
近似最近邻搜索 (ANNS) 是一种基本的向量搜索技术,可以有效地识别高维向量空间中的相似项。传统上,ANNS 一直是检索引擎和推荐系统的骨干,但它很难跟上采用更高维嵌入和更大数据集的现代 Transformer 架构的步伐。与由于其无状态性质而可以水平扩展的深度学习系统不同,ANNS 仍然是集中式的,从而造成了严重的单机吞吐量瓶颈。使用 1 亿级数据集进行的经验测试表明,即使是最先进的 CPU 实现的分层可导航小世界 (HNSW) 算法也无法随着向量维度的增加而保持足够的性能。
先前对大规模 ANNS 的研究探索了两种优化路径:索引结构改进和硬件加速。倒置多索引 (IMI) 通过多码本量化增强了空间分区,而 PQFastScan 通过 SIMD 和缓存感知优化提高了性能。DiskANN 和 SPANN 为十亿级数据集引入了基于磁盘的索引,通过不同的方法解决了内存层次结构的挑战。SONG 和 CAGRA 通过 GPU 并行化实现了令人印象深刻的加速,但仍然受到 GPU 内存容量的限制。BANG 通过混合 CPU-GPU 处理来处理十亿级数据集,但缺乏关键的 CPU 基线比较。这些方法经常牺牲兼容性、准确性或需要专门的硬件。
香港中文大学、感知与交互智能中心和华为技术理论实验室的研究人员提出了 PilotANN,这是一种混合 CPU-GPU 系统,旨在克服现有 ANNS 实现的局限性。PilotANN 解决了以下挑战:仅使用 CPU 的实现难以满足计算需求,而仅使用 GPU 的解决方案受到内存容量有限的限制。它通过利用 CPU 的丰富 RAM 和 GPU 的并行处理能力解决了这个问题。此外,它采用了三阶段图遍历过程、使用降维向量的 GPU 加速子图遍历、CPU 细化和使用完整向量的精确搜索。
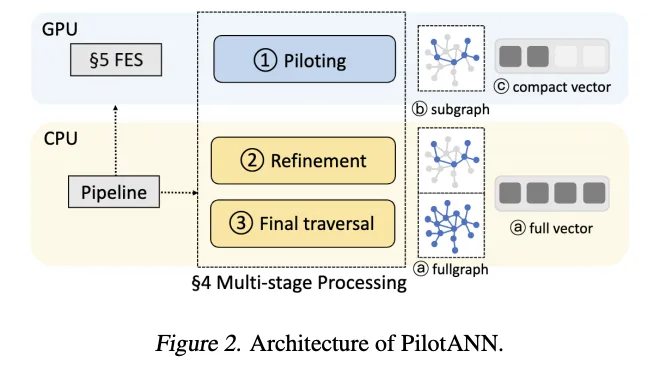
PilotANN 通过“分阶段数据就绪处理”范式从根本上重新构想了向量搜索过程。它最大限度地减少了跨处理阶段的数据移动,而不是遵循传统的“移动数据进行计算”模型。它还包括三个阶段:使用子图和降维向量进行 GPU 试点、使用全向量子图进行残差细化以及使用全图和完整向量进行最终遍历。该设计仅使用单个商用 GPU 即可显示出成本效益,同时可以跨向量维度和图形复杂性进行有效扩展。数据传输开销最小化为初始查询向量移动到 GPU 以及 GPU 试点后返回 CPU 的小候选集。
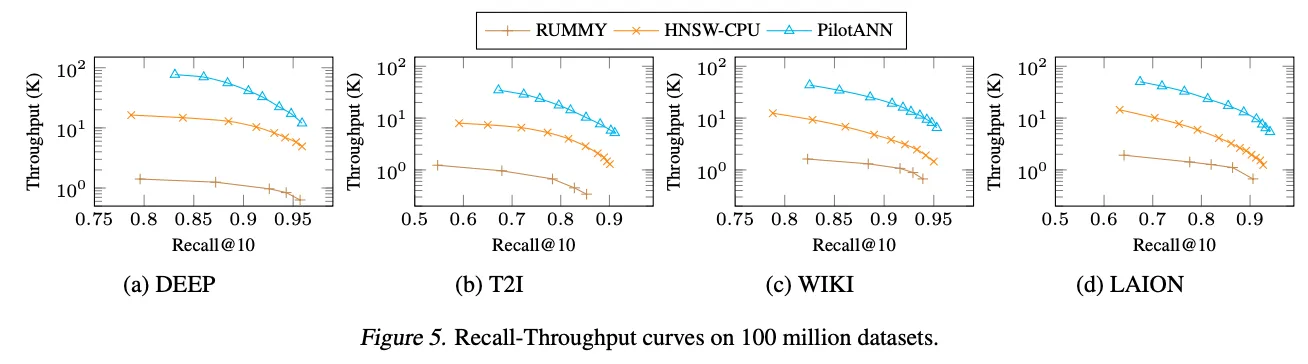
实验结果表明 PilotANN 在各种大规模数据集上都具有性能优势。与 HNSW-CPU 基线相比,PilotANN 在 96 维 DEEP 数据集上实现了 3.9 倍的吞吐量加速,在高维数据集上更是实现了 5.1-5.4 倍的惊人加速。尽管没有针对此基准进行特定优化,但 PilotANN 即使在极具挑战性的 T2I 数据集上也实现了显著的加速。
此外,尽管使用了更昂贵的硬件,但它仍显示出了出色的成本效益。虽然基于 GPU 的平台成本为 2.81 美元/小时,而仅使用 CPU 的解决方案成本为 1.69 美元/小时,但以每美元吞吐量来衡量,PilotANN 在 DEEP 数据集上的成本效益为 2.3 倍,在 T2I、WIKI 和 LAION 数据集上的成本效益为 3.0-3.2 倍。
最后,研究人员介绍了 PilotANN,这是基于图形的 ANNS 的一项进步,它有效地利用 CPU 和 GPU 资源来处理新兴工作负载。通过将 top-k 搜索智能分解为多阶段 CPU-GPU 管道并实现高效的条目选择,它比现有的仅使用 CPU 的方法表现出色。它通过使用单个商品 GPU 实现有竞争力的结果,使高性能最近邻搜索变得民主化,使计算资源有限的研究人员和组织能够使用高级搜索功能。与需要昂贵的高端 GPU 的替代解决方案不同,PilotANN 能够在常见硬件配置上高效部署 ANNS,同时保持搜索准确性。
更多详细信息,请参考:https://github.com/ytgui/PilotANN
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/57058.html
