
刚刚,腾讯天琴实验室在官微宣布 lyraDiff 全面开源,以下为全文内容。
还在忍受原生Stable Diffusion与FLUX等文生图模型的龟速推理和显存与成本焦虑?第三方加速方案要么引入编译耗时,要么牺牲生成效果?
lyraDiff全面开源——依托天琴实验室MUSELight大模型加速框架,支持Diffusers生态无损切换,推理速度提升最高6.1x, 像素级对齐原版输出,开发者无需妥协!
目前已支持SD1.5/SDXL/FLUX/S3Diff 等多种图像生成/超分模型,以及img2img、ControlNet、LoRA、IP-Adapter等多种常用pipeline,详情可访问git仓,丝滑运行属于你的lyraDiff。
项目Github:https://github.com/TMElyralab/lyraDiff

为何选择lyraDiff?
01 极速推理天花板
lyraDiff最大的卖点,就是“快”。该框架采用了精度量化、算子融合、访存优化等多种加速手段,在提高推理速度的同时,保证了出图效果的高精度对齐,以及各种插件的无缝切换,打造文生图领域的独家无损加速黑科技,让diffusion模型突破物理算力限制,有效降低生图成本。
此外,其他加速框架在推理耗时外,还有运行时编译耗时,此过程通常需要几分钟,且编译过程困难,用户不友好。lyraDiff 则去除了运行时重新编译开销,完美适配动态尺寸的模型输入。
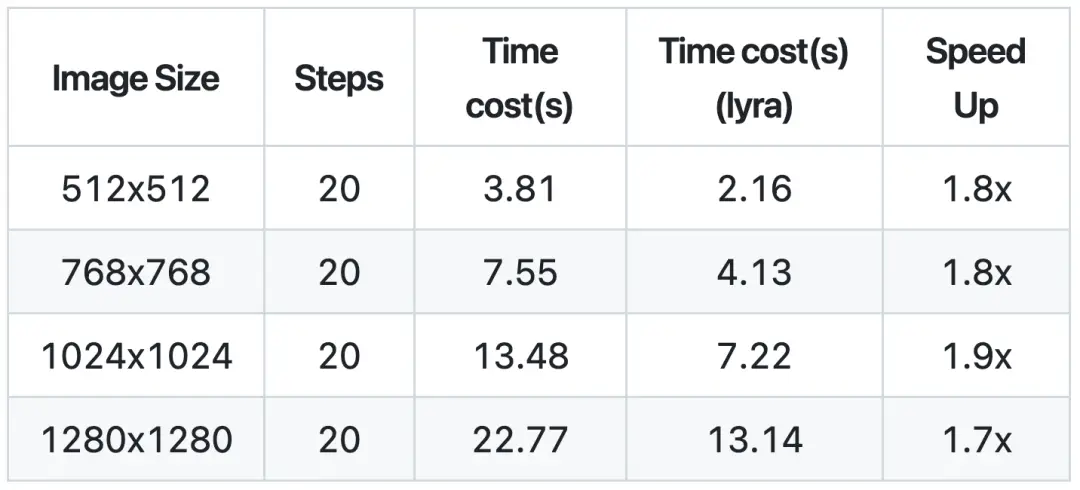
SD1.5模型推理(A100机器,20步推理),512*512的图片生成仅需耗时0.32秒,1024*1024的图片生成仅需耗时1.38秒。相比原生Diffusers,在这两个尺寸上的生成耗时(0.67秒,2.98秒),速度提升超过100%。
同时,在SDXL与FLUX模型上速度提升也十分可观。虽然采用了int8、fp8等量化策略加速,但lyraDiff 做到了”鱼与熊掌兼得”的突破,其出图效果可与Diffusers原生版本在像素级别上一致,而且可以支持各种例如LoRA,ControlNet等插件的快速切换。具体样例可参考下图:

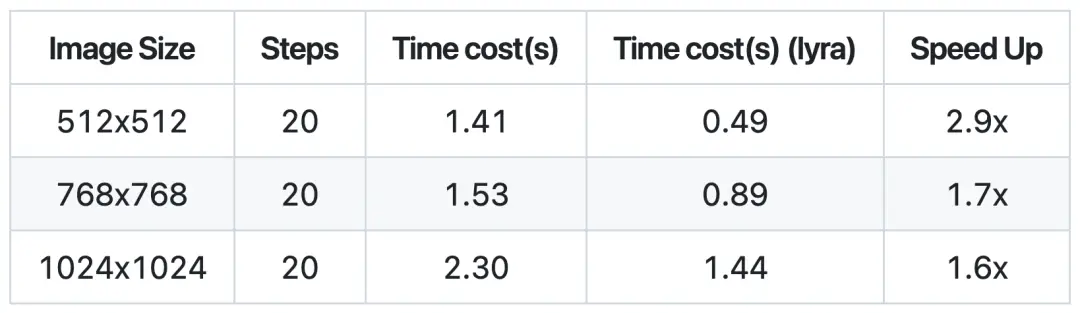
在当前效果最优的开源生图模型FLUX上,lyraDiff结合fp8精度优化后,在保证出图精度一致的前提下,速度提升近90%,极大缓解了FLUX模型应用耗时长的问题。因此在规模化生成时,lyraDiff的无损加速既能保证图片效果不打折扣,还能大幅度降低应用成本。
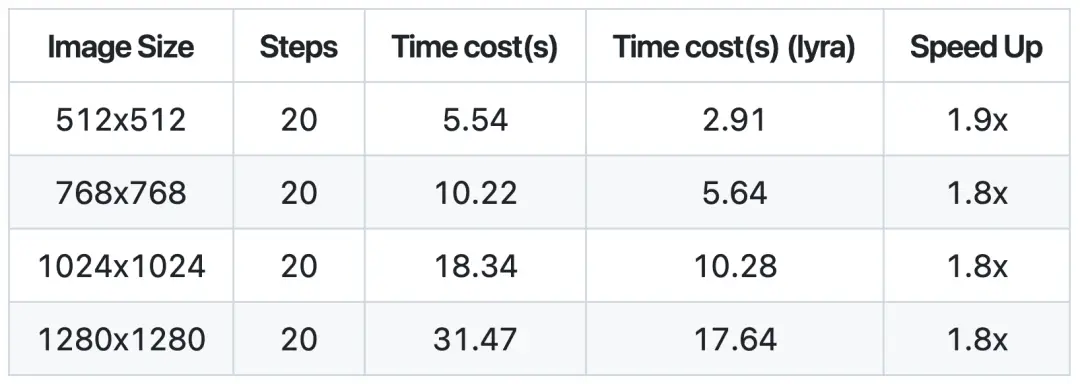
另外,除了主流的生图模型,画图耗时较长也是超分模型的主要应用瓶颈,尤其是大尺寸图片超分的加速需求更为迫切。针对这个业务场景,lyraDiff支持超分模型S3Diff,且在优化后的模型推理速度达到最高6.1倍提升!
02 工业级开箱即用
lyraDiff支持模型覆盖SD1.5、SDXL、FLUX、S3Diff,且StableDiffusion模型中的主流pipeline,如ControlNet/LoRA/IP-Adapter均能即插即用。
Diffusers老用户切换成本极低,仅需安装lyraDiff仓库后,从lyraDiff库中import需要的pipeline,用于替换Diffusers原生的函数,后续模型加载、函数调用、参数传入等结构均可无缝对接Diffusers。
以FLUX模型使用为例,调用代码示例:
import torch
from diffusers import FluxPipeline
import os
from lyradiff.lyradiff_model.lyradiff_flux_transformer_model_v2 import LyraDiffFluxTransformer2DModelV2
from lyradiff.lyradiff_model.lyradiff_utils import LyraQuantLevel
model_path = "/path/to/lyraDiff-FLUX.1-dev/"
quant_level = LyraQuantLevel.NONE
transformer_model = LyraDiffFluxTransformer2DModelV2(quant_level=quant_level)
transformer_model.load_from_diffusers_model(os.path.join(model_path, "transformer"))
model = FluxPipeline.from_pretrained(model_path, transformer=None, torch_dtype=torch.bfloat16).to("cuda")
model.transformer = transformer_model
# Image Gen
image = model("Female furry Pixie with text hello world",
height=1024,
width=1024,
guidance_scale=3.5,
num_inference_steps=20,
max_sequence_length=512,
generator=torch.Generator("cuda").manual_seed(123)
).images[0]
image.save("flux.1-dev.png")03 实时服务神器
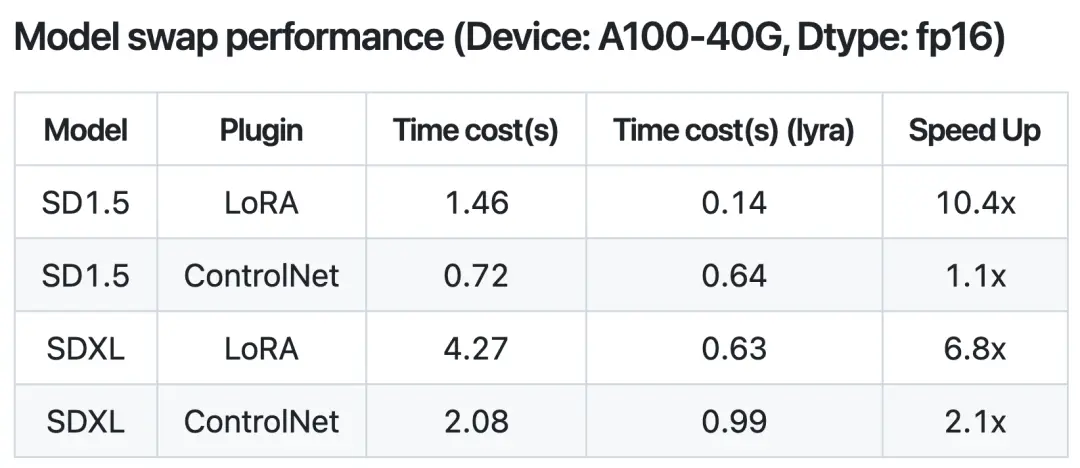
在文生图模型的实际应用场景,模型服务经常有实时切换LoRA模型与ControlNet模型的需求,以应对不同的画图请求,我们称此为热插拔需求。
而绝大部图编译加速引擎是不支持模型热插拔的,意味着模型一旦部署上线,只能使用固定的LoRA或ControlNet,不可实时切换。而原生的Diffusers进行模型热插拔也需要较长的耗时(从磁盘读取模型)。
对此,lyraDiff不仅能支持模型热插拔,更可以通过缓存的方式对减少热插拔过程耗时,提速近10倍,几乎做到无缝切换模型,从而优化用户使用体验。
欢迎共建lyraDiff
我们始终相信,真正的技术突破源自开放的力量。lyraDiff开源仓库已提供快速接入模板(查看GitHub示例),现诚邀全球开发者共同打造最前沿的AI生图加速生态。
当前使用MIT license,个人用户可自由使用、修改、分发代码,企业用户也可在合规前提下自由集成至商业产品。
希望lyraDiff能帮助开发者解决应用痛点,真正助力于社区用户实现AI生图的体验与成本优化。
欢迎各位使用者立即访问 GitHub – lyraDiff,加入共建!
你的一个PR可能改变千万开发者的工作方式!
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
