
FreeSWITCH是开源的媒体服务器,广泛应用于呼叫中心,企业融合通信,IPPBX部署等环境。大炼钢铁的时代刚刚过去,大炼AI的时代来临,智能语音AI大模型眼花缭乱。Speech-to-Speech是比较强大的基于LLM的项目,通过和FreeSWITCH深度集成,实现新业务增长。本文为开发者提供了如何利用 FreeSWITCH 与开源 Speech-to-Speech(基于 GPT4-o 架构)进行深度集成的完整指南。本文内容经过优化,从架构设计、接口实现、安装部署到性能优化进行了全面探讨。
作者:james.zhu
来源:SIP实验室
原文:https://mp.weixin.qq.com/s/lolcEhXpXDJMv-dMiNcWbw
一、项目背景与技术简介
1.1 Speech-to-Speech 项目概述
Speech-to-Speech 项目由 Hugging Face 主导,旨在构建一个开放、模块化的语音转换系统,主要特点包括:
- 多语言语音识别(ASR):支持实时、多语言语音转写。
- 自然语言处理(NLP):采用类似 GPT 核心的模型处理语义理解与对话生成。
- 语音合成(TTS):生成自然、情感丰富的语音输出。
- 模块化设计:采用可扩展的模块化技术,可按需组合各处理环节。
1.2 FreeSWITCH的角色与集成需求
FreeSWITCH 是一个成熟的开源通信平台,具备以下特点:
- 模块化与扩展性:可以通过加载各种模块实现 SIP、WebRTC、DTMF 等业务需求。
- 实时媒体处理能力:支持低延迟、高并发音频流处理。
- 灵活接口:支持 Lua、Python 等脚本编程,方便自定义交互逻辑。
集成目标在于利用 FreeSWITCH 提供的高效通信基础,与 Speech-to-Speech 系统构建一条高性能的语音转换链路,提升交互体验。
二、系统整体架构与技术图示
2.1 架构概览
整合 FreeSWITCH 与 Speech-to-Speech 系统,我们设计了如下架构:
- 用户终端:通过 SIP/WebRTC 与 FreeSWITCH 建立连接。
- FreeSWITCH 媒体服务器:负责呼叫控制、流量转发及基本音频处理。
- STS服务集群:通过 WebSocket 或 HTTP API 接收音频,执行 ASR → NLP → TTS 流程。
- 数据持久层:存储会话日志及统计数据,用于后续监控与优化。
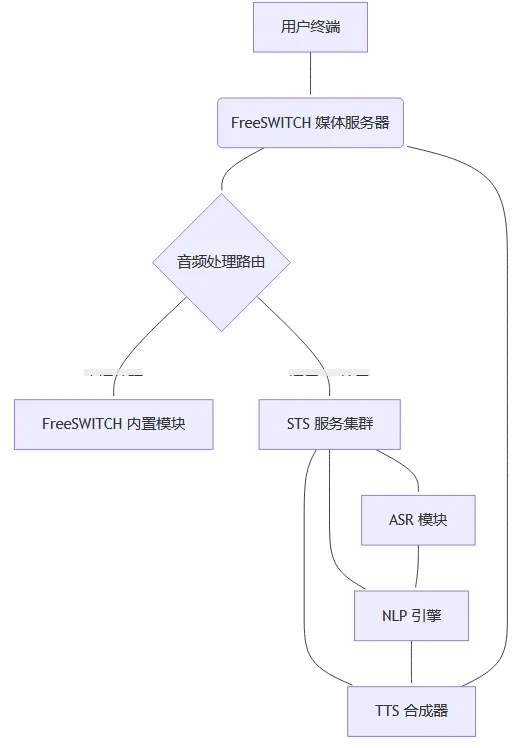

2.2 交互流程示意
采用序列图展示 FreeSWITCH 与 STS 服务之间的交互流程:
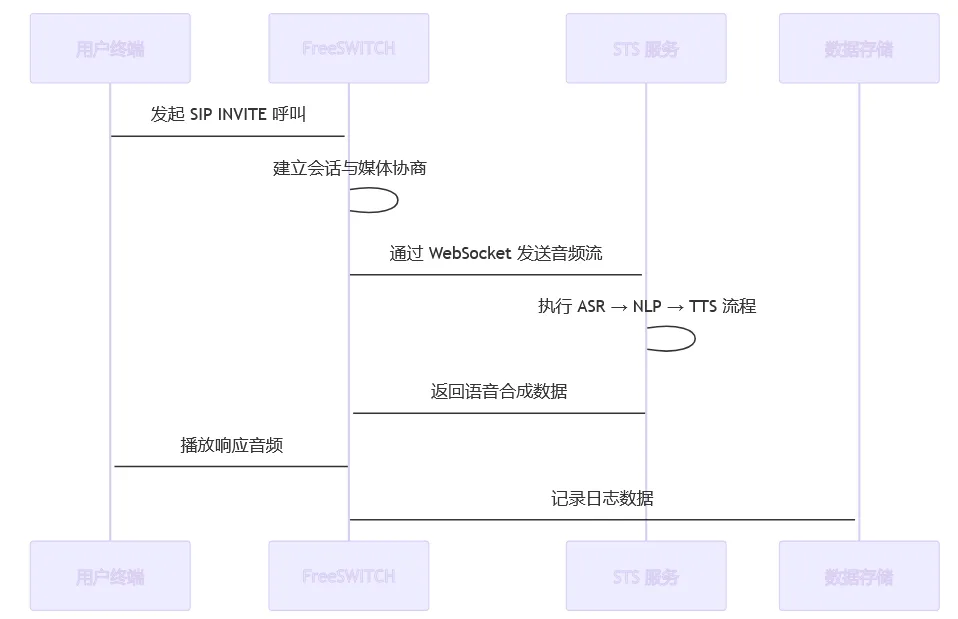
三、接口对接与集成实现
3.1 FreeSWITCH 的配置与模块加载
为实现与 STS 服务的无缝对接,需在 FreeSWITCH 中启用必要模块和配置拨号计划。以下为关键的 XML 配置示例:
<!-- conf/autoload_configs/modules.conf.xml -->
<load module="mod_curl"/>
<load module="mod_lua"/> 在拨号计划中添加新的扩展:
<!-- conf/dialplan/default.xml -->
<extension name="sts_integration">
<condition field="destination_number" expression="^5000$">
<action application="lua" data="sts_handler.lua"/>
</condition>
</extension> 其中,mod_curl 用于 HTTP 请求,mod_lua 则提供脚本处理能力,有效实现与 STS API 的交互。
3.2 Lua 脚本实现接口调用
以下 Lua 脚本示例展示了如何将 FreeSWITCH 会话中的语音数据通过 WebSocket 传递给 STS 服务,同时处理返回的合成语音:
-- sts_handler.lua
session:answer()
session:set_tts_params("flite", "kal")
local audio_url = "ws://sts-api:8000/process"
local wsh = session:webSocket(audio_url, "decode=true")
local retry_count = 0
local max_retries = 3
while retry_count < max_retries do
local data = wsh:read()
if data then
session:speak(data.text)
else
-- 当STS服务暂不可用时,进行降级处理
retry_count = retry_count + 1
session:execute("playback", "say:系统繁忙,请稍后再试")
break
end
end
session:hangup() 3.3 接口错误处理与日志记录
在实际环境中,异常处理与日志记录是保证系统稳定运行的重要环节。下面是一个通过 mod_curl 实现 API 重试的示例配置:
<!-- curl 请求自动重试配置 -->
<action application="curl" data="https://sts-api/process retries=3&retry-delay=1000"/> 结合详细的 FreeSWITCH 日志系统和外部监控工具,可对调用过程中的异常快速响应。
四、安装部署与系统配置
4.1 环境与硬件要求
为确保系统性能,建议部署环境达到以下要求:
| 组件 | 最低配置 | 推荐配置 |
| FreeSWITCH | 4核/8GB | 8核/32GB |
| STS服务 | 8核/16GB | 16核/64GB+GPU |
4.2 FreeSWITCH 安装步骤
以 Ubuntu 22.04 为例,安装 FreeSWITCH 的步骤如下:
# 安装依赖与下载源码
sudo apt update
sudo apt install -y git build-essential automake libtool
git clone https://github.com/signalwire/freeswitch.git
cd freeswitch
./bootstrap.sh
./configure
# 编译与安装
make -j$(nproc)
sudo make install 安装完成后,根据具体需要调整 SIP profiles 以及 media.conf.xml 等配置文件。
4.3 STS 服务部署
建议使用 Docker 方式部署 Speech-to-Speech 服务,配置示例如下:
# 使用 Docker 部署 STS 服务
docker run -p 8000:8000 huggingface/sts-service \
--model-size large \
--language zh-CN \
--tts-engine vocotron 五、性能优化与调优策略
5.1 性能监控关键指标
关键监控指标包括:
- CPU 使用率:理想状态下低于 50%
- 内存响应时间:降低延迟,保持高效率
- 网络抖动:优化 RTP/WebSocket 配置,抖动控制在 10ms 以下
定期查看 FreeSWITCH CLI 输出和 Prometheus 数据,确保系统运行稳定。
5.2 优化实践
5.2.1 内存与存储优化
将核心数据库 (core.db) 移动至内存文件系统可以有效提升执行效率:
# 挂载内存文件系统
sudo mount -t tmpfs -o size=512m tmpfs /usr/local/freeswitch/db 5.2.2 网络与传输参数调整
优化 switch.conf.xml 参数,调整媒体传输线程与定时参数:
<!-- conf/autoload_configs/switch.conf.xml -->
<settings>
<param name="media-io-threads" value="8"/>
<param name="timer-wheel-size" value="8192"/>
</settings> 5.2.3 服务降级机制
在 Lua 脚本中加入超时及降级逻辑:
-- 超时后退回基础播放提示
if retry_count >= max_retries then
session:execute("playback", "say:系统繁忙,请稍后再试")
session:hangup()
end 5.3 日志与监控
利用 FreeSWITCH CLI 及 Prometheus ,实现实时监控与详细日志记录:
# 查看当前通道数与状态
fs_cli -x "show channels"
fs_cli -x "status"
fs_cli -x "loglevel 7" Prometheus 配置示例:
# freeswitch_exporter.yml
modules:
-name:freeswitch
metrics:
-channel_count
-cpu_usage
-memory_usage
port:9234 六、系统调试与故障解决
6.1 调试基础
- • FreeSWITCH CLI:利用 CLI 可以直接查看系统运行状态、语音通道及错误日志。
- • Lua 脚本调试:在脚本中加入日志输出,便于定位问题原因。
6.2 故障排查建议
- 1. 接口响应超时:检查网络延迟和防火墙配置,同时调优重试机制。
- 2. 媒体传输异常:验证 SRTP/WebSocket 配置及 FreeSWITCH 的媒体参数设置。
- 3. 系统日志分析:通过分析日志文件,识别潜在的模块异常以及资源不足问题。
七、案例分享与扩展
本方案在架构设计和性能调优上做了如下定制化优化:
- 针对高并发场景进行分布式部署,缓解单点压力。
- 采用服务降级机制,确保在核心服务失效时依然能够提供基本交互能力。
- 加强监控策略,利用 Prometheus 及 Grafana 实时呈现系统性能指标,帮助运维人员快速响应问题。
这种定制化方案特别适合大型呼叫中心、企业内部统一通信平台,以及需要高可靠性、低延迟语音服务的应用场景。
八、总结与展望
通过本文的详细讲解,您已经了解了如何利用 FreeSWITCH 与开源 Speech-to-Speech 系统实现高度集成的语音交互平台。本文从架构设计、接口调用、安装部署到优化调试均做了详细阐述,并结合实际案例分享,为开发者提供了一套完整的解决方案。
未来,随着 AI 语音识别技术和自然语言处理能力的不断提升,类似的集成方案将会在更多行业场景中应用,带来更加智能化的通信体验。
参考资料
- FreeSWITCH官方文档
- Speech-to-Speech项目代码库
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。