
本文介绍了一种实用的实时神经视频编解码器(NVC),旨在提供高压缩比、低延迟和广泛的通用性。在实际应用中,NVC的编码速度取决于计算成本和非计算操作成本,虽然大多数高效的NVC优先减少计算成本,但本文发现操作成本是实现更高编码速度的主要瓶颈。基于此,本文提出通过减少操作复杂度来加速NVCs。具体来说,采用隐式时态建模来消除复杂的显式运动模块,并使用单一低分辨率的潜在表示而不是逐步下采样。此外,还实现了模型整数化以确保跨设备编码的一致性,并引入了一种基于模块库的速率控制方案以提高实际适应性。实验表明,本文提出的DCVC-RT在1080p视频上实现了125.2/112.8 fps的编码/解码速度,相比H.266/VTM节省了21%的比特率。
题目:Towards Practical Real-Time Neural Video Compression
作者:Zhaoyang Jia, Bin Li, Jiahao Li, Wenxuan Xie, Linfeng Qi, Houqiang Li, Yan Lu
来源:CVPR 2025
文章地址:https://arxiv.org/abs/2502.20762
内容整理:令潇越
引言
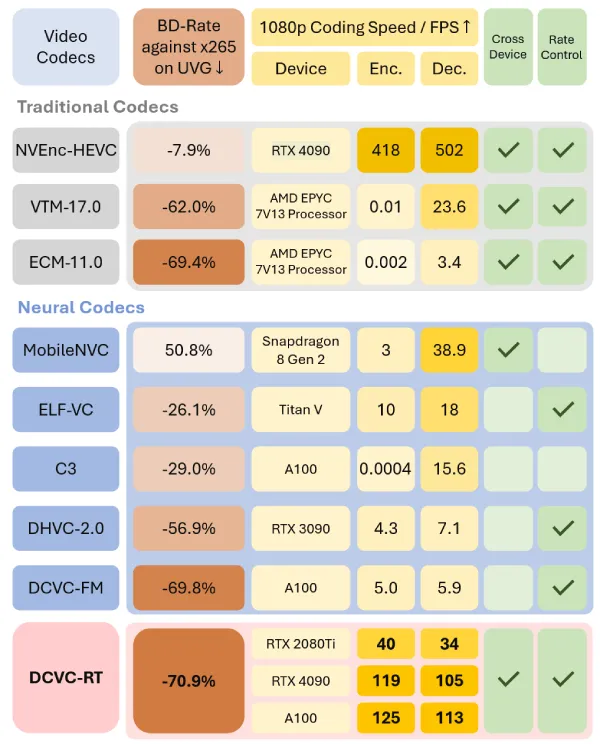
神经视频编解码器(NVCs)在实现更高压缩比方面展现出了巨大潜力。最近的NVCs已经超越了传统的编解码器,如H.265/HM、H.266/VTM和ECM。在此背景下,压缩比已不再是NVCs的主要瓶颈。相反,关键挑战在于如何使NVCs更加实用和可部署,以有效利用这些压缩比优势。
为了加速NVCs,本文第一步是重新思考复杂度问题。虽然大多数现有研究专注于减少计算复杂度,但这并不能决定实际的编码速度。实际上,诸如硬件组件之间的通信等其他操作也显著影响性能,本文将这些因素定义为操作复杂度。研究发现,高操作开销,而非计算成本,是加速NVCs的主要瓶颈。
基于这一见解,本文提出了一种新的视角来通过减少操作复杂度来加速NVCs。在此过程中,通过优先将更多的计算能力分配给最关键的模块,同时消除不太重要的模块,来保持模型容量。首先,移除了复杂运动估计和补偿过程,显著减少了组件数量,从而直接降低了操作频率。节省下来的计算能力被重新分配到帧编码模块,以实现更有效的隐式时态建模。此外,提出在单一低分辨率下学习潜在表示,即原始图像大小的1/8。与常用的逐步下采样方法相比,这种方法大大减少了潜在的内存I/O开销,同时促进了更有效的潜在变换,从而提高了率失真复杂度性能。
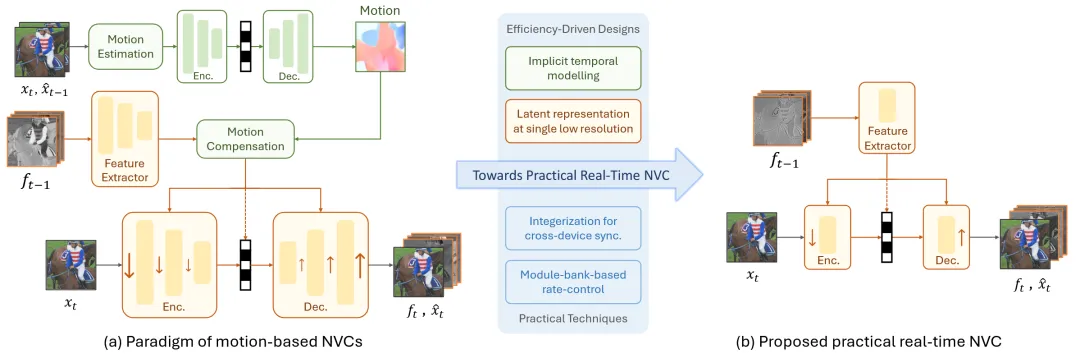
通过上述实时创新,进一步实现了模型整数化,以确保跨设备一致性,并引入了一种基于模块库的速率控制技术。这些进步共同造就了一种实用的实时NVC,即DCVC-RT。如图1所示,它可以在消费级GPU(如NVIDIA RTX 2080Ti)上实现1080p编码,平均编码速度为40 fps,解码速度为34 fps。在NVIDIA A100 GPU上,它达到了125 fps编码速度和113 fps解码速度。与VTM/H.266相比,本文的模型在使用单帧帧内编码设置时提供了21.0%的比特率节省。此外,它与先进的DCVC-FM相匹配,同时编码速度超过18倍。据本文所知,DCVC-RT是第一个在消费硬件上实现高压缩比实时编码的实用NVC。
本文的贡献总结如下:
- 研究了NVCs中的复杂度挑战,并确定操作复杂度,而非计算复杂度,是主要瓶颈。
- 基于此见解,提出了几种以效率为导向的设计,以减少操作复杂度并启用实时NVCs。进一步增强了功能,引入了一种实用的实时NVC,即DCVC-RT。
- 据本文所知,DCVC-RT是第一个实现高率失真性能的实时NVC,能够在消费硬件上实现1080p实时编码,与VTM/H.266相比节省了21%的比特率。
重新思考NVCs中的复杂度问题
在实际中,许多因素影响编码速度。本文确定了两个关键因素:1)潜在表示大小Psize,主要影响潜在张量的内存I/O成本;和 2)模块数量Pnum,影响总操作次数和函数调用开销。这些因素主要影响硬件计算之外的其他操作,本文称之为操作复杂度,与计算复杂度Pcomp不同。通过实验独立控制Pcomp、Psize和Pnum以观察它们对推理速度的影响。通过平衡模块数量N、通道数C和潜在分辨率H x W来实现每个因素的独立控制。例如,将C减半同时将H x W加倍,保持Psize不变,但由于C与计算复杂度呈二次方关系,因此减少了Pcomp。
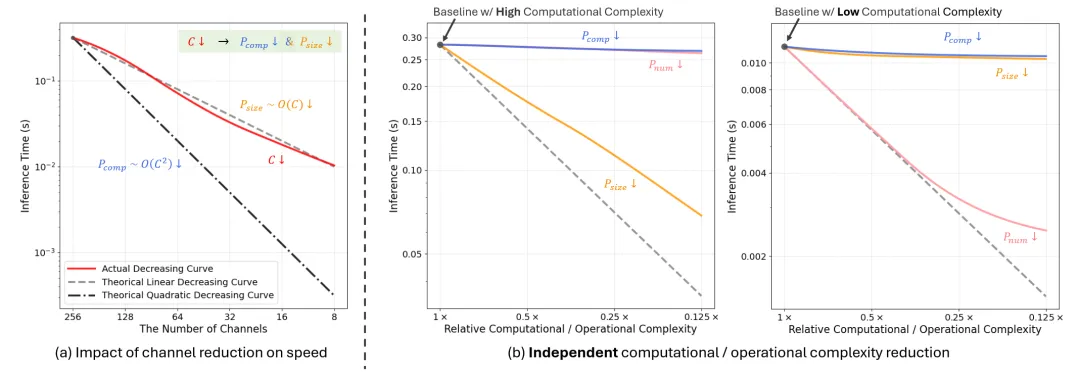
图3(b)的结果揭示了几个关键见解。1)操作复杂度,而非计算复杂度,是主要的速度瓶颈。在不解决操作因素的情况下减少计算成本只会带来边际的推理时间改进。这也解释了为什么减少通道数会导致时间线性而非二次方下降——因为潜在大小随通道数线性减少。2)当计算复杂度高时,潜在表示大小成为主要限制因素。当计算复杂度低时,模块数量成为关键瓶颈。这表明模型的不同部分需要不同的优化策略。
这些见解为通过减少操作复杂度来加速NVCs提供了新的视角。通常,降低计算复杂度会导致压缩性能下降。然而,由于计算复杂度不再是主要的速度瓶颈,可以专注于降低操作复杂度,同时保持计算能力。在设计中,将计算能力优先分配给最关键的模块,同时消除不太重要的模块,这确保了足够的模型容量并实现了更好的率失真复杂度权衡。
通向实用的实时NVC
概述
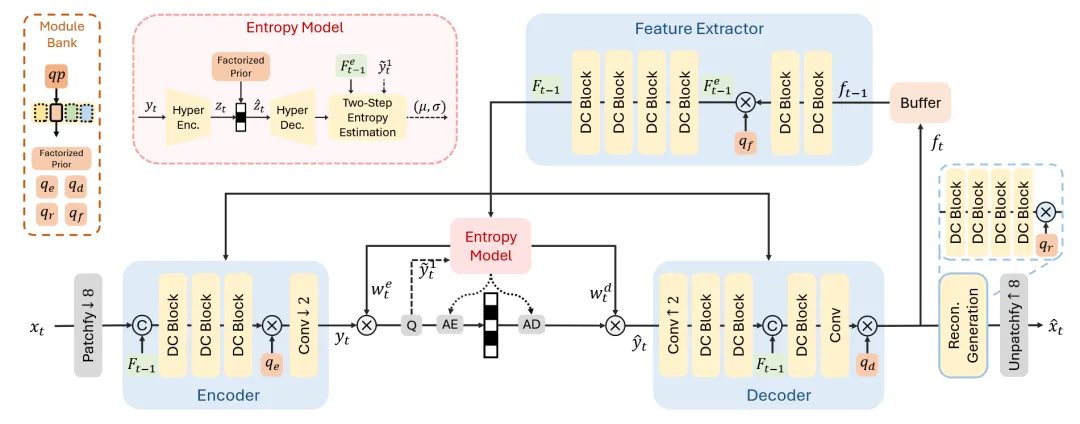
所提出的DCVC-RT框架如图4所示。为了压缩当前帧,首先使用patch embedding将其转换为1/8尺度的潜在表示。然后在此单一低分辨率下进行条件编码,以实现高效编码。在提取时态上下文信息时,DCVC-RT结合了隐式时态建模,以避免复杂的运动估计-运动补偿过程。为了提高通用性,引入了一种基于模块库的速率控制方法,并启用了模型整数化,以确保跨设备一致性。
单一低分辨率下的潜在表示
源于压缩自编码器的概念,大多数NVCs逐步下采样潜在表示以降低维度。在每一层,它们将潜在表示下采样一半,同时将通道数翻倍。这使得各层之间的计算复杂度Pcomp相当,
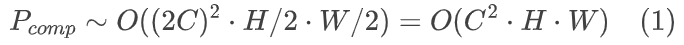
而潜在大小Psize逐渐减少
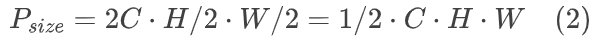
研究表明,潜在大小可能是编码速度的主要瓶颈。从操作复杂度的角度来看,一个问题出现了:能否在单一低分辨率下学习潜在表示,以消除与大Psize相关的高操作成本?为了探索这一点,直接使用patch embedding将帧下采样到单一尺度,并在此尺度下应用条件编码进行压缩。结果显示,在1/8尺度下学习潜在表示比逐步下采样快约3.6倍。
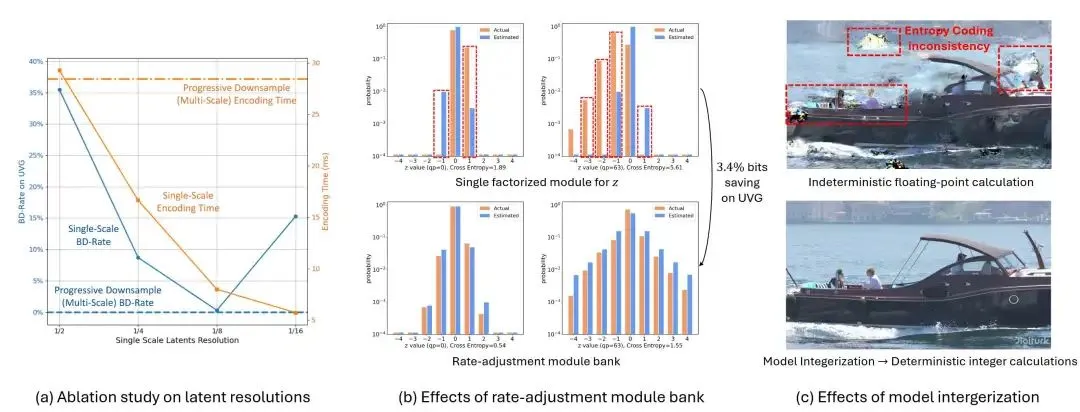
虽然减少潜在尺度会加速模型推理,但也会影响率失真性能。在单一高1/2分辨率下,受限的感受野导致性能显著下降。然而,随着尺度的降低,感受野显著扩大,在1/8尺度下,它甚至超过了逐步下采样的感受野。这种扩展的感受野对于增强时态建模和减少时态冗余至关重要,导致在相同模型容量下BD-Rate仅为0.3%。但在1/16尺度下观察到性能下降。在1/16尺度下,潜在表示 C = 512 与产生的潜在大小为512 · H/16 · W/16 = 2 · H · W,甚至小于原始帧3 · H · W。这显著限制了表示能力和压缩比。相比之下,在1/8尺度下,使用C = 256产生的潜在大小为 4 · H · W。考虑到这些因素,采用1/8单一尺度潜在学习。
隐式时态建模
在视频编码中,时态相关性建模对于有效减少冗余至关重要。大多数现有的NVCs通过显式的运动估计和运动补偿过程来实现这一点。通常,运动编码需要低计算复杂度,因为运动更简单且更容易压缩。然而,观察到现有的运动模块通常使用大量的模块层,这种高层数增加了操作复杂度,成为低计算复杂度运动模块的主要速度瓶颈。
为了解决这个问题,DCVC-RT采用了隐式时态建模,使用单一简单的特征提取器提取时态上下文,而不是基于运动的时态上下文提取。具体来说,该时态上下文在通道维度上与当前潜在表示连接,允许编码器-解码器联合处理它们以减少冗余。通过消除运动估计和补偿的需要,模块数量直接减少,降低了操作频率,显著提高了编码速度。

如表1所示,在小运动下,隐式建模将BD-Rate略微提高了0.4%,而在大运动下则显示出3.2%的减少。尽管如此,由于编码时间快了3.4倍,隐式建模在实时应用中更为实用。此外,在场景变化情况下,它超过了显式运动,因为场景变化无法通过运动有效建模。这些结果凸显了其在率失真复杂度权衡中的优势。
基于模块库的速率控制
在DCVC-RT中,速率控制通过可变速率编码和动态速率调整实现。虽然现有的可变速率编解码器主要关注调整潜在的分布,它们通常使用单一因子化先验模块压缩超信息z。由于通常占总比特数的不到1%,因此对它们的性能影响很小。然而,在DCVC-RT中,z平均贡献了超过10%的比特,因为缺乏运动比特使得在时空建模中至关重要。在这种情况下,对的分布估计不准确会严重影响整体性能。
为了解决这个问题,引入了一个速率调整模块库。它学习了一系列超先验模块,以在不同量化参数(qp)下建模不同的分布。该模块库紧密对齐估计分布与实际分布,实现了约3%的比特节省。进一步扩展这种方法,还为不同模块引入了单独的向量库(例如qe,qd、qf和qr分别用于编码器、解码器、特征提取器和重建网络)。每个向量库旨在学习一组向量,根据其特性自适应地缩放潜在表示,从而实现灵活和细粒度的幅度调整。DCVC-RT利用此模块库实现高效的速率控制。
此外,DCVC-RT通过调整不同帧的qp偏移量,支持分层质量控制。与采用单独的特征适配器相比,这种方法在速率调整中实现了更好的一致性,并在实际应用中具有更高的灵活性。
模型整数化
对于NVCs,浮点计算的不确定性可能导致在分发视频内容时出现不一致。为了解决这个问题,实现了16位模型整数化。这种方法启用了确定性的整数计算,确保了在不同设备上的一致输出。更具体地说,浮点特征值vf和int16值vi之间的方程如下:
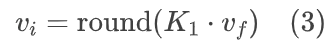
设置K1 = 512,使得浮点值1.0在int16中映射为512,并且考虑到int16的有效范围是[-32768,32767],对应的浮点值范围是[-64.0,63.998]。在卷积核中将累加器数据类型设置为int32,且未观察到溢出问题。除了卷积和基本算术运算外,采用预计算的查找表来处理非线性Sigmoid函数,将任意int16值映射到其对应输出。通过这种无训练的模型整数化,DCVC-RT可以执行确定性的整数计算,确保跨设备的一致性。
实验
设置
数据集 使用Vimeo-90k来训练DCVC-RT。在HEVC Class BE、UVG和MCL-JCV上评估DCVC-RT。
测试详情 对于传统编解码器,与HM、VTM和ECM进行比较,它们分别代表了H.265、H.266编码器和下一代传统编解码器原型的最佳水平。对于神经编解码器,与先进的NVCs如DCVC-DC和DCVC-FM进行比较。在低延迟条件下进行所有测试。率失真性能通过BD-Rate进行评估。此外,注意到许多现有的NVCs使用估计的熵与传统编解码器进行比较,这是不公平的,因为它们忽略了头部信息。通过重新测试它们的实际二进制比特流(包括必要的头部信息)来确保公平比较。默认情况下,编码速度在单个NVIDIA A100 GPU和AMD EPYC 7V13处理器上进行测试。在分辨率下对不同量化参数(qp)的平均延迟进行测量。
训练详情 为了在一个模型内支持可变速率,在每个训练迭代中在之间随机分配不同的qp。在8张图片的组中,qp偏移量设置为以支持分层质量。
比较结果
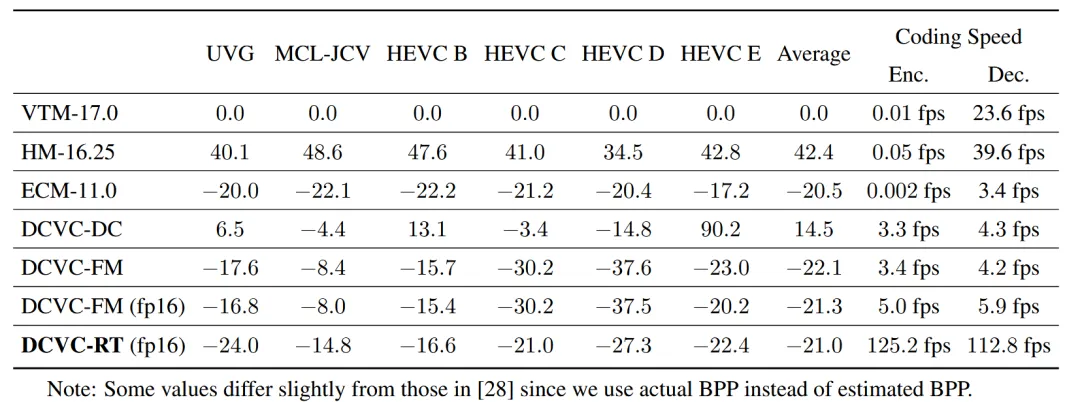
如表2所示,DCVC-RT相比VTM平均节省了21.0%的比特率,略好于ECM的20.5%。它展示了与先进的NVC DCVC-FM相当的压缩比,同时编码速度令人印象深刻,达到125.2 fps编码和112.8 fps解码,比DCVC-FM快了25倍。这证明了DCVC-RT在率失真复杂度权衡方面的卓越性能。在RGB色彩空间中,DCVC-RT相比VTM节省了14.0%的比特率,与DCVC-FM的15.8%节省率相当。详细结果在补充材料中提供。
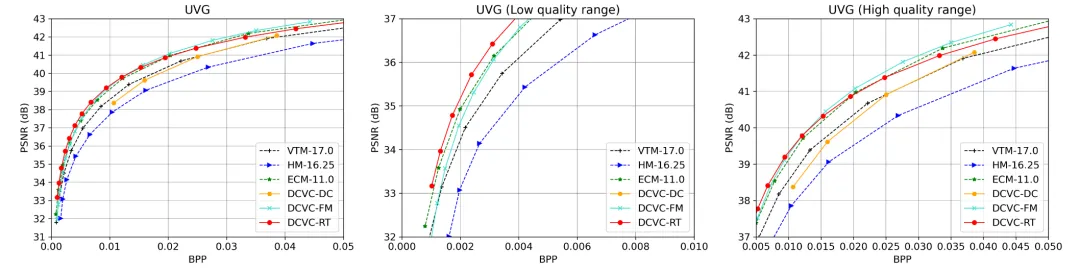
图6展示了UVG的率失真曲线。DCVC-RT在所有质量范围内与VTM相比都表现出更好的性能。特别是在低质量范围(<0.02 bpp)内,DCVC-RT表现出最佳性能。然而,在高质量范围内存在性能下降。这种下降可以归因于DCVC-RT采用的轻量级模型设计,导致模型能力较大型模型有所降低。值得注意的是,这种下降主要发生在40 dB以上,人类视觉在此难以区分不同质量。
复杂度分析
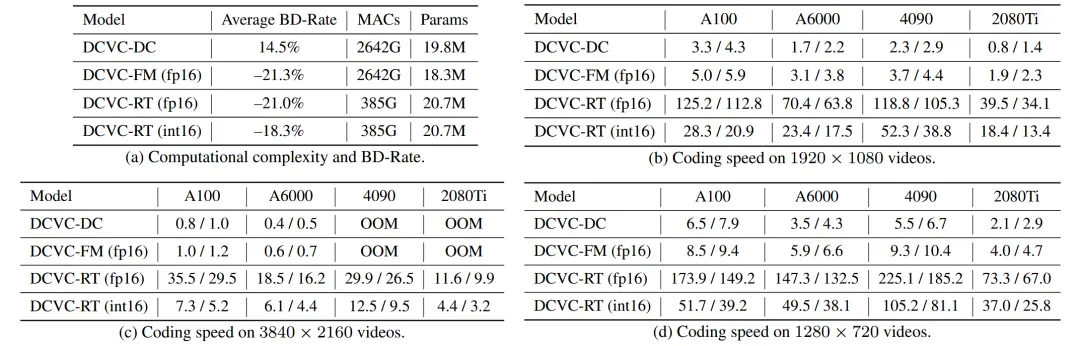
表3展示了复杂度分析。与DCVC-DC和DCVC-FM相比,DCVC-RT在保持相当压缩比的同时显著降低了计算复杂度。在多个输入分辨率和GPU设备上评估编码速度,始终显示出至少20倍的速度提升。在A100 GPU上,DCVC-RT(fp16)实现了4K 30fps的实时编码,而在消费级设备如RTX 2080 Ti上,它实现了1080p 30fps的编码。这些结果突显了DCVC-RT在不同条件下的高效性。
整数化结果
模型支持16位整数计算。表3显示,整数化策略对压缩性能的影响很小,DCVC-RT(int16)仍然比VTM高出18.3%。在编码速度方面,DCVC-RT(int16)在RTX 4090上实现了1080p 30 fps的编码,在RTX 2080Ti上实现了720p 24 fps的编码。
然而,使用int16模式时编码速度比fp16慢得多。这主要是因为大多数现代GPU缺乏对int16操作的专用优化。这种差异在A100 GPU上尤为明显,其高度优化的张量核心使fp16处理速度比int16快四倍以上。尽管理论上int16模式有可能比fp16更快,预计未来的硬件发展和工程将有助于缩小这一性能差距。
结论与局限性
本文提出了一种实用的实时神经视频编解码器,专注于高压缩比、低延迟和广泛的通用性。通过分析NVCs的复杂度,确定操作成本,而非计算成本,是编码速度的主要瓶颈。基于这一见解,采用隐式时态建模和单一低分辨率潜在表示,这显著加速了处理而不损害压缩质量。此外,引入了模型整数化以确保跨设备编码的一致性,并引入了一种基于模块库的速率控制方案以增强实际适应性。据本文所知,DCVC-RT是第一个在1080p视频上实现110 fps编码的NVC,相比H.266/VTM节省了21%的比特率。DCVC-RT是NVC演变历程中的一个显著里程碑。
尽管DCVC-RT支持int16模式,但由于int16推理的硬件优化有限,其编码速度仍慢于fp16。在未来,希望这能通过进一步的硬件优化和工程来解决。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
