
S12决赛尾声,伴随DRX成员们从眼泪到荣耀的升华,技术保障团队的心也松弛下来,逐渐把目光从监控中挪开。一方面分享胜利的喜悦,一方面也为实现了“边喝茶边保障”的目标而高兴。
B站在本次直播为了提升用户体验,开启了送礼特效。以送礼为核心的营收场景是业务主推的方向之一。为此团队的小伙伴们在业务需求繁忙的情况下,同时做了大量的准备和优化。
本文我们聚焦于以写为主的送礼场景,对我们的技术保障思路做个简单的总结。聚焦到一个问题,那就是:高写场景该如何做技术保障?
01 场景简介
为了更好的理解保障目标,我们先简单介绍下营收高写场景的业务。
直播间里的礼物打赏,和电商平台交易非常类似。需要花真金白银购买,一旦花钱要么得到即时的特效反馈,要么得保障用户的利益(自动退款)。简单讲,这是一条对稳定性和一致性有较高要求的链路。
直播营收的业务,简单讲就三句话:
以送礼为核心的交易体系
以打赏消费为基准的身份指标体系
以刺激消费的活动增值体系
用最简单的领域概念来表达:

不管是同步链路,还是异步链路,都是以写为主,在榜单+任务等场景还会有几倍到几十倍不等的写放大。同时对稳定、一致、实时各有强诉求,不管是花了钱没特效,还是榜单加分慢了,都会让用户体验受损。
一旦出现大故障,对业务体系的影响难以估量。有一句调侃很精辟:以读为主的场景,故障恢复后就没事了,营收场景故障恢复后,收尾工作才刚刚开始。
02 技术保障的起点
互联网圈有句话,大部分所谓高并发,都是redis的功劳,不够就加机器,只要能简单横向扩展扩容就行。
对于这种依赖方众多,且强依赖数据库的场景,该如何做技术保障呢?我们知道数据库本身是有状态的,难以动态扩容。
这个问题不太好简单回答,我们需要回到起点,从源起技术保障的地方为思考原点。先想想为什么要做技术保障?
2.1 核心变量
从大型赛事的角度看,核心变量是流量压力。在赛事高峰群情激动时刻,可能爆发远超平时的送礼峰值,一个点的量变,可能引发下游链路全线连锁反应。
那是不是加个强限流就行了呢?还要做啥技术保障。我们知道这当然不行。技术保障第一底线,就是要在预期的流量压力下,保证业务能正常运行。毫无疑问,大型赛事期间,流量压力会远超平时,所以技术保障第一部分是: 提升容量。
2.2 重温墨菲定律
当容量提升到一定程度后,丟一份压测报告,例如能支持1W人同时刻送礼,是不是就够了?
实际上也是不行的,这就涉及技术保障的第二部分:那些可能出问题的地方,当真的出现问题时,我们要让业务保持正常,或有快速恢复的能力。
这也是技术保障最难的地方:
(网络)交换机什么时候出问题
(机房)物理机什么时候故障
(链路)slb/专线/什么时候抖动
(依赖)依赖方什么时候掉链子
(突发)某个意料外的突发情况
这些我们是不知道的,这些可能出问题的地方,随时可能出问题,特别是在送礼这种复杂链路上。一旦运气不好,在赛事直播期间出问题时,第一,我们要前置从理论层面尽量规避问题(强弱依赖),第二,如果无法提前规避,需要能快速恢复。
03 技术保障的方法
分析完了技术保障的源起,接下来我们结合本次S12保障的过程,从上面两个点依次展开。
3.1 容量的提升
保障备量的本质是要能承受住大流量,我们数据库以MySQL为主,我们知道数据库难以动态扩容,不像读场景可以直接扩。当数据库出现瓶颈时,给你机器也没用,只能眼巴巴靠限流先保底。
从技术角度看,强依赖数据库的场景,当要提升容量承受高流量一般两个方法:
1. 预估出可能的量,提前准备好,如果还超预期直接限流。
2. 预估出可能的量,做写异步化,以增加用户耗时换吞吐量,就像银行转帐那样。
基于实际情况,我们按第一个方法进行,准备高于预期的量,属于主观+实际结合。容量提升的过程分为两个阶段,其一是技术优化,其二是压测验证,两个交替进行。
技术优化总结下来,主要是做了这几个点:
资源review
得益于早期分库分表规划,本次只迁移了一部分可能相互影响的MySQL实例,保证核心链路每一组Master独占物理机。
数据库减负
写瓶颈说到底是卡在磁盘IO+CPU,砍掉非必要的读写,或用缓存挡一部分。
复杂度治理
营收交易链路,最早是针对送礼打赏建模,在追求迭代效率的过程中,堆积了不少普遍性的积弊:
业务耦合+写放大。钱包耦合记账能力,本来消费时只写一条流水,但为了xx场景,会写多条对齐财务口径。
扩展困难。结算流水直接对接第三方,当第三方对数据有新诉求时,结算不得不开始关注第三方业务逻辑了。
链路复杂。整个结算流程驱动,由几条支线分别在触发,有需求时改动多,心智负担也很重。
大概的样子如下:
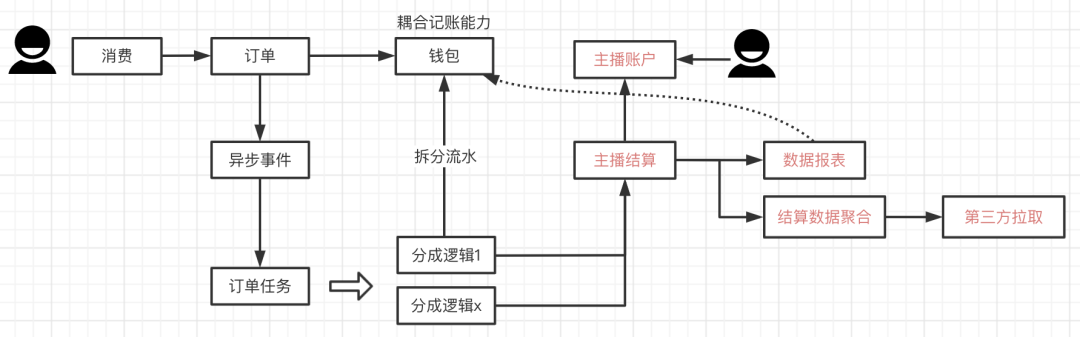
交易体系的演进一直在进行,技术保障过程中高度关注这部分。在S12准备阶段,我们开始灰度新的系统结构,整体如下:

钱包、结算单一职责,消除写放大和业务耦合。
引入清算概念,将记账能力做抽象,整体可扩展。第三方订阅数据,自行处理业务逻辑。
整体链路变成非常清爽的一条直线,各个环节各司其职。
这不仅提升了吞吐能力,也大大简化了技术保障的复杂度。
解决热key
直播场景热key非常普遍,进房很容易将redis CPU被打满。基于高在线房间SDK + 自动探测热点SDK,封装了一套方便的热key解决方案,业务可以基于callback自动将热门数据写入内存。

可横向扩展
送礼业务复杂加上业务狂奔,积攒了很多个定时任务从DB刷数据到内存中,当流量激增时:如果应用扩容,数据库负载变大,如果不扩容应用CPU打满,左右都会崩。
面对S12的流量挑战,我们开发了一套通用刷数据的组件,解除应用规模和数据库压力间的关联,让应用可自由伸缩。
全链路压测
技术优化效果的验收是个麻烦的问题,送礼事件有非常多下游依赖,会直接影响下游业务,稍不注意可能造成以下后果:
一场压测让全年营收KPI提前达成
压测账号霸占各任务、榜单、身份指标等系统
给某主播巨额分成
用户舆情:啥活动没有的账号,居然这么多积分/粉丝?
压测有巨大的风险,但又必须进行。早期的方案很粗暴,搞一套特定的压测账号列表,然后各个场景自行过滤。结果是每次压测都如履薄冰,拉一帮人反复确认,事后还得及时Review。除了边际成本巨高,由于过滤了压测流量,下游链路风险是不清楚的。
鉴于这些痛点,直播从21年开始对全链路压测做了重点投入,基于流量打标,对压测流量从缓存、数据库、消息队列等做镜像隔离,从根本上避免数据污染。目前在业务上也打通了榜单、任务等有实时性要求且明显写放大的核心下游场景。
全链路压测让营收主场景和核心异步场景联动起来,随后结合错误日志、trace链路分析、数据库指标等,我们对整体链路才真正做到了心中有数,也发现了不少在链路瓶颈上的认知盲区。
在对资源、消费速度、链路超时、局部弱点等做了恰当的调整优化后,我们对容量准备基本成竹在胸。
3.2 让不确定变成确定
解决了容量问题后,我们需要对不确定性的点做足够的准备。不确定性的本质是可能出问题的点,从问题倒推我们可以总结为以下几个方面:
1. 潜在的问题发生(二级变量)
2. 依赖方故障
3. 故障下的数据一致性
4. 基础设施故障(容灾)
3.2.1 扼杀潜在变量
写场景的风险主要是数据库,从数据库风险倒推,有两个二级变量,容易被忽略但又危险至极:
慢查询
数据库连接数
之所以叫二级变量,因为它们往往是直接变量衍生而来,这在压测等准备阶段容易被忽略。
慢查询的风险在于,同一条sql可能大部分情况下不会出问题,但当触发某个数据倾斜的场景,往往就是雪崩的开始。而连接数问题,是在流量激增叠加大量扩容时才爆发连锁反应。
这两者属于难发现难制造,但有危险至极的点,不好防治,就得从摇篮中扼杀。为此业务上针对主场景做了几个事:
1. 将慢查询阈值调低,暴露潜在问题,并要求将读流量切换到非主场景依赖的库。
2. 主场景读写数据库必须过DB Proxy,避免扩容时直连导致连接数激增。
从概率上将其限制到最低。
3.2.2 强弱依赖与降级
每一个复杂的业务,其依赖都是方方面面的。从业务视角出发,要保证尽量稳定安全,首要的事情就是:分清楚强弱依赖,分清楚功能的主次,这需要对业务有深入的理解。
对于像部分策略类的弱依赖,我们在调用时,会尽量启用并发,且给予其较短的超时时间,避免拖慢请求,直接降级。
而对于黑名单之类在平常需要,极端情况下可舍弃的次要功能,我们在设计上,可以通过配置实时修改强弱依赖关系,保障时可实时决策降级。
真正麻烦的是强依赖故障,对于偶发性问题,需要给用户端返回符合体验的提示,并通过重试解决问题。当核心下游持续性故障时,需要利用平台基建的能力,得益于B站Invoker多活流量管控平台,可以将故障下游的流量,切到正常的机房,从而实现快速恢复。
3.2.3 数据一致性
送礼、订单、钱包整个链路的一致性通过准实时对账退款+天级别对账来保障,简单讲是最终一致性。
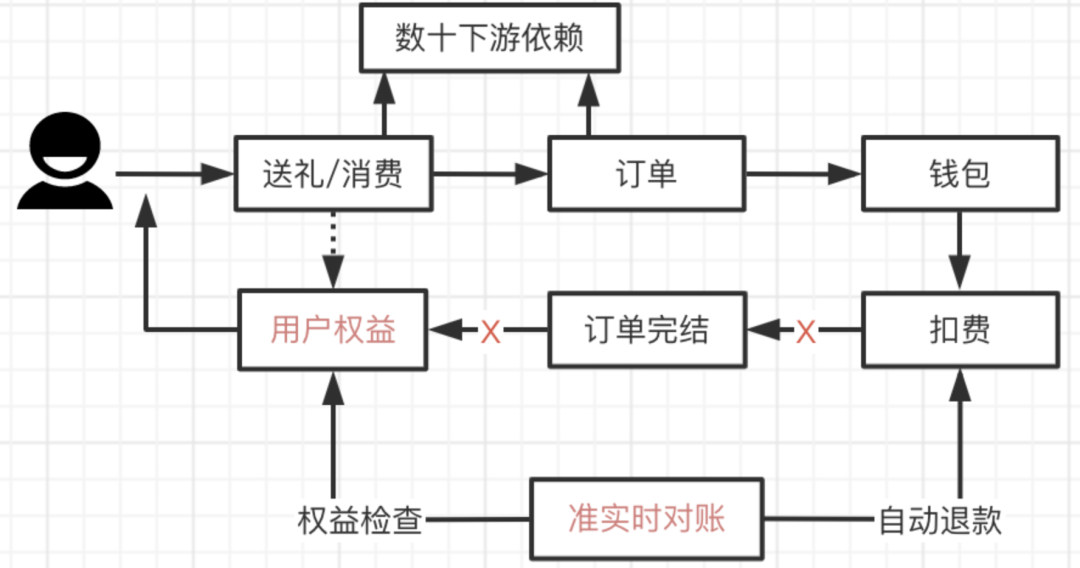
当链路中出现问题是,会出现用户花钱但没获得权益,此时自动退款机制就非常重要。不管是强弱依赖策略验收,还是自动退款策略验证,都是麻烦的事情。
混沌工程在此时就起到了重要的作用,基于B站平台故障注入能力,由测试牵头在特定环节注入故障,可以非常方便地验证强弱依赖应对策略。对于送礼场景,对扣费后的每个流程做故障注入,均应该观察到用户的账号即时退款,确保用户权益。
3.2.4 不可抗拒的灾难
比某个强依赖方持续故障更危险的是基础设施的故障。大的有机房断电,小的情况是SLB等中间层故障,这种属于基本无法预知的情况,一旦出现则是灭顶之灾,所以SRE上也叫容灾。
容灾的唯一方式就是冗余+分散,分散可切割灾难的覆盖面,而冗余可实现快速替代。对于送礼这种核心场景,这是必须考虑的点。
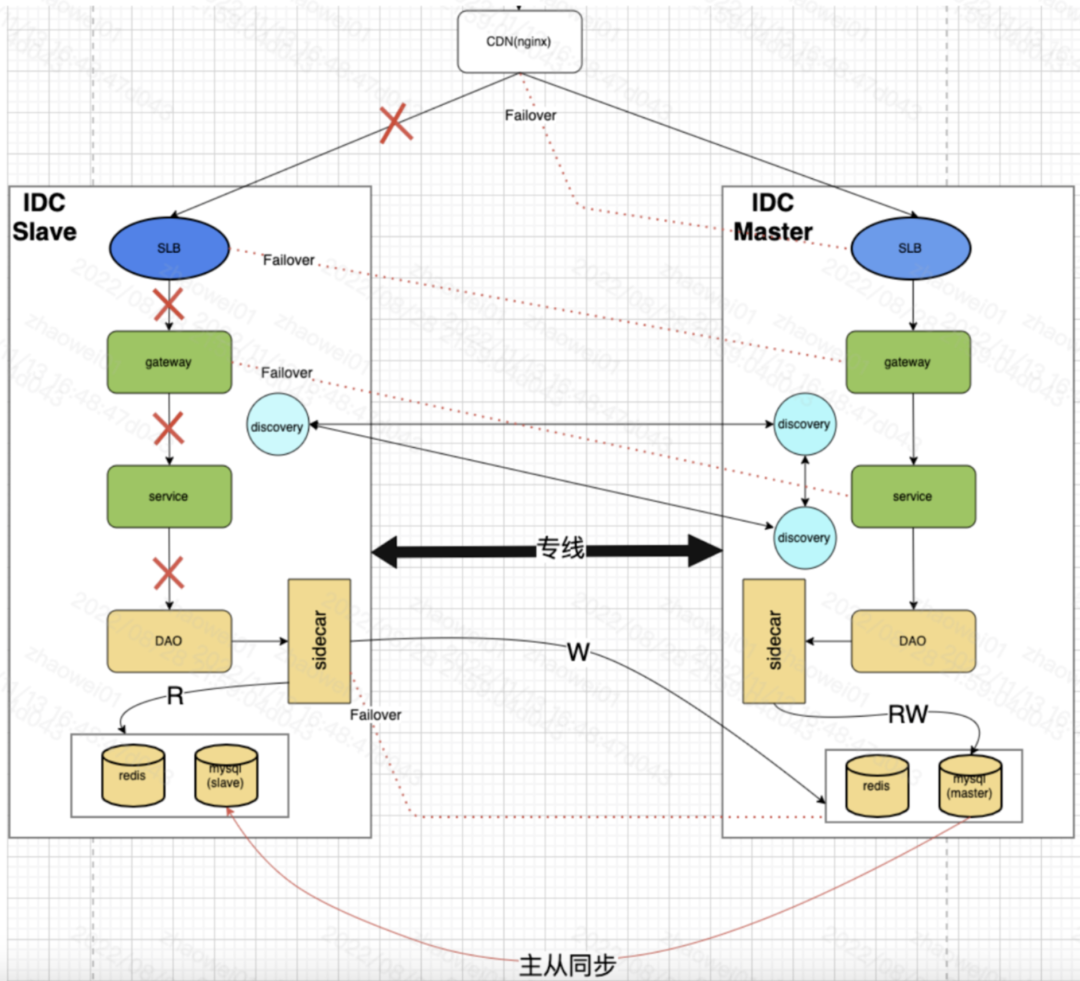
上面是送礼同城双活示意图,同城双活可以简单理解为,流量链路有两个主通道互为灾备,两个主通道共享同一套数据库,数据库通过主从实现高可用,这是单元化的前期阶段。
当流量链路层故障,可以通过流量管控平台摘掉其流量,恢复后再切换回来。当数据库故障时,会自动触发主从切换,实现自恢复,也就是将某个从库提升为新Master接受写流量。
听起来好像已经万事具备了,但对于营收对数据一致性有要求的场景,只做了一半。从业务视角看,要真正实现故障时业务止损,还有两件事件要做:
1. 流量切换演练。包括数据库自动恢复,需要做实际演练。一是验证可行,二是要观察整个过程可能出现的潜在问题。
2. 数据一致性问题。我们知道故障时主从切换是可能丢数据的,具体场景下能不能直接切,丢数据了该怎么应对。
如果这两个问题不先搞清楚,可能故障发生时,某个配置不对导致切不过来,也可能发生严重的资损。这需要结合场景对一致性做细致分析。
对于送礼和订单这种流水性记录,在数据insert后,只会由状态机驱动状态单向流转。当故障触发自动主从切换时,订单会面临两个情况:
订单流水丢失。此时新Master上无某笔订单数据,故障后可通过数据对比做恢复。
订单流水未丢失,但部分状态丢失。状态机单向流转,只要确保每个流程是全局幂等,状态可自动恢复。

上图是一个简单的订单流转流程,当订单数据库主从切换时,右侧的状态可能会丢失。在结合上下游数据时,基本上可以让订单往后正常流转。所以故障时订单数据库可以开启自动切换。
但对于钱包这种强一致场景,上面的推论是不可用的。钱包相当于银行账户,由于数据可能丢失,用户故障前消费100万将钱花光了,故障后如果数据同步丢失,这个用户还可以凭空再消费100万,这就会出现严重资损。所以钱包数据库需要关闭自动主从切换,必须得根据情形由人工判断。
比如具体判断指标有:
数据丢失的规模
故障前有无大额消费
如果判定风险较低,可以立即触发切换,否则只能走数据库快速recovery流程,如果出现反复自动切换,问题会更加复杂。对于这种强一致性的场景,安全的故障切换还有较大演进空间,不管是半同步、单元化,还是分布式强一致性,业务总会推着技术不断往前。
当对可能出现的问题有足够的认知和应对策略,并在协作和流程上形成演练过的SOP后,这部分技术保障才真正准备完成。
04 总结
本文从送礼业务切入,基于S12保障过程对高写业务保障方法做了简单探讨。回头看,影响一场技术保障质量的因素主要有两个方面:
其一,基建的投入。如果没有同城双活、全链路压测、混沌工程、切流平台等等一系列基建上的持续投入,我想大型赛事的保障可能演变成一场纯拼运气的焦虑项目,既难以发现问题,也无法应对风险。
其二。业务的落地。如果不能基于业务的实际特点,对基建能力做恰当的接入,没有从业务可用的目标出发,落地一系列贴近业务的细致准备,当问题发生时,难免陷入磕磕绊绊的蜗牛进度。
这是一场真正基于“实践”的活动,在此为本次保障付出幸苦汗水的同志们表示敬意!
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
