
在 NVIDIA GTC25 上,Gnani.ai 专家公布了语音 AI 领域的突破性进展,重点关注 Speech-to-Speech 基础模型的开发和部署。这种创新方法有望克服传统级联语音 AI 架构的局限性,开创无缝、多语言和情感感知语音交互的时代。
级联架构的局限性
目前最先进的语音代理架构包括三级管道:语音转文本 (STT)、大型语言模型 (LLM) 和文本转语音 (TTS)。虽然这种级联架构很有效,但它也存在重大缺陷,主要是延迟和错误传播。级联架构在管道中有多个块,每个块都会增加自己的延迟。这些阶段的累积延迟可能在 2.5 到 3 秒之间,导致用户体验不佳。此外,在 STT 阶段引入的错误会通过管道传播,加剧不准确性。这种传统架构还失去了情绪、情感和语调等关键的副语言特征,导致响应单调乏味。
Speech-to-Speech 基础模型简介
为了解决这些限制,Gnani.ai 提出了一种新颖的 Speech-to-Speech 基础模型。该模型直接处理和生成音频,无需中间文本表示。关键创新在于使用 14 种语言的 150 万小时标记数据训练大型音频编码器,捕捉情感、同理心和音调的细微差别。该模型采用嵌套 XL 编码器,使用综合数据重新训练,并使用输入音频投影仪层将音频特征映射到文本嵌入中。对于实时流式传输,音频和文本特征是交错的,而非流式传输用例则使用嵌入合并层。LLM 层最初基于 Llama 8B,后来扩展到包括 14 种语言,因此需要重建标记器。输出投影仪模型生成梅尔频谱图,从而可以创建超个性化的声音。
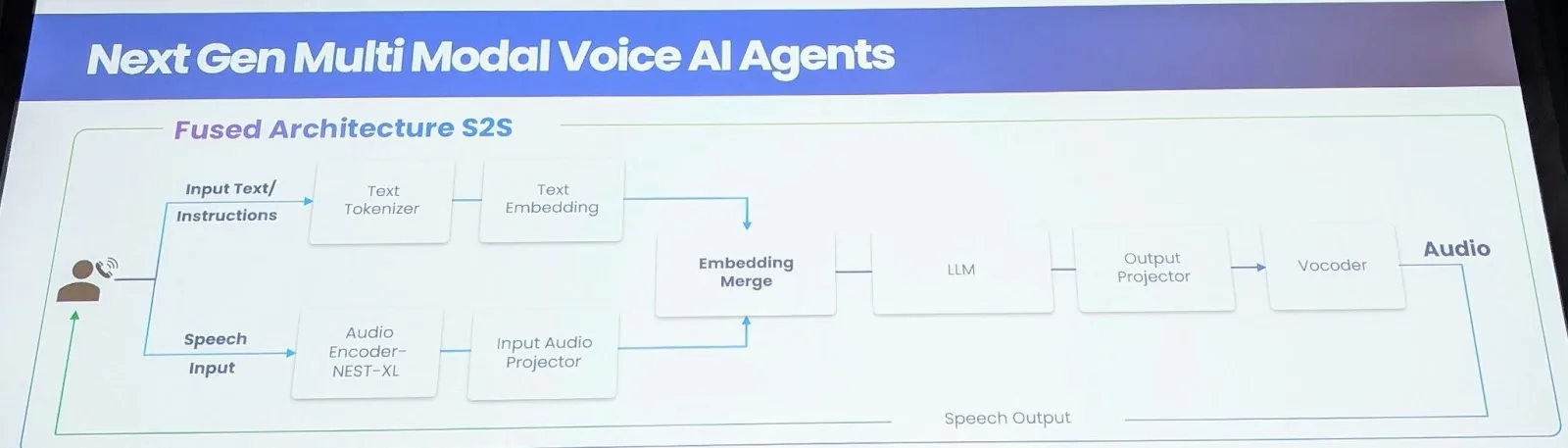
主要优势和技术障碍
Speech-to-Speech 模型提供了几个显著的好处。首先,它显著降低了延迟,第一个 token 输出的延迟从 2 秒缩短到大约 850-900 毫秒。其次,它通过将 ASR 与 LLM 层融合来提高准确性,从而提高性能,尤其是对于短语音和长语音。第三,该模型通过捕捉和建模音调、重音和语速来实现情感感知。第四,它通过情境感知实现更好的中断处理,促进更自然的交互。最后,该模型旨在有效处理低带宽音频,这对于电话网络至关重要。构建此模型面临多项挑战,尤其是海量数据需求。该团队创建了一个拥有 400 万用户的众包系统来生成情感丰富的对话数据。他们还利用基础模型来生成合成数据,并使用 1350 万小时的公开数据进行训练。最终模型包含一个 90 亿个参数模型,其中 6.36 亿个用于音频输入,80 亿个用于 LLM,3 亿个用于 TTS 系统。
NVIDIA 在发展中的作用
该模型的开发严重依赖于 NVIDIA 堆栈。NVIDIA Nemo 用于训练编码器-解码器模型,NeMo Curator 促进合成文本数据的生成。NVIDIA EVA 用于生成音频对,将专有信息与合成数据相结合。
使用案例
Gnani.ai 展示了两个主要用例:实时语言翻译和客户支持。实时语言翻译演示展示了一个人工智能引擎,帮助英语代理和法语客户进行对话。客户支持演示突出了该模型处理跨语言对话、打断和情感细微差别的能力。
小结
Speech-to-Speech 基础模型代表了语音 AI 的重大飞跃。通过消除传统架构的限制,该模型实现了更自然、更高效、更富有情感感知的语音交互。随着技术的不断发展,它有望改变从客户服务到全球通信等各个行业。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/56762.html
