部推理过程中,以最邻近的参考特征与沿着时域维度传播的内在运动为输入,可以实现如下转换:
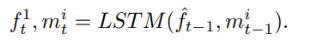
3. 内在运动基本反映了运动物体的潜在运动趋势,为了进一步提升帧间预测的效率,本文提供了扩展运动信息对第一步的时域转换信号在特征域进行调整和增强。在扩展运动信息的运动补偿模块中,采用ConvLSTM单元拟合时域转换的过程,转换过程如下:
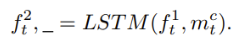
如图2所示,本文提出的运动分解模块可以通过链式的ConvLSTM建模,基于内在运动的转换过程可以看作是帧间预测的基本层,基于扩展运动的转换过程作为增强层。与内在运动信息不同的是,扩展运动信息利用一组编解码器从原始像素中学习,需要以码流的形式传递到解码端。这里我们采用一阶段的非监督学习策略来导出扩展运动信息。
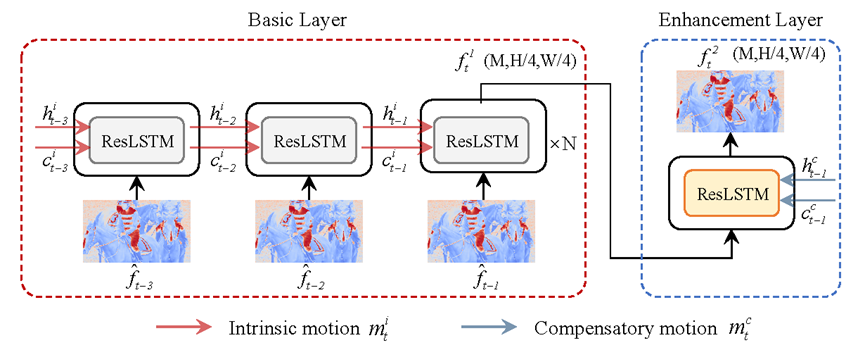
图2 基于链式ConvLSTM的运动分解模块
4. 残差编码模块采用了端到端图像编码方法(cheng2020)来进一步压缩帧间预测与原始像素之间的差值,提升重构质量。
5. 框架中还包含帧间预测增强、环路滤波的多阶段增强模块,以重构帧作为引导信息,通过卷积神经网络对预测像素、重构像素进行改善增强。
实验
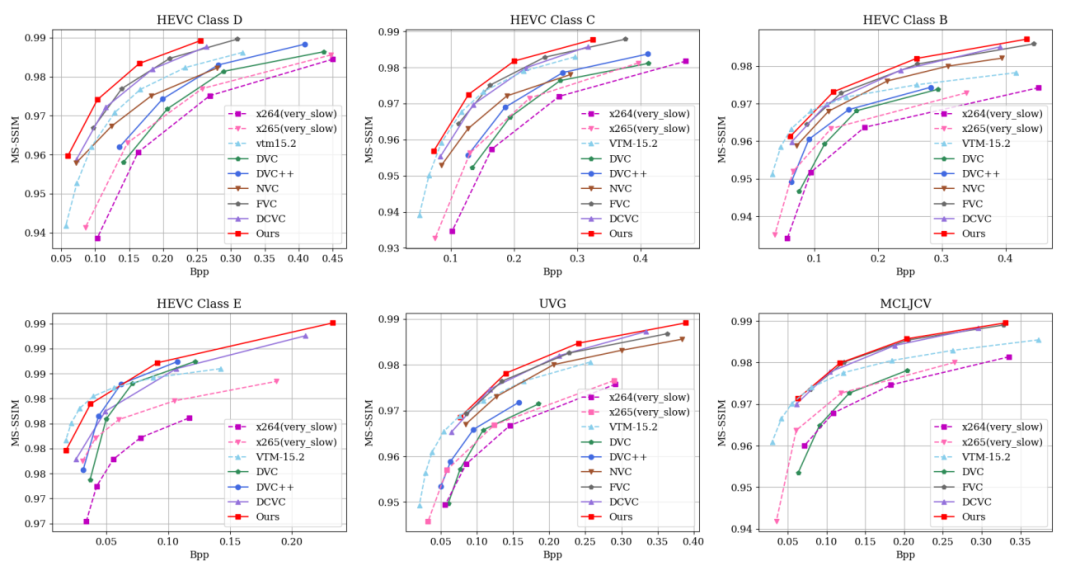
本文提出的方法在多个通用的视频压缩测试集上进行了性能测试,包含HEVC通用测试序列、UVG数据集、MCLJCV数据集。在网络训练的过程中,通过调整损失函数的失真度量指标分别训练MS-SSIM指标模型、PSNR指标模型,将训练好的模型与传统视频编码方法和其他端到端视频编码方法进行了对比。如图3所示,在MS-SSIM指标上,DMVC领先同期的端到端视频编码方法FVC、DCVC,同时可以超越最新的混合编码框架VVC。在PSNR指标上,DMVC同样可以达到领先水平,在ClassD、ClassC等HEVC通用测试序列上具有一定性能优势。
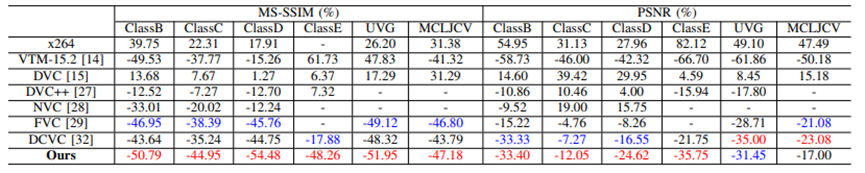
图3 DMVC在MS_SSIM指标与PSNR指标的压缩性能
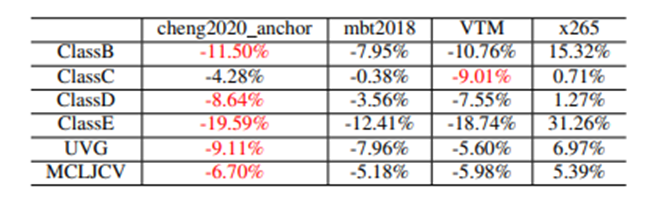
本文对低时延场景下的IPPP参考结构进行了进一步探索,包含帧内编码类型,参考图像组(GOP)长度等。如图5所示,以BPG作为测试基准,实验结果发现帧内编码方法显著影响了最终的视频编码效率,采用cheng2020_anchor等性能优越的图像编码方法可以带来更高的性能增益。在IPPP参考结构中,重构帧的客观质量一般会随着与I帧时域距离的增加呈现下降趋势,但是频繁设置I帧会对码率带来较大的负担。我们提供了对比实验结果来探索不同GOP长度对整体编码效率的影响。对于HEVC通用测试序列集,GOP长度设置为20或25可以实现较优的编码性能。
对应渐进式的帧间预测框架,我们展示了利用内在运动、扩展运动进行第一步、第二步的时域转换结果,同时利用光流网络可视化对应的运动示意图。如图6所示,内在运动可以正确推演物体的运动趋势,完成基本的时域转换。在此基础上,扩展运动可以调整和增强,提升帧间预测的准确性。这种渐进式的帧间预测与预期一致,反映了运动分解框架的有效性。

更多的方法及实验分析与讨论的细节请参考原文。
参考文献:
[1] Hu Z, Lu G, Xu D. FVC: A new framework towards deep video compression in feature space[C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1502-1511.
[2] Li J, Li B, Lu Y. Deep contextual video compression[J]. Advances in Neural Information Processing Systems, 2021, 34: 18114-18125.
[3] Cheng Z, Sun H, Takeuchi M, et al. Learned image compression with discretized gaussian mixture likelihoods and attention modules[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 7939-7948.
来源:PKUVCL。北京大学视频与视觉技术国家工程研究中心视频编码算法与标准研究室(PKUVCL)长期致力于我国AVS视频编码标准制定及智能视频压缩前沿技术探索,积极推动AVS3开源平台和产业化建设,为AVS3标准技术支撑的5G、8K超高清深化应用提供更高效的助力。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/8305.html
