
大型语言模型 LLM 在各种文本和多模态任务中展现出卓越的性能。然而,许多应用,例如文档和视频理解、上下文学习以及推理时间扩展,都需要能够处理和推理长序列的标记。LLM 有限的上下文窗口在这些情况下构成了重大挑战,因为分散在长文档中的关键信息可能会被忽略。模型在处理海量文档或视频时,往往会错过关键信息,超出其固定上下文窗口的范围。这种限制使得我们需要一种能够高效处理超长上下文,且不会牺牲标准任务性能的模型。
现有的长上下文语言模型的上下文扩展策略分为三类:精确注意力方法、近似注意力方法和引入附加模块的方法。位置插值、NTK感知、动态NTK、YaRN和CLEX等方法通过重新设计位置嵌入来增强注意力机制。最近的进展包括GPT-4o、Gemini和Claude等模型,它们支持包含数十万个token的广泛上下文窗口,但它们的闭源特性限制了可复现性。像ProLong这样的开源项目使用了NTK感知扩展,但计算成本高昂,而Gradient则使用了包含标准任务执行的持续预训练。
来自UIUC和NVIDIA的研究人员提出了一种高效的训练方案,用于从对齐指令模型构建超长上下文LLM,将上下文长度的界限从128K扩展到1M、2M和4M个token。该方法利用高效的持续预训练策略来扩展上下文窗口,同时通过指令调整来保持指令跟随和推理能力。此外,他们的 UltraLong-8B 模型在各种长上下文基准测试中均取得了最佳性能。采用此方法训练的模型在标准基准测试中保持了极具竞争力的性能,并在长上下文和短上下文任务中展现出均衡的提升。该研究对关键的设计选择进行了深入分析,并重点强调了扩展策略和数据组合的影响。
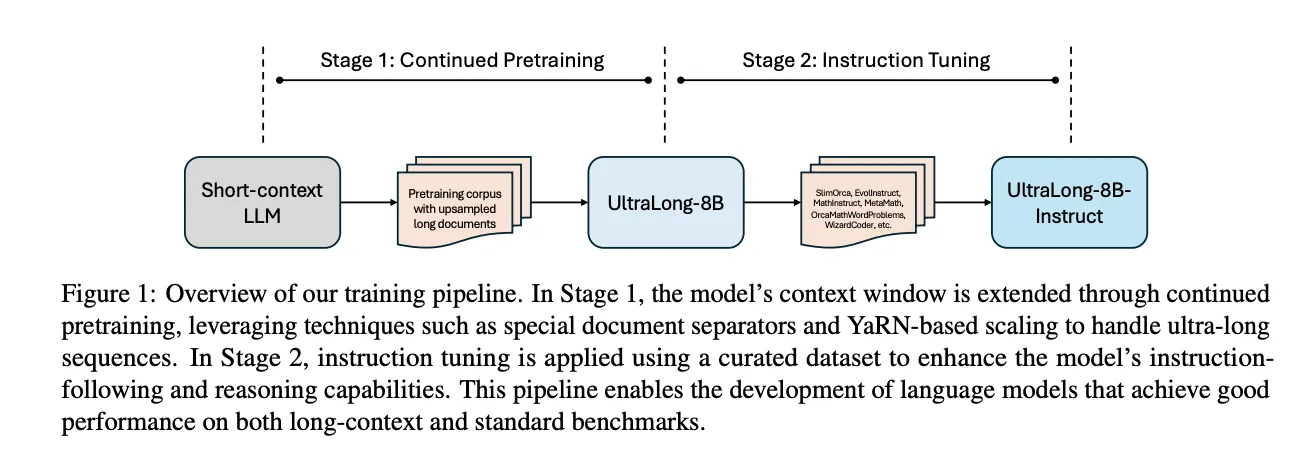
所提出的方法包含两个关键阶段:持续预训练和指令调整。这两个阶段共同作用,能够有效处理超长输入,同时保持跨任务的强大性能。上下文扩展采用基于 YaRN 的缩放方法,其超参数固定为 α = 1 和 β = 4,而非基于 NTK 的缩放策略。缩放因子根据目标上下文长度计算,并对 RoPE 嵌入采用更大的缩放因子,以适应扩展序列并减轻最大长度下的性能下降。研究人员对涵盖通用、数学和代码领域的高质量 SFT 数据集进行子采样以获取训练数据,并进一步利用 GPT-4o 和 GPT-4o-mini 来优化响应并执行严格的数据净化。
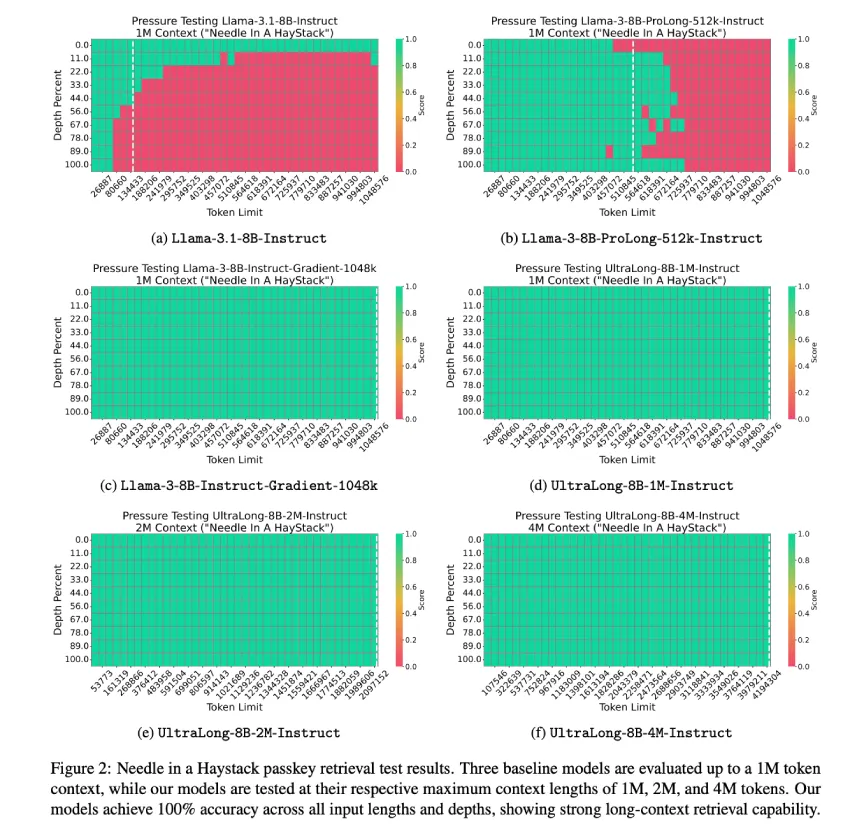
在 Haystack 密码检索测试 Needle 中,所提出的模型展现出卓越的长上下文检索能力。Llama-3-8B-Instruct-Gradient-1048k 等基准模型通过了测试,但 Llama3.1-8B-Instruct 和 Llama-3-8B-ProLong-512k-Instruct 出现了错误。相比之下,UltraLong 模型在所有输入长度和深度上均达到了 100% 的准确率,展现出强大的检索能力。UltraLong 在 RULER 测试中,对于高达 512K 和 1M 个 token 的输入取得了最高平均分数,在 LV-Eval 测试中,对于 128K 和 256K 个 token 长度取得了最高的 F1 分数,并在 InfiniteBench 测试中获得了最佳性能。此外,这些模型在通用、数学和代码领域保持了强劲的性能,平均得分分别为 62.47、61.06 和 60.95,超过了基础模型的 61.45。
本研究论文介绍了一种高效且系统的超长上下文语言模型训练方法,将上下文窗口扩展至 1M、2M 和 4M 个 token,同时在标准基准测试中保持竞争性性能。该方法将高效的持续预训练与指令调优相结合,以增强长上下文理解和指令跟踪能力。然而,该方法在指令调优阶段仅关注指令数据集上的 SFT,而未探索强化学习或偏好优化。此外,它也没有解决安全对齐问题。未来的研究包括集成安全对齐机制并探索高级调优策略,以进一步提升性能和可信度。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/57383.html
