
来源公众号:快手音视频技术
来源链接:https://mp.weixin.qq.com/s/f_HbH1e5e5ZJH_euVurD_A
在春日郊游vlog中,怎样去除路人,精准抠出核心人物?没有专业的PS功底,如何给图片快速换个背景?传统的“一键抠图”模板已经满足不了多元化的创作需求,为了丰富视频编辑创作的原子能力,快手音视频技术团队自研视频自定义抠像解决方案,助力创作者拥有抠取任意目标元素的能力,自由获取个性化素材。


视频自定义抠像技术已成功应用于快影App,创作者通过点击「手动抠像」,实现万物皆可“抠”。在快影App主页的功能入口,智能抠像分为自动和手动两种模式。自动模式可实现一键点击抠图,共有人像、头部、背景及去天空四个模块;而手动抠像创造了更多可能,人像之外,还可以将宠物、美食、植物等任意感兴趣的元素分离出来;在精细化多元操作上,创作者还可以对所需部分多抠或少抠一些,实现真正的“抠图自由”。这项方案已申请十余项专利,并分别在CVPR2021和NeurIPS2021顶会上发表了一篇论文【1, 2】。
01 背景
对于专业创作团队来说,特效制作不仅可以在线下绿幕棚拍,还可以借助强大的AE、PS等专业软件进行后期抠像制作。而对于个人创作者以及非专业团队,既没有合适的场地,也无法短时间快速掌握后期技巧,同时,行业内绿幕抠像算法和人像抠像算法对素材具有一定局限性,前者要求素材是纯色背景,后者则只能抠取人像。
面对这些痛点,快手音视频技术团队自研了视频自定义抠像技术,无需绿幕场景,也不需要借助后期软件,有效降低了创作门槛,将专业的创作能力大众化,让视频创作变得更简单、更好玩 。
02 视频自定义抠像解决方案总览
快手视频自定义抠像技术可以实现对图片、视频中任意感兴趣物体的分割提取,它主要涵盖了三类算法:前景分割、交互式分割和视频物体分割。我们将整套技术方案划分为两种运行模式——单帧图片模式和视频帧模式,整体流程如下图1所示。
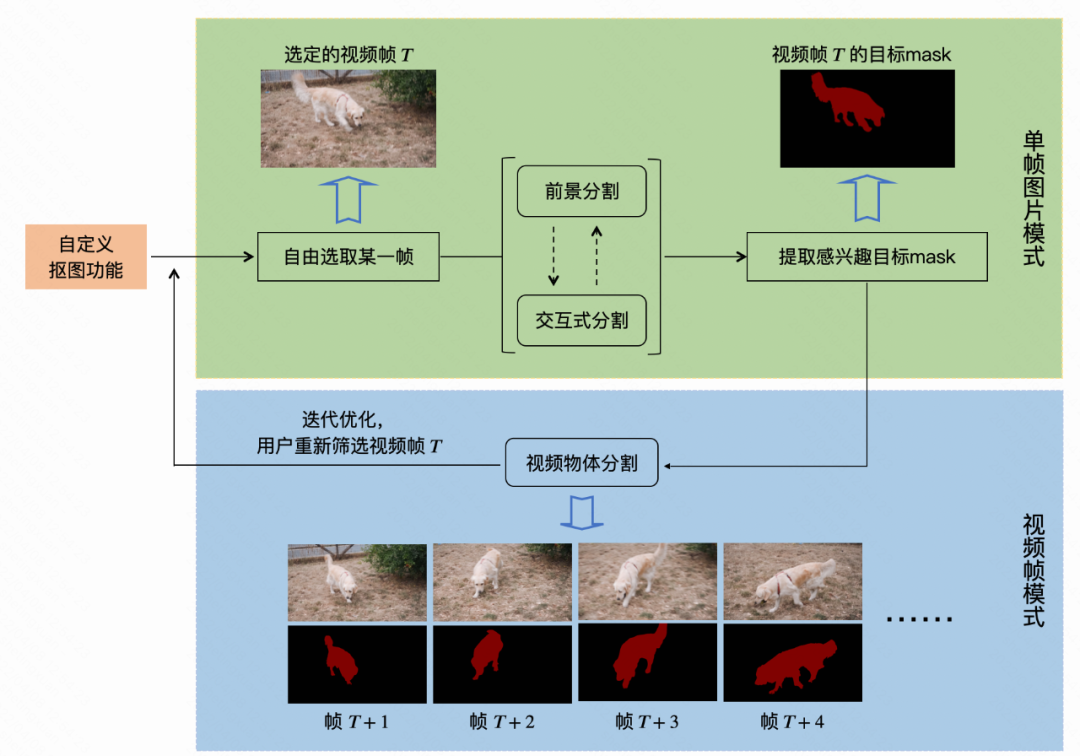
03 单帧图片模式
在单帧图片模式中,用户加载视频(或图片)文件,进入自定义抠像功能;然后由用户挑选出某一图片帧T,记为模板帧,通过前景分割和交互式分割算法提取感兴趣物体,获得目标mask。其中前景分割算法负责智能傻瓜式预提取感兴趣物体mask,然而,此时得到的物体mask可能存在细节上的缺失或者过分割,甚至并不是用户要提取的感兴趣目标,面对这一问题,交互式分割可以进一步由用户参与进来,按照用户心中所想,更完美地提取目标物体mask。
前景分割前景分割用来智能分割出一张图片帧中的前景物体mask, 前景物体不限类别,可以是人、动物、植物、美食、建筑和家具等。如图2所示,列出了部分场景的分割结果。

虽然深度学习在该领域取得了重大成功,但由于学术界的benchmark数据集规模有限,并不能覆盖到实际业务生产中多种场景和类别需求。为此,我们从数据集的两个方面着手,一个是数据量,一个是标注质量。
数据量
在实际生产应用中,我们积累了海量的场景业务数据,类别丰富,且场景复杂多样,比如不同的天气、光照、角度、地域、遮挡程度和图片成像质量等。因此,根据任务的需要,我们制定了一系列规则,获取和筛选出所需的训练数据;然后,我们通过半自动化标注的方式产生训练所需的伪标签。
首先,通过目前已积累的有限的有标注的数据,优化训练多个高精度的算法模型;然后,利用线性加和、投票机制等手段进行模型Ensemble,通过大量实验确定最佳的Ensemble策略,来获得高精度的算法模型效果;最后,我们利用该Ensemble的模型为这些数据产生伪标签。
另一种方式,我们通过模型训练时的数据增强与合成方式 用有限的数据针对性地模拟真实的业务应用场景,具体的方式包括平移旋转、仿射变幻、样板条插值、色调变换、形态学处理和图像合成等方式。
标注质量
对于前景分割任务,理想的状态是所有数据标注的前景mask都是精确且没有歧义的。然而,在实际应用场景中,更多的情况是训练数据集标注精度参差不齐,原因有以下三个方面:
- 数据本身具有歧义,不同的标注人员会标注出不同的前景mask。
- 出现数据标注错的情况。
- 利用半自动化标注的训练数据产生的伪标签会存在大量噪音,包括漏分割、过分割、错分割以及边缘锯齿等问题。
这样的状态会让模型在学习过程中产生严重的混淆,导致不能学习到一个更好的算法模型。为了解决以上问题,除了不断提升半自动化标注的精度,我们提出了一系列应对方式,比如提出应对数据标注精度参差不齐的组权重划分训练方法,对不同标注精度的数据区别对待,弱化标注噪音的影响;同时,在网络设计上,利用动态实例感知结构让网络可以隐式地学习数据集中的歧义信息,以更有效的提取歧义标注数据集中的有效信息,提高模型学习过程中的容错率,最大化模型算法性能。
交互式分割
交互式分割是指在用户引导下,分割出用户想要分割出的物体,具体来说,旨在以最少的用户交互次数,快速准确地完成兴趣目标物体的分割提取。如下图3中,展示了交互式分割输入输出示例。

左上:一个交互式深度学习模型的输入是待分割RGB图片
右上:输出用户待分割的结果mask
左下:正交互笔触图
右下:负交互笔触图
现有的基于深度学习的交互式分割技术依托的交互方式主要包括点击(click)和涂抹(scribble)两种。每种交互方式下区分正交互和负交互,正交互是指在用户感兴趣区域进行的scribble(或 click),负交互是指在背景误分割区域进行的scribble(或 click)。在一次交互任务中,为了获得满意的结果,需要进行多次正负交互过程;正负交互笔触图可以有多种表达形式,考虑到移动端算力和资源优先,我们将其简化,如图3中第二行所示(涂抹的位置设置为255, 其他区域为0)。以往的算法每一次交互过程中送入网络的正负交互笔触图是本次作业和之前所有的交互共同构成的;这种方式下,如果中间回合,用户出现了交互错误,那么会直接干扰最终分割结果的生成,容错率较小。
因此,我们提出了一种基于自适应局部动态裁剪的交互式分割系统,该系统基于自适应局部动态裁剪的方式,在每次交互中,算法会根据用户scribble的范围自适应的对图像进行局部裁剪,然后再送入交互式分割模型以生成用户感兴趣目标分割mask;而且,每回合交互分割网络只处理当前回合用户产生的scribble,也就说每回合的交互是相互独立的,这种做法可以提升算法容错率,不会因为用户中间交互失误而导致难以分割出感兴趣目标。
简介如下:记i为当前交互回合,第i回合的交互分割结果记为Mi。第i回合的输入由当前回合的用户交互Rpi和Rni,前一回合的分割结果Mi-1及输入图像IRGB 构成。
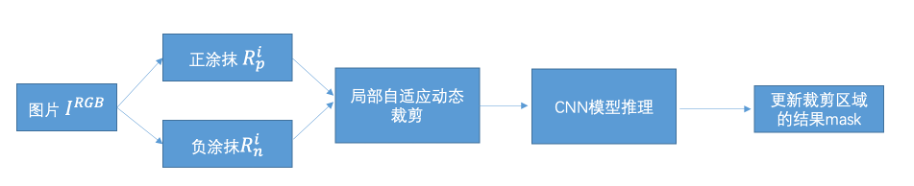
推理流程如图4所示,输入图片IRGB,对每一交互回合,用户会根据当前分割情况进行一种涂抹,正涂抹Rpi或者负涂抹Rni,然后根据用户涂抹的范围进行局部自适应裁剪,然后将裁剪的区域送入交互式分割CNN模型,进行模型推理,输出该裁剪区域的分割结果mask,并更新上一回合得到的分割结果mask。下面将分别介绍正负涂抹、局部自适应动态裁剪和CNN模型推理部分。
正负涂抹

左图为原图和用户做的正(负)涂抹
右图为生成的正(负)涂抹的表达形式
如图5所示,在用户进行涂抹之后,我们生成图中右边对应的图片mask表达形式,图中白色曲线(像素值为255)代表用户在原图片中交互的轨迹,白色曲线的宽度可根据具体产品的应用形式进行超参数的调节, 其余非用户交互轨迹的部分都是黑色(像素值为0)。
局部自适应动态裁剪
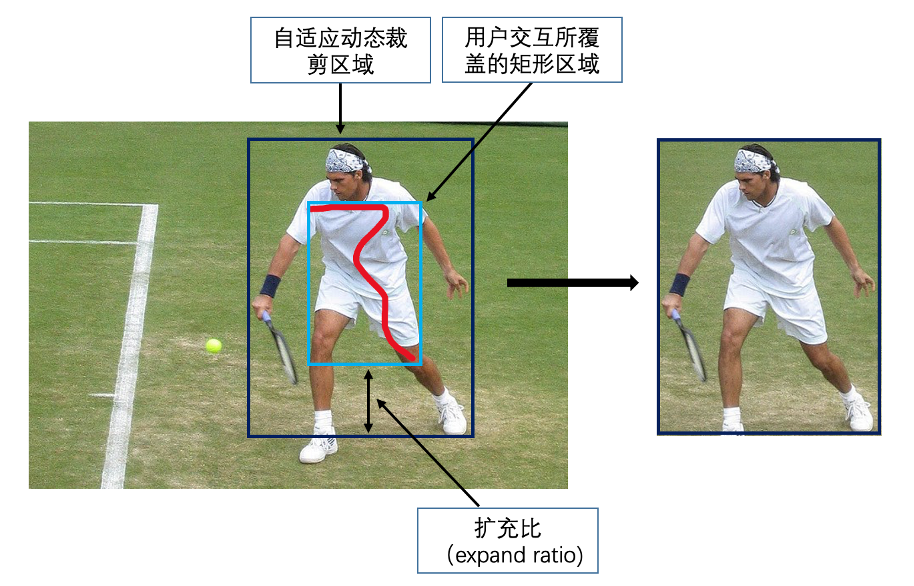
如图6所示,我们首先根据用户交互轨迹得出其所覆盖的最小包围矩形区域,记为Rmin,然后长宽各自以一个固定的扩充比(expand ratio,记为ER)进行扩充,得到自适应动态裁剪区域,记为Rexpand,然后将图片该区域送入后续CNN模型算法处理中。expand ratio的选择和两个参数有关,一个是Rmin占据原图片的范围,占据的范围越大,expand ratio越小,设Area(Rmin)代表 Rmin的面积,Area(IRGB)代表原图的面积,占据的范围表示为Area(Rmin)/ Area(IRGB) ;另一个参数是用户在交互过程中放大原图片的倍数z,用户放大倍数越大,则expand ratio越小,因此设置expand ratio的分段函数如下:
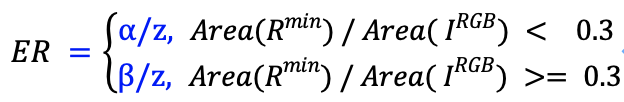
CNN模型推理
该过程将上述过程中裁剪的图片resize到固定区域,然后和对应的上一回合结果mask、 正(负)交互mask一同送入已训练完成的CNN推理模型中,然后输出对应裁剪区域新的结果mask。训练数据可以和前景分割的数据共用。
04 视频帧模式
在获取模板帧以及模板帧上对应的目标物体后, 我们利用视频物体分割算法实时智能提取后续帧中的目标物体mask;提取完成后,用户可以根据当前的提取效果,继续在后续帧中筛选新的模板帧,进入单帧图片模式,修正目标物体mask,然后再运行视频帧模式,如此迭代优化,直至完成视频流中目标物体的mask提取,达到用户满意的效果。最后,我们再根据具体应用需求,将视频和目标物体mask进行渲染上屏,呈现给用户想要的效果。
整套系统中最核心的问题是如何准确地分割出视频流中感兴趣目标物体区域,以及如何让不同终端机型的用户都能够流畅地使用,并获得满意的效果。
视频物体分割
视频物体分割算法是指给定某视频序列初始帧中的目标物体mask,在后续帧中预测出该目标物体的像素级别的分割掩膜mask结果。下面,我们将从网络结构、训练方式和时序稳定性三方面来进一步介绍。
网络结构
模型网络细节可参考MIVOS【1】算法中的Propagation Module部分。
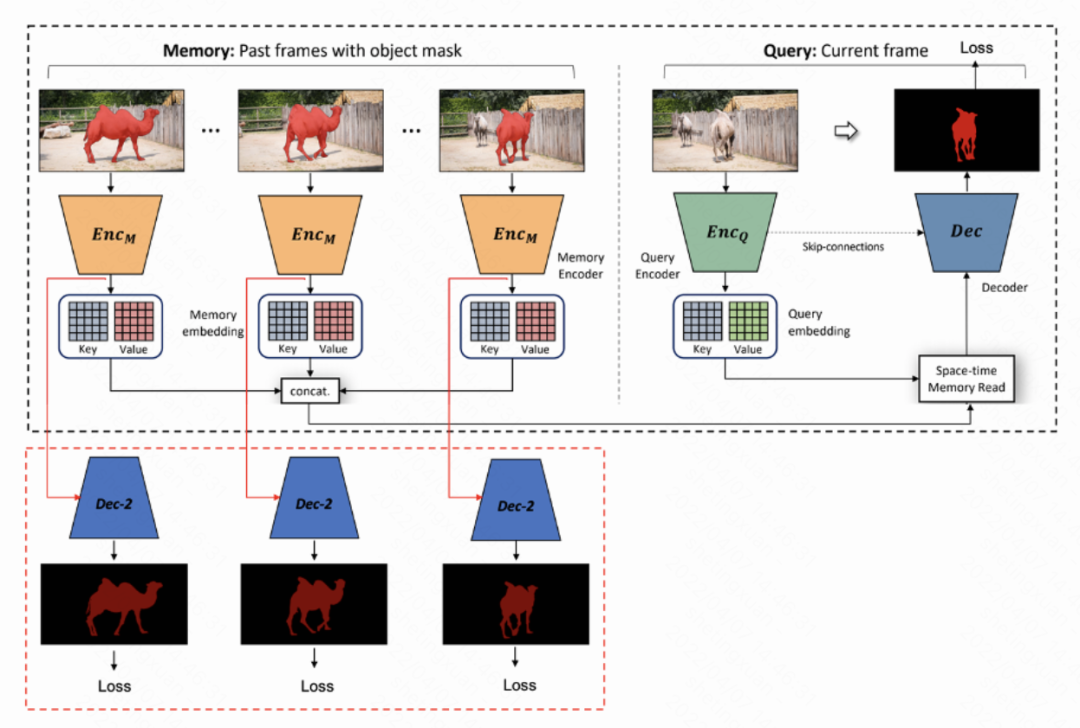
整体架构简介如图7所示,将视频流中前面的图片帧和其对应的目标掩膜mask保存在一个external memory bank中,当预测当前帧目标的mask时,首先从memory bank中选出若干帧(记为记忆帧)及其mask输入到Memory Encoder中,得到对应的key和value特征;然后将当前帧输入到Query Decoder中得到当前帧图片的key和value深度特征。随后,将Memory Encoder的key和Query Decoder得到的key进行内积运算以计算相似度,相当于一种时空的注意力机制,为不同时间和区域的value分配权重。将这个相似度图和Memory Encoder中的Value相乘,将得到的结果和Query Decoder的value进行拼接,送入最后的Decoder网络中进行mask的还原预测和训练时计算损失函数。同时,如图7中红色虚线框所示,我们增加了针对EncM的辅助decoder网络,提升Memory Encoder对目标物体和背景的辨识能力。注意该辅助结构只在训练时存在,当测试时删掉该部分即可,不会引入额外的计算量。
训练方式
由于视频物体分割数据集的标注成本更高,因此我们使用了两阶段训练方法;由于单纯的图片分割数据集更容易获取,因此第一阶段用图片分割数据集,通过仿射变换、color jitter、随机裁剪、旋转等数据增强方法,将单张图片及其掩膜mask手动生成k(默认k=3)张变换后的图片和其掩膜mask,从而模拟生成为N帧的视频物体分割数据集,用作训练,如下图8所示;同时利用图像处理相关算法,区分出不同的instance,如下图9所示;在第一阶段训练完毕后,再将生成的算法模型在少量的视频物体分割标注数据集上训练,得出最终的算法模型。这种方法可以充分利用海量的单张图片分割数据集,极大地提高算法的性能,缩短开发周期,满足实际业务需求。


左1:原图片
左2:其对应的伪标签mask
左3和左4:通过图像处理方法生成的不同instance id的伪标签mask
时序稳定性
在实际场景中,我们发现视频帧之间会出现闪烁和分割不稳定的现象,影响用户体验。针对这种情况,我们利用了一种轻量实时基于相邻帧分割结果的时序信息融合方案,可以在基本不增加运算量和耗时的情况下显著提升视频目标分割结果的稳定性,减少闪烁情况;同时,我们也通过对局部连续的分割结果进行后处理平滑,进一步增加分割结果稳定性。更多关于网络训练和测试的方法可参考《CVPR2021系列(五)—— 解耦模块化交互式视频目标分割算法(MIVOS)》。
05 上线部署
视频自定义抠像解决方案基本覆盖了市场上安卓、IOS移动端的不同机型。然而,不同机型间的算力和资源差异化明显,为了能够让不同机型的用户都获得最佳使用体验,我们共划分了12个机型档位,量身定制不同档位的算法模型,并将其分发,保证不同机型下算法的效率和画质结果。
如何体验
打开快影App,点击「开始剪辑」,选取素材;
点击「剪辑」,选择「智能抠像」,
选取「手动」,即可抠像。
上快手App,搜索 「快影手动抠像」
附录
[1] Ho Kei Cheng, Yu-Wing Tai, and Chi-Keung Tang. Modular interactive video object segmentation:
Interaction-to-mask, propagation and difference-aware fusion. In CVPR, 2021.
[2] Ho Kei Cheng, Yu-Wing Tai, and Chi-Keung Tang. Rethinking space-time networks with improved memory coverage for efficient video object segmentation. In NIPS, 2021.
*本文中涉及影视作品及图片截图仅作效果演示。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。