
现有的大多数 LLMs 课程优先考虑具有丰富培训资源的语言,例如英语、法语和德语,而印地语、孟加拉语和乌尔都语等广泛使用但代表性不足的语言则受到的关注较少。这种不平衡限制了全球许多人口使用人工智能驱动的语言工具,导致数十亿人无法获得高质量的语言处理解决方案。要应对这一挑战,需要创新方法来训练和优化多语言法学硕士课程,以便在资源可用性各异的语言中提供一致的性能。
多语言 NLP 面临的一个关键挑战是语言资源分布不均。资源丰富的语言受益于广泛的语料库,而发展中地区的语言往往缺乏足够的训练数据。这一限制影响了多语言模型的性能,这些模型往往在文献丰富的语言中表现出更高的准确性,而在代表性不足的语言中则表现不佳。要解决这一差距,需要采用创新方法来扩大语言覆盖范围,同时保持模型效率。
有几种多语言 LLM 尝试解决这一挑战,包括 Bloom、GLM-4 和 Qwen2.5。这些模型支持多种语言,但其有效性取决于训练数据的可用性。它们优先考虑具有大量文本资源的语言,而对于数据稀缺的语言,其性能则不尽如人意。例如,现有模型在英语、中文和西班牙语方面表现出色,但在处理斯瓦希里语、爪哇语或缅甸语时却面临困难。此外,许多此类模型都依赖于传统的预训练方法,这些方法无法在不增加计算要求的情况下适应语言多样性。如果没有结构化的方法来提高语言包容性,这些模型仍然不足以满足真正的全球 NLP 应用。
阿里巴巴集团达摩院的研究人员推出了Babel,这是一款多语言 LLM ,旨在通过覆盖使用最广泛的 25 种语言来支持全球 90% 以上的使用者,以弥补这一差距。Babel 采用独特的层扩展技术来扩展其模型容量,而不会影响性能。研究团队推出了两种模型变体:Babel-9B,针对推理和微调效率进行了优化,Babel-83B 为多语言 NLP 树立了新标杆。与之前的模型不同,Babel 包括广泛使用但经常被忽视的语言,例如孟加拉语、乌尔都语、斯瓦希里语和爪哇语。研究人员专注于优化数据质量,通过实施严格的流程来从多个来源整理高质量的训练数据集。
Babel 的架构不同于传统的多语言 LLM,它采用了结构化层扩展方法。研究团队没有依赖需要大量计算资源的连续预训练,而是通过受控扩展增加了模型的参数数量。额外的层被战略性地集成在一起,以在保持计算效率的同时最大限度地提高性能。例如,Babel-9B 的设计旨在平衡速度和多语言理解能力,使其适合研究和本地化部署,而 Babel-83B 则扩展了其功能以匹配商业模型。该模型的训练过程采用了广泛的数据清理技术,使用基于 LLM 的质量分类器来过滤和细化训练内容。数据集来自各种来源,包括维基百科、新闻文章、教科书和结构化多语言语料库,如 MADLAD-400 和 CulturaX。
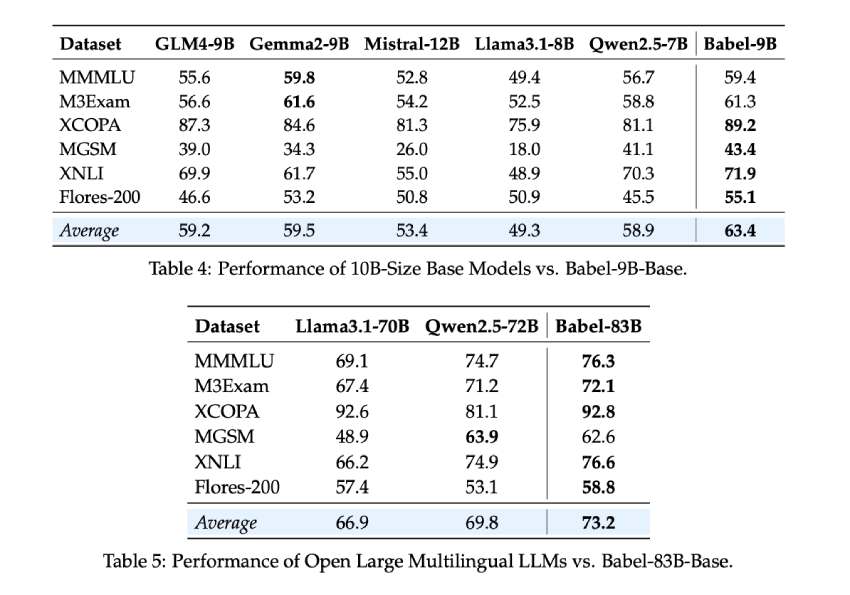
评估指标表明 Babel 优于现有的多语言 LLM。Babel-9B 在多个多语言基准测试中取得了 63.4 的平均分,优于 GLM4-9B(59.2)和 Gemma2-9B(59.5)等竞争对手。该模型在 MGSM 等推理任务中表现出色,得分为 43.4,在 Flores-200 等翻译任务中也取得了 55.1 分。同时,Babel-83B 在多语言性能方面树立了新标准,平均得分达到 73.2,超过了 Qwen2.5-72B(69.8)和 Llama3.1-70B(66.9)。该模型处理低资源语言的能力尤其显著,比之前的多语言 LLM 提高了 5-10%。此外,Babel 的监督微调 (SFT) 模型在超过 100 万个基于对话的数据集上进行了训练,其性能可与 GPT-4o 等商业 AI 模型相媲美。
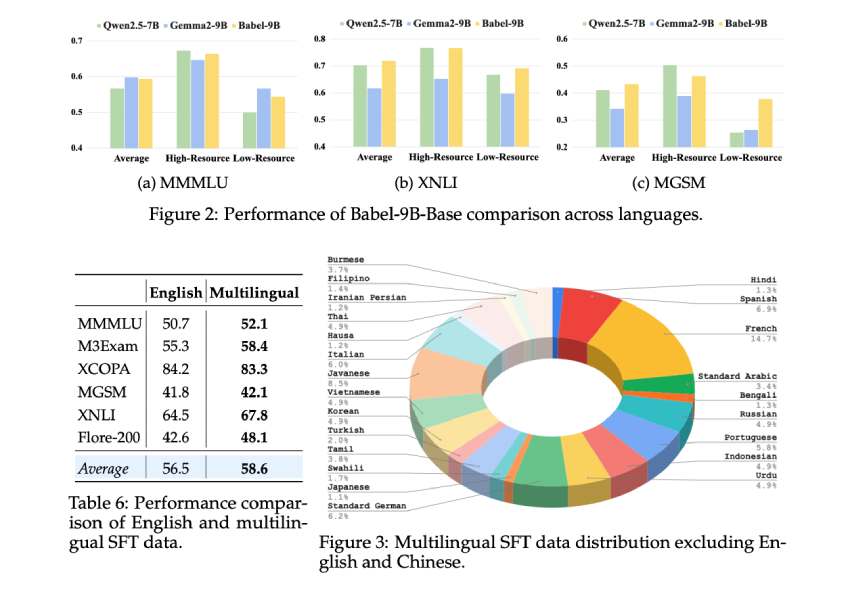
Babel 研究的一些关键要点包括:
- Babel 支持世界上使用最广泛的 25 种语言,覆盖全球 90% 以上的使用者。许多语言,例如斯瓦希里语、爪哇语和缅甸语,以前在开源法学硕士课程中代表性不足。
- Babel 不依赖传统的预训练,而是使用结构化层扩展技术来增加其参数数量,从而无需过多的计算要求即可增强可扩展性。
- 研究团队采用基于 LLM 的质量分类器实施了严格的数据清理技术。训练语料库包括 Wikipedia、CC-News、CulturaX 和 MADLAD-400,确保了较高的语言准确性。
- Babel-9B 的表现优于类似规模的模型,平均得分为 63.4,而 Babel-83B 则以 73.2 创下了新基准。这些模型在推理、翻译和多语言理解任务中表现出了最佳性能。
- Babel 显著提高了训练数据有限的语言的准确性,与现有的多语言 LLM 相比,其在代表性不足的语言中的表现提高了 10%。
- Babel-83B-Chat 的整体性能达到了 74.4,紧随 GPT-4o(75.1),同时优于其他领先的开源模型。
- 监督微调 (SFT) 数据集包含 100 万条对话,使得 Babel-9B-Chat 和 Babel-83B-Chat 能够在多语言讨论和解决问题方面与商业 AI 模型相媲美。
- 研究团队强调,进一步的增强,例如加入额外的对齐和偏好调整,可以进一步提升 Babel 的功能,使其成为更强大的多语言 AI 工具。
更多详细信息:https://github.com/babel-llm/babel-llm
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/56479.html
