
本论文提出了一种 One-shot 的方案,将单张图片利用 SMPL 和 CLIP 两种先验变为一个可动画、可多视角渲染的数字人。
来源:Arxiv
论文作者:Yangyi Huang, Hongwei Yi等
论文链接:https://arxiv.org/pdf/2212.02469.pdf
项目主页:https://elicit3d.github.io/
内容整理:王炅昊
目录
- 摘要
- 介绍:CLIP
- 问题定义
- 方法
- 整体流程
- 几何先验
- 语义先验
- 结果展示
摘要
现有的用于创建人类化身的神经渲染方法通常需要密集的输入信号,例如视频或多视图图像,或者利用从大规模特定 3D 人类数据集中学习的先验知识,以便可以使用稀疏视图输入执行重建。当只有单个图像可用时,大多数这些方法都无法实现逼真的重建。为了能够高效地创建逼真的可动画 3D 人类,作者提出了 ELICIT,这是一种从单个图像中学习人类特定神经辐射场的新方法。作者在 ELICIT 中利用了两个先验:3D 几何先验和视觉语义先验。具体来说,ELICIT 在基于蒙皮顶点的模板模型(即 SMPL)之前引入 3D 体形几何,并在基于 CLIP 的预训练模型中实现视觉服装语义。这两个先验都用于共同指导在不可见区域创建合理内容的优化。为了进一步改善视觉细节,作者提出了一种基于分割的采样策略,可以局部细化化身的不同部分。
介绍:CLIP
CLIP是一种视觉语言模型,使用从大量网络抓取中收集的 4 亿个不同的图像文本对数据进行预训练。该模型由一个图像编码器EI和一个文本编码器ET组成,它们都是基于 transformer 的模型。CLIP 通过拉动配对图像和文本的嵌入,并将未配对的嵌入分开来学习文本和图像的联合嵌入空间。CLIP 预训练图像编码器可以捕获图像的视图一致的高级视觉属性,如艺术风格、颜色和高级语义属性,包括对象标签和类别。它还可以为新视角合成提供 3D 感知先验知识。
问题定义


方法
整体流程
本文的整体训练流程如下图所示:
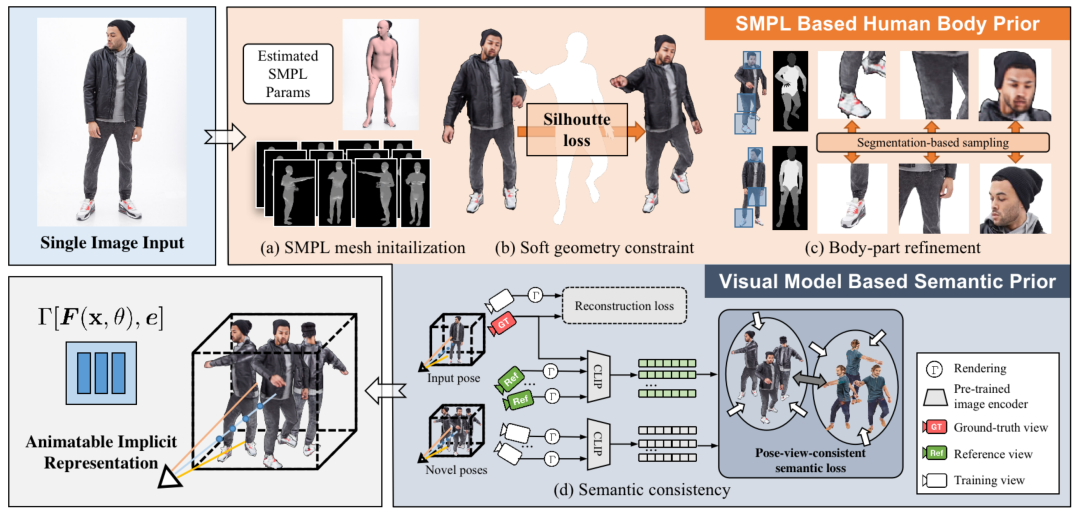
作者介绍了两种基于模型的先验来指导优化,基于 SMPL 的人体先验和基于视觉模型的语义先验。对于先验人体,作者首先使用 (a) 由 SMPL Mesh渲染的多视图视频帧,来初始化隐式表示的姿势条件几何。(b) 在训练期间,使用轮廓损失来约束合成的几何形状和身体姿势,并且 (c) 使用分部分采样策略,来细化身体部位的细节。此外,语义先验在One-shot学习中起着至关重要的作用,它通过强大的预训练视觉模型为新姿势的新视图提供(d)人体姿态视图一致的语义监督。
几何先验
通过结合现成的姿势估计模型,作者可以从 SMPL 中获得关于近似人体形状和身体部位分割的先验。作者的方法通过引入基于 SMPL 的 NeRF 初始化、训练中的软几何约束,以及用于身体部位的、细化的细粒度采样策略,利用这种特定于人类的先验作为 3D 人体重建和动画的几何和语义信息。
基于SMPL的NeRF初始化

软几何约束
尽管 CLIP 嵌入在不同的姿势和视图之间是相似的,但仅使用语义损失优化模型,可能会导致渲染姿势不一致和身体部位缺失的退化结果。对于这个问题,作者基于估计的 SMPL Mesh,其接近目标角色的几何形状的假设,引入了软几何约束损失。
该损失函数可以被写为:
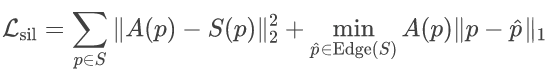
其中, 为SMPL的轮廓Mask,则是渲染出的透明度图。此约束在训练期间,约束了人物在不同运动情况下的姿态。此外,它确保语义损失监督将优化到更合理的方向,使其能够对看不见的内容进行符合常理的补充,而不是使渲染的角色姿势更接近参考视图。
躯干部份优化

为了进一步提高细化质量,作者进一步利用了关于身体方向的先验知识。现有的基于 NeRF 优化的 3D 生成方法遇到了 Janus 问题,这意味着学习的 3D 模型具有多个脸。对于这个问题,作者不为每个训练Vtrain从输入图像Vs中采样参考块,而是采样相邻的渲染视图作为参考V ,或从特定方向观察的某些身体部位K 。例如,当对人物头部的后视图进行采样进行训练时,作者从左后或右后方向选择一个参考视图,这可能在输入图像中部分可见。作者使用这个渲染图像作为参考,以避免在背面生成另一张脸,并在作者的任务中稳健地解决 Janus 问题的大多数失败案例。例如,当对人物头部的后视图进行采样进行训练时,作者从左后或右后方向选择一个参考视图,这可能在输入图像中部分可见。作者使用这个渲染图像作为参考,以避免在背面生成另一张脸,并在作者的任务中稳健地解决 Janus 问题的大多数坏情况。
语义先验
CLIP-NeRF 中发现, CLIP 预训练模型能够将 3D 对象的图像,嵌入到视图一致的语义空间中。作者进行了评估,发现这种嵌入能力,对于人类图像也是视图且姿态一致的,如下图所示:
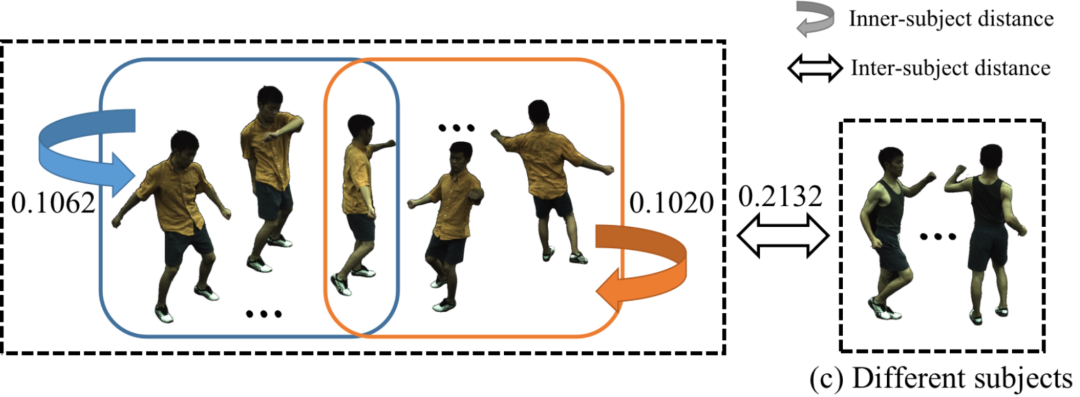
从上图中作者发现,同一个角色在不同视角和姿势下的embedding距离,明显小于两个不同角色之间的距离。

结果展示
数据集
作者主要在ZJU-MoCap、Human 3.6M两个数据集上进行了实验,并和Neural Body、Animatable Nerf以及Neural Human Performer等方法进行了比较。
客观结果
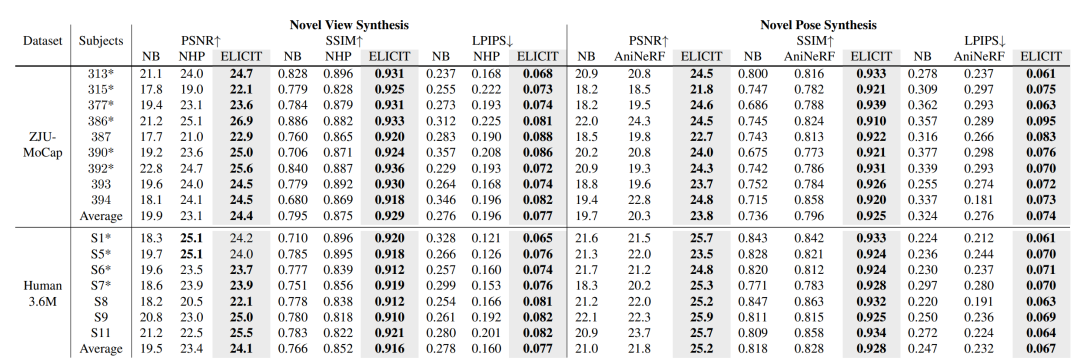
从PSNR、SSIM、LPIPS等客观指标中,作者的方案均取得了最佳效果。
主观结果
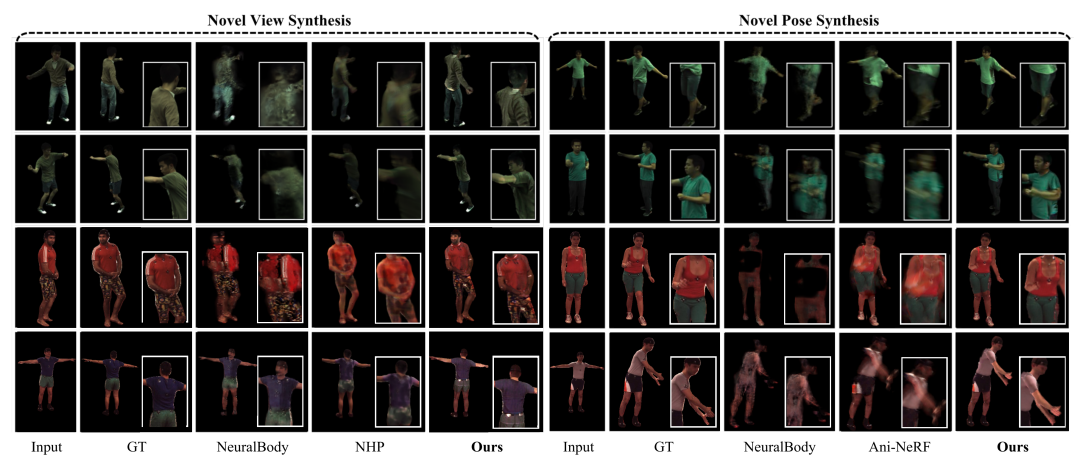
上图展示了作者提出方法在新视角和新姿态合成上的结果。可以发现,作者的方法在两个分支中,与其他方法的对比均取得了更好的效果,并且人工痕迹更不明显。

上图中,作者做了一些消融实验,验证了他们方案中不同部分的有效性。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
