
在人工智能领域,多语言语音识别和翻译已成为促进全球交流的重要工具。然而,开发能够实时准确地转录和翻译多种语言的模型面临着巨大的挑战。这些挑战包括管理不同的语言细微差别、保持高准确性、确保低延迟以及在各种设备上高效部署模型。
为了应对这些挑战,NVIDIA AI 开源了两个模型:Canary 1B Flash 和 Canary 180M Flash。这些模型专为多语言语音识别和翻译而设计,支持英语、德语、法语和西班牙语等语言。这些模型在宽松的 CC-BY-4.0 许可下发布,可用于商业用途,鼓励 AI 社区内的创新。
从技术上讲,两种模型都采用了编码器-解码器架构。编码器基于 FastConformer,可高效处理音频特征,而 Transformer Decoder 负责文本生成。特定于任务的标记(包括 <目标语言>、<任务>、<切换时间戳> 和 <切换 PnC>(标点符号和大写))指导模型的输出。Canary 1B Flash 模型包含 32 个编码器层和 4 个解码器层,共计 8.83 亿个参数,而 Canary 180M Flash 模型包含 17 个编码器层和 4 个解码器层,共计 1.82 亿个参数。这种设计确保了可扩展性和对各种语言和任务的适应性。
性能指标表明,Canary 1B Flash 模型在开放 ASR 排行榜数据集上实现了超过 1000 RTFx 的推理速度,可实现实时处理。在英语自动语音识别 (ASR) 任务中,它在 Librispeech Clean 数据集上的单词错误率 (WER) 为 1.48%,在 Librispeech Other 数据集上的单词错误率 (WER) 为 2.87%。对于多语言 ASR,该模型在 MLS 测试集上对德语、西班牙语和法语的 WER 分别为 4.36%、2.69% 和 4.47%。在自动语音翻译 (AST) 任务中,该模型在 FLEURS 测试集上表现出色,英语到德语的 BLEU 分数为 32.27,英语到西班牙语的 BLEU 分数为 22.6,英语到法语的 BLEU 分数为 41.22。
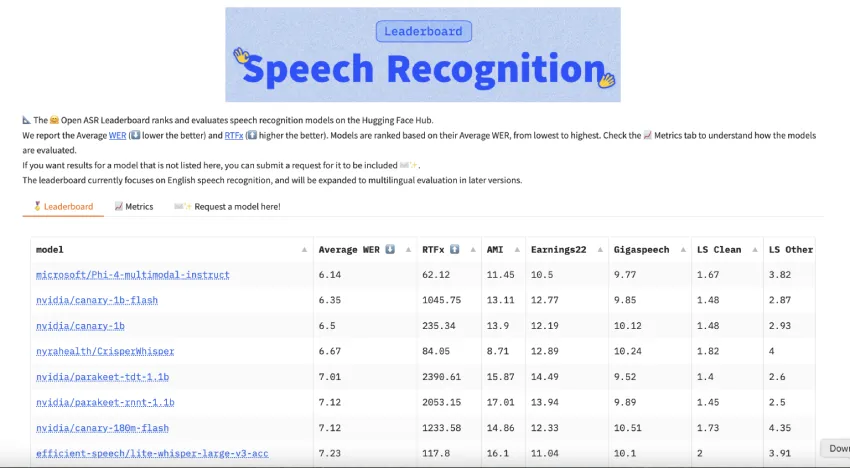
较小的 Canary 180M Flash 模型也提供了令人印象深刻的结果,推理速度超过 1200 RTFx。它在 Librispeech Clean 数据集上实现了 1.87% 的 WER,在 Librispeech Other 数据集上实现了 3.83% 的英语 ASR 错误率。对于多语言 ASR,该模型在 MLS 测试集上记录的德语 WER 为 4.81%,西班牙语 WER 为 3.17%,法语 WER 为 4.75%。在 AST 任务中,它在 FLEURS 测试集上实现了英语到德语 28.18 的 BLEU 分数,英语到西班牙语 20.47 的 BLEU 分数,英语到法语 36.66 的 BLEU 分数。
两种模型都支持单词级和片段级时间戳,从而增强了它们在需要音频和文本之间精确对齐的应用中的实用性。它们体积小巧,适合在设备上部署,从而实现离线处理并减少对云服务的依赖。此外,它们的稳健性可以减少翻译任务中的幻觉,从而确保更可靠的输出。根据 CC-BY-4.0 许可发布的开源版本鼓励社区进行商业利用和进一步开发。
综上所述,NVIDIA 开源 Canary 1B 和 180M Flash 模型,是多语言语音识别和翻译领域的重大进步,其高准确率、实时处理能力和设备部署适应性解决了该领域现有的许多挑战。通过将这些模型开源,NVIDIA 不仅展示了其推动 AI 研究的承诺,也赋能开发者和组织构建更具包容性和效率的沟通工具。
查看 Canary 1B Model 和 Canary 180M Flash.
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/56826.html
