
作者:Ryuk
来源:语音算法组
原文:https://mp.weixin.qq.com/s/t5ul2sXKRkRDdFsBytCLHA
许多智能设备现在支持超宽带的高质量语音通信服务。然而,有时为了节省带宽或者当它们与不支持超宽带的网络或设备配合使用时,语音质量往往会受到失真影响。此时,可以使用音频带宽扩展(Audio Bandwidth Extension, ABE)来改善语音质量。带宽扩展旨在估计缺失的高频内容,换句话说,即提高语音信号的分辨率,通常是从 4-8kHz 扩展到 16kHz。早期的研究主要通过窄带信号的频谱参数(如频谱包络和增益)来估计宽带信号的频谱参数。这些方法采用了非负矩阵分解、线性预测编码、隐马尔可夫模型以及高斯混合模型等技术。
随着深度学习的应用极大地提升了带宽扩展的性能,相较于传统方法,其建模能力更为强大。深度学习的引入极大地提升了带宽扩展的效果,特别是自回归模型、生成对抗网络(GANs)、变分自编码器(VAEs)以及基于变换器(Transformer)的架构,使得高频信息的估计更加精确且自然。此外,近年来,扩散模型(Diffusion Models)也开始应用于带宽扩展任务,以生成更真实的高频成分。
音频的高频成分在语音质量、感知体验和下游任务中起着重要作用,主要体现在以下几个方面:
- 高频成分包含丰富的谐波信息,对辅音(如 /s/、/f/、/t/)的感知尤为重要。例如,电话语音通常限制在 300Hz-3.4kHz,导致部分辅音听起来模糊,而带宽扩展到 16kHz 后,语音更接近真实人声,清晰度和自然度明显提高。
- 某些语言的音素主要依赖高频成分进行区分,例如英语中的 /s/ 和 /ʃ/(“see” vs. “she”),如果高频信息缺失,听众可能难以分辨类似的发音,影响语音的可懂度。
- 高频成分携带重要的空间感知信息,例如房间混响、方向感和立体声特性。因此,在音乐和沉浸式音频应用(如 VR、3D 音频)中,高频成分能够增强空间感,使音频听起来更自然和生动。
- 在音乐压缩(如 MP3、AAC)中,高频成分决定了音色的细腻程度。高频缺失可能导致音乐变得暗淡、失去层次感。因此,许多高质量音频编解码器(如 Hi-Res Audio、LDAC)都强调高频部分的保留。
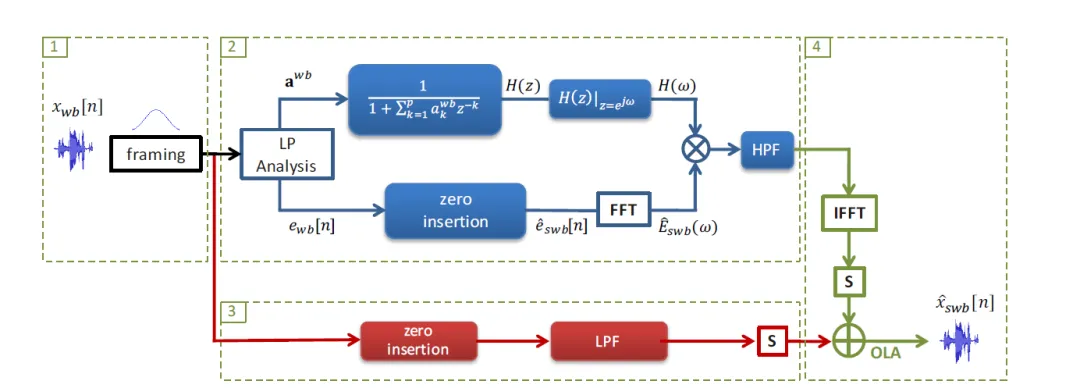
在传统带宽扩展算法中,线性预测系数是比较常用的重构音频参数,基于线性预测分析的带宽扩展算法流程框图如下所示,大致可以分为4个步骤:
- 对音频进行分帧
- 其中高频成分通过线性预测分析来估计
- 其中低频成分直接原始宽带信号中提取
- 高频成分通过IFFT得到对应的时域信号,由于低频(LF)和高频(HF)估计过程中可能引入不同的延迟,因此需要同步对齐。最后将对齐后的高频信号和低频信号进行相加,然后使用OLA进行拼接得到最终的32kHz信号。
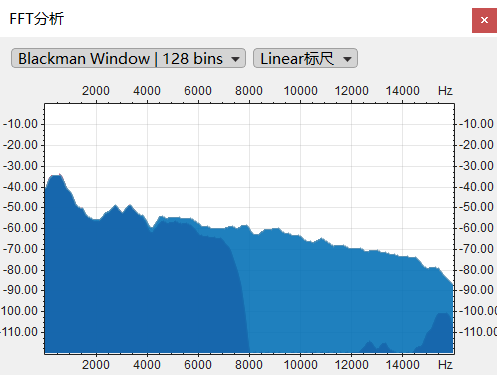
通过对比基于线性预测分析(LPC)算法的带宽扩展技术处理前后的音频样本,在输入信号为8kHz窄带音频的条件下,算法成功重构了8-16kHz高频频谱成分,并且频谱没有明显的缺失跳变等现象,语音听感流畅且没有杂音。

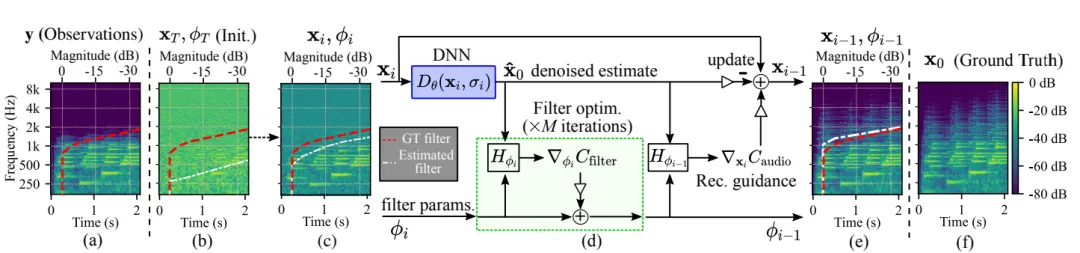
扩散模型(Diffusion Model, DM)在生成类任务中的应用广泛,尤其在图像、音频、文本和3D内容生成等领域取得了突破性的进展。其核心思想是通过逐步添加噪声将数据映射到高斯分布,然后再逐步去噪生成样本。因此将其应用在带宽扩展也是顺理成章的事。基于扩散模型的音频带宽或者推理过程通过反向扩散过程迭代重建缺失的高频频谱(如图b,c,e所示),同时在反向扩散过程中盲估计低通滤波器的失真(白色线叠加显示)。其中d详细展示了一个采样步骤,应用了DNN作为去噪深度神经网络,滤波器参数 ϕi 通过迭代进行优化,音频数据 xi 通过重建引导进行更新。
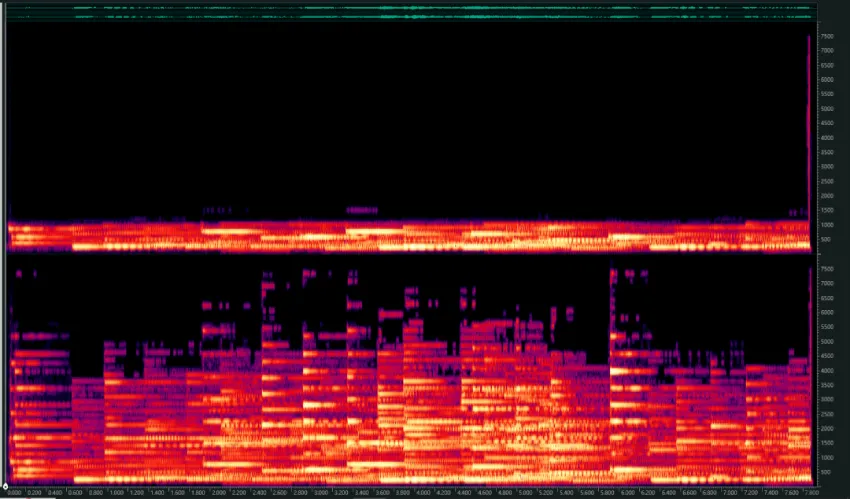
基于深度学习的带宽扩展算法能力更为强大,下图是音乐信号经过带宽扩展前后的频谱对比。原始信号只有1kHz以下的频率成分,而经过扩散模型后可以还原1kHz到8kHz的频率成分。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
