
人工智能领域,仍然存在两个持续的挑战。许多高级语言模型需要大量的计算资源,这限制了小型组织和个人开发者对它们的使用。此外,即使这些模型可用,它们的延迟和大小也常常使它们不适合部署在笔记本电脑或智能手机等日常设备上。还需要持续确保这些模型安全运行,并进行适当的风险评估和内置保护措施。这些挑战促使人们寻找既高效又广泛可用的模型,而不会损害性能或安全性。
Google AI 发布 Gemma 3:开放模型合集
Google DeepMind 推出了 Gemma 3,这是一系列旨在应对这些挑战的开放模型。Gemma 3 采用与 Gemini 2.0 类似的技术开发而成,旨在在单个 GPU 或 TPU 上高效运行。这些模型有各种大小可供选择——1B、4B、12B 和 27B,并提供预训练和指令调整两种变体。这个范围允许用户选择最适合其硬件和特定应用需求的模型,让更广泛的社区更容易将 AI 纳入他们的项目中。
技术创新和主要优势
Gemma 3 在几个关键领域具有实际优势:
- 效率和可移植性:模型设计为在中等硬件上快速运行。例如,27B 版本在评估中表现出了强大的性能,同时仍然能够在单个 GPU 上运行。
- 多模式和多语言功能: 4B、12B 和 27B 模型能够处理文本和图像,使应用程序能够分析视觉内容和语言。此外,这些模型支持 140 多种语言,这对于服务全球多样化的受众非常有用。
- 扩展的上下文窗口: Gemma 3 拥有 128,000 个token(1B 模型为 32,000 个token)的上下文窗口,非常适合需要处理大量信息的任务,例如总结冗长的文档或管理扩展对话。
- 先进的训练技术:训练过程结合了来自人类反馈的强化学习和其他训练后方法,有助于使模型的响应与用户期望保持一致,同时保持安全性。
- 硬件兼容性: Gemma 3 不仅针对 NVIDIA GPU 进行了优化,还针对 Google Cloud TPU 进行了优化,使其能够适应不同的计算环境。这种兼容性有助于降低部署高级 AI 应用程序的成本和复杂性。
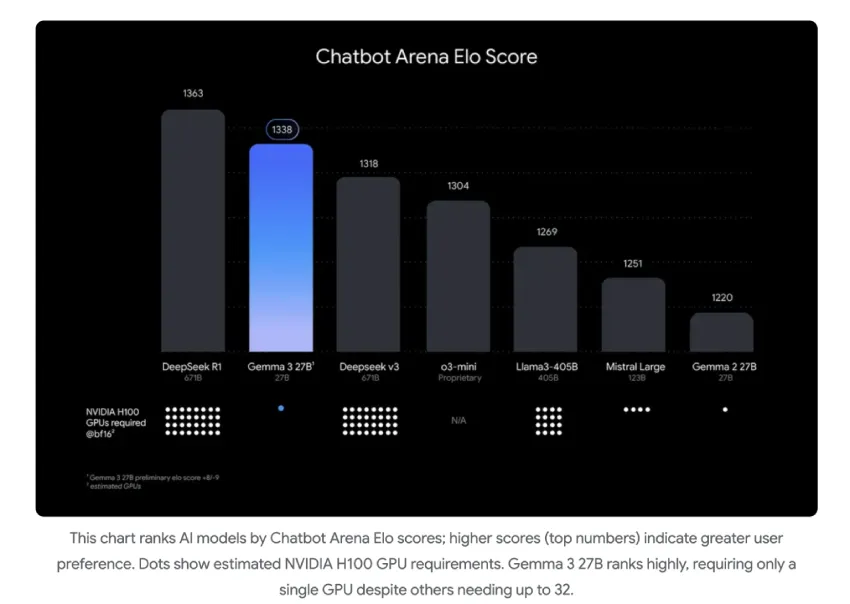
性能洞察与评估
Gemma 3 的早期评估表明,这些模型在其尺寸类别中表现可靠。在一组测试中,27B 变体在相关排行榜上获得了 1338 分,表明它能够在不需要大量硬件资源的情况下提供一致且高质量的响应。基准测试还表明,这些模型能够有效处理文本和视觉数据,这在一定程度上要归功于使用自适应方法管理高分辨率图像的视觉编码器。
这些模型的训练涉及大量多样的文本和图像数据集——最大变体多达 14 万亿个token。这种全面的训练方案支持它们处理从语言理解到视觉分析等各种任务的能力。早期 Gemma 模型的广泛采用,以及已经产生大量变体的活跃社区,凸显了这种方法的实用价值和可靠性。
结论:开放、可访问的人工智能的深思熟虑的方法
Gemma 3 代表着朝着让高级 AI 更易于访问迈出了谨慎的一步。这些型号有四种尺寸可供选择,能够处理 140 多种语言的文本和图像,提供了扩展的上下文窗口,并针对日常硬件的效率进行了优化。它们的设计强调了一种平衡的方法——提供强大的性能,同时纳入确保安全使用的措施。
从本质上讲,Gemma 3 是解决 AI 部署长期挑战的实用解决方案。它允许开发人员将复杂的语言和视觉功能集成到各种应用程序中,同时保持对可访问性、可靠性和负责任的使用方面的重视。
更多技术细节请查看:https://blog.google/technology/developers/gemma-3/
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
