
当前的感知视觉质量评价指标(Perceptual Visual Quality Metrics,PVQMs)通常是复杂且不可微的,这使得它们很难在恢复和压缩调优中用作损失函数,传统指标如 PSNR 和 MSE 虽然被广泛应用,但不能捕获感知视觉的特性。本文提出了一个 DNN 来估计一个应用广泛的感知视频度量指标 VMAF。通过引入了一个与感知度量密切匹配的可微损失函数,利用 H.265 压缩产生的损伤,提出的模型在预测VMAF 时获得了 4.41% 的RMSE。
作者:Darren Ramsook; Noel O’Connor等
来源:The 35th Picture Coding Symposium
论文题目:A differentiable estimator of VMAF for Video
内容整理:彭峰
论文链接:https://ieeexplore.ieee.org/iel7/9477292/9477396/09477480.pdf?casa_token=Qi9YGXhtyLgAAAAA:rrMIsizdOr_k5tjG-08QUjT15nMLKoqHwQe1Qk1Clhv90c-Ck9ibIud0YkiaFM-aaQ-5ZvraW3vp
目录
- 背景介绍
- 创新点
- 问题公式化
- 训练集选取
- 实验结果
- 总结
背景介绍
感知视觉质量评价指标(PVQMs)的研究由来已久,这些指标试图捕捉人类视觉系统(HVS)的感知评估特征。全参考(Full-Reference, FR) PVQMs 允许将损伤信号与原始/参考信号进行比较,目前部署的大多数 PVQMs 都是全参考的,尽管 PVQMs 的范围很广,但它们并不用于直接控制视频处理系统的设计,相反,它们用于事后评估系统来评价算法的效果;换句话说,一个新的压缩或增强算法可以部署一个感知视觉质量评价指标来评估对性能的影响,但不是作为优化过程本身的损失函数。其原因是,大多数感知指标不可微分,由此产生的非线性优化策略可能是不稳定的。本文的思想是使用可微函数卷积神经网络(CNN)对 VMAF 进行建模,由于 CNN 是可微的,这允许使用 VMAF 作为优化增强和压缩算法的损失函数。VMAF是一种流行的开源全参考 PVQM,由于其在各个领域的大规模采用而获得了研究关注。
创新点
我们使用 DNN 架构创建了一个全参考可微分 PVQM,我们比较了一个没有共享权重的完全可训练模型(ProxVQM:图1)和一个利用 VGG 层的部分可训练模式(VGG-ProxVQM(图2)。ProxVQM 可以作为优化任务中损失函数的一部分,如恢复压缩的视频。图3 显示了每个CNN块内的层叠。我们的模型使用从 Youtube 用户生成内容(UGC)数据集中产生的数据进行训练的。这项工作的主要创新之处如下
- 设计了一个 CNN,它包含了 VMAF 中使用的时序信息,从而更准确地预测了 VMAF 值。
- 部署了一个重复使用的 VGG 层的架构,因此利用了潜在的感知特征,由此产生的架构在训练中收敛得更好,也更有效。
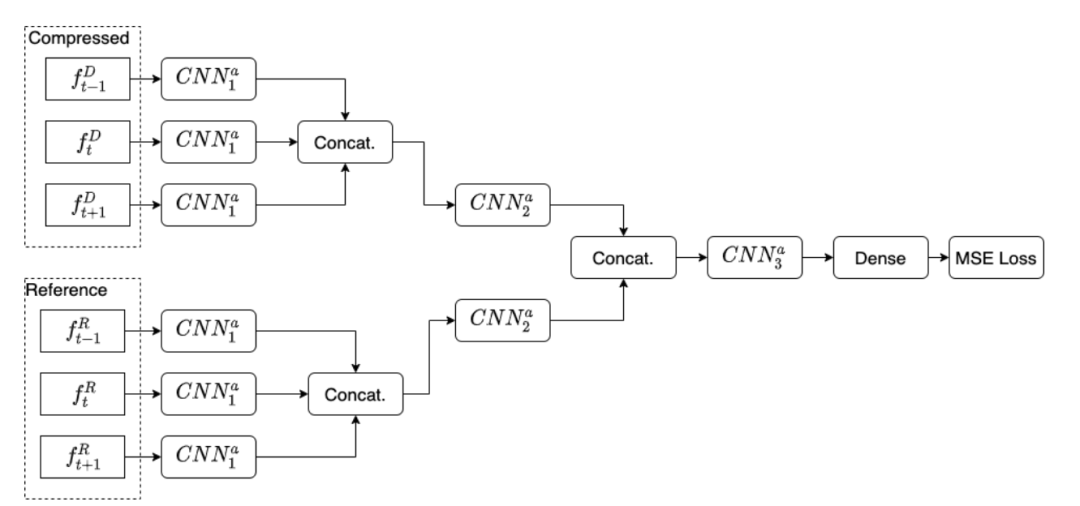
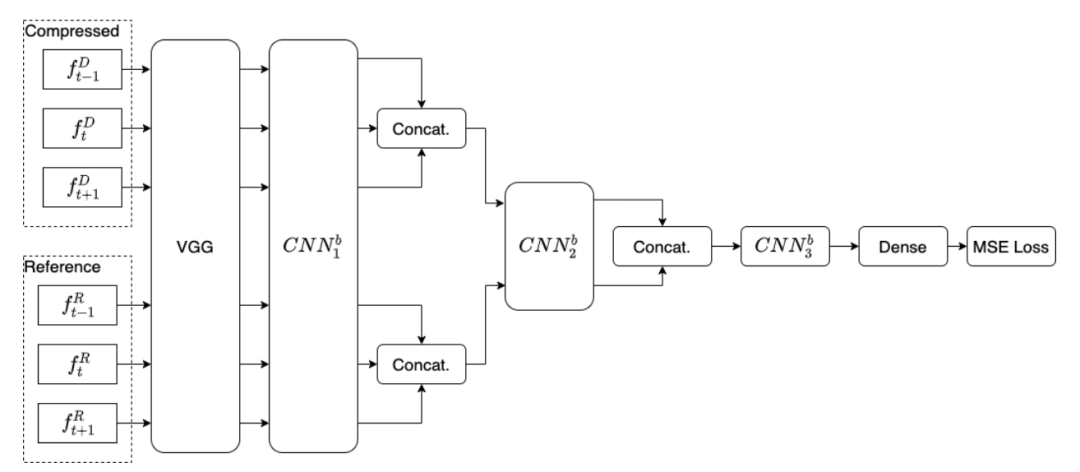
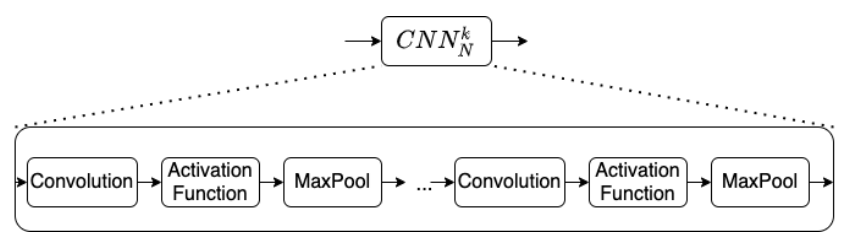
问题公式化

训练集选取
Youtube 的 UGC 数据集被用来作为训练集中的参考视频,实验中只使用了 720p 的分辨率(1280 x 720),产生了 302 个 YUV420 格式的片段。为了产生损伤视频作为训练数据,这些片段使用 H.265 压缩,恒定速率因子(crf)在默认的28和上限的51之间均匀地随机设置,这确保了在整个PVQM范围内产生不同质量的适当剪辑,在这种情况下,PVQM 的输出范围为 0 到 100。
在生成这样的训练数据时,一些质量分数有可能比其他分数出现得更频繁。因此,为了确保训练样本中没有偏见,在每个质量水平上选择相同数量的视频数量是很重要的。为了做到这一点,我们测量了每个片段的 VAMF 平均得分的分布,并在每个直方图中选择 40 个片段来创建最终的数据集。
实验结果
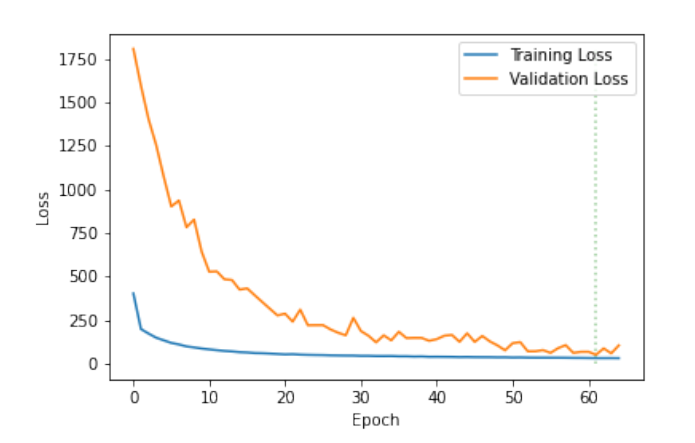
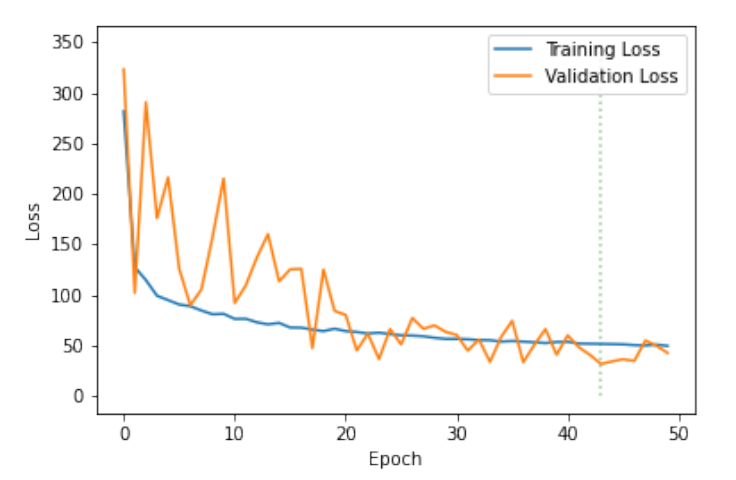
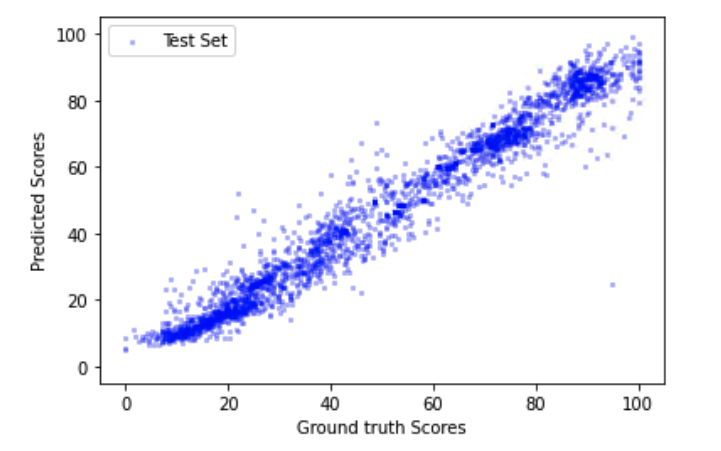
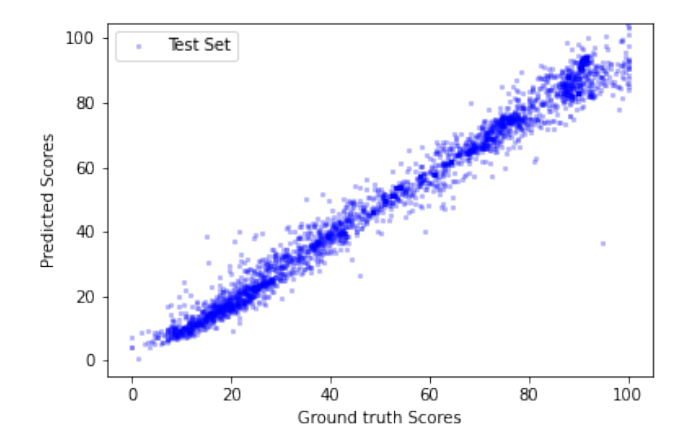
在 4 张 RTX 2080 gpu 上,使用 batchsize 为 8 进行模型训练。图 4 和图 5 显示了训练损失的收敛性,图 6 和图 7 展示了模型预测效果,其中 ProxVQM 获得了 0.982 的 PCC(Pearson’s Correlation Coefficient )和 0.98 的SRCC(Spearmans Rank Correlation Coefficient),而 VGG-ProxVQM 实现了 0.989 的 PCC 和 0.988 的 SRCC。
总结
在视频增强等应用中,感知视觉质量评价指标在自动图像质量优化方面的应用有限,这是因为许多有用的视频视觉质量指标,如VMAF,是复杂的和不可微分的。本文提出使用 CNN 架构来估计 VMAF 的模型利用了时序信息,并获得了很好的效果。一组实际图片的例子如图 8 和图 9 所示。


来源:媒矿工厂第一时间发布最新最有料的媒体技术资讯。倡导极客、创客精神,促进学术界、工业界以及开源社区共享信息、交流干货、发掘价值。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
