
自回归视觉生成模型已成为一种突破性的图像合成方法,其灵感来自语言模型 token 预测机制。这些创新模型利用图像标记器将视觉内容转换为离散或连续 token。该方法促进了灵活的多模态集成,并允许采用 LLM 研究中的架构创新。然而,该领域面临着确定最佳标记表示策略的关键挑战。离散和连续token 表示之间的选择仍然是一个根本性的难题,严重影响模型复杂性和生成质量。
现有方法包括视觉标记化,它探索了两种主要方法:连续和离散 token 表示。变分自动编码器建立保持高视觉保真度的连续潜在空间,成为扩散模型开发的基础。VQ-VAE 和 VQGAN 等离散方法支持直接的自回归建模,但遇到了重大限制,包括码本崩溃和信息丢失。自回归图像生成从计算密集型的基于像素的方法发展到更高效的基于 token 的策略。虽然 DALL-E 等模型显示出有希望的结果,但 GIVT 和 MAR 等混合方法引入了复杂的架构修改以提高生成质量,使传统的自回归建模管道变得复杂。
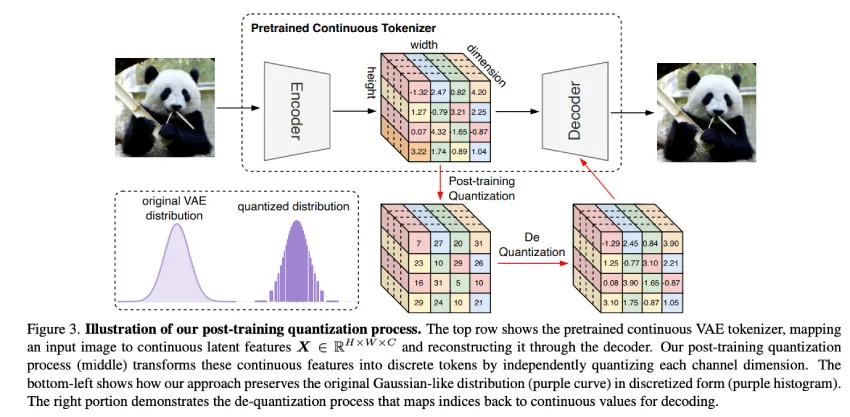
香港大学、字节跳动种子、巴黎综合理工学院和北京大学的研究人员提出了 TokenBridge,以弥合视觉生成中连续和离散 token 表示之间的关键差距。它利用连续 token 的强大表示能力,同时保持离散token 的建模简单性。TokenBridge 通过引入一种新颖的训练后量化技术,将离散化过程与初始标记器训练分离开来。此外,它实施了一种独特的维度量化策略,可以独立离散化每个特征维度,并辅以轻量级自回归预测机制。它有效地管理扩展的标记空间,同时保留高质量的视觉生成能力。

TokenBridge 引入了一种无需训练的维度量化技术,该技术在每个特征通道上独立运行,有效地解决了以前的 token 表示限制。该方法利用了变分自编码器特征的两个关键特性:由于 KL 约束和近高斯分布而产生的有界性质。自回归模型采用具有两种主要配置的 Transformer 架构:用于初步研究的默认 L 模型,包含 32 个块,宽度为 1024(约 4 亿个参数);用于最终评估的更大的 H 模型,包含 40 个块,宽度为 1280(约 9.1 亿个参数)。这种设计允许对不同模型规模中提出的量化策略进行详细探索。
结果表明,TokenBridge 的表现优于传统的离散 token 模型,以显著更少的参数实现了卓越的 Frechet 初始距离 (FID) 得分。例如,TokenBridge-L 仅使用 4.86 亿个参数就获得了 1.76 的 FID,而 LlamaGen 使用 31 亿个参数获得了 2.18 的 FID。与连续方法相比,TokenBridge-L 的表现优于 GIVT,FID 为 1.76,而 GIVT 为 3.35。H 模型配置进一步验证了该方法的有效性,在 FID(1.55)方面与 MAR-H 相当,同时以略少的参数提供了卓越的初始得分和召回率指标。这些结果表明 TokenBridge 能够桥接离散和连续 token 表示。
最后,研究人员推出了 TokenBridge,它弥合了离散和连续 token 表示之间的长期差距。它通过引入训练后量化方法和维度自回归分解,以惊人的效率实现了高质量的视觉生成。研究表明,使用标准交叉熵损失的离散 token 方法可以与最先进的连续方法相媲美,无需复杂的分布建模技术。该方法为未来的研究提供了一条有希望的途径,有可能改变研究人员概念化和实施基于 token 的视觉合成技术的方式。
更多信息请查看:https://github.com/yuqingwang1029/TokenBridge
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/57010.html
