
从大量未标记的图像中学习有用的特征非常重要,DINO和DINOv2等模型就是为此而设计的。这些模型非常适合图像分类和分割等任务,但它们的训练过程很困难。一个关键挑战是避免表示崩溃,即模型对不同的图像产生相同的输出。必须仔细调整许多设置以防止这种情况发生,这使得训练不稳定且难以管理。DINOv2试图通过直接使用负样本来解决这个问题,但训练设置仍然很复杂。正因为如此,改进这些模型或将它们用于新领域很困难,即使它们学习到的特征非常有效。
目前,学习图像特征的方法依赖于复杂且不稳定的训练设置。SimCLR 、SimSiam 、VICReg、MoCo和BYOL等技术试图发现有用的表示,但面临各种挑战。SimCLR和MoCo需要大批量和明确的负样本,这使得它们的计算成本很高。SimSiam 和BYOL尝试通过修改梯度结构来避免崩溃,这需要仔细调整。VICReg 会惩罚特征对齐和协方差,但不能有效解决特征方差问题。I-JEPA 和 C-JEPA 等技术专注于基于块的学习,但增加了复杂性。这些方法难以保持简单性、稳定性和效率,使训练复杂化并限制了灵活性。
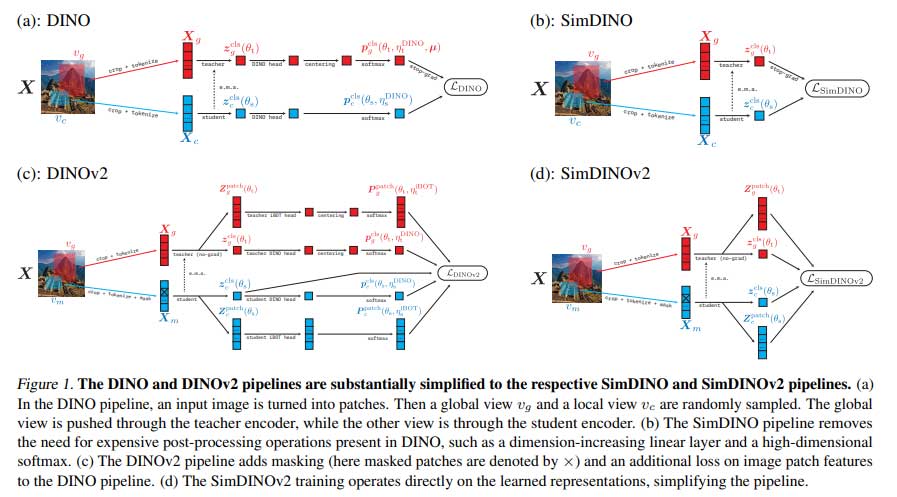
为了解决 DINO 的复杂性,加州大学伯克利分校、TranscEngram、微软研究院和香港大学的研究人员提出了SimDINO和SimDINOv2。这些模型通过将编码率正则化项纳入损失函数来简化训练,从而防止表示崩溃并消除了繁重的后处理和超参数调整的需要。通过避免不必要的设计选择,SimDINO 提高了训练的稳定性和效率。SimDINOv2 通过处理图像的小区域和大区域(无需应用高维变换)并消除师生范式来提高性能,使该方法比现有方法更稳健、更高效。
该框架通过直接控制特征表示来最大化学习效果,使其在整个训练过程中都很有用,而无需进行复杂的调整。编码速率项为模型提供了结构化和信息丰富的特征,从而提高了泛化能力和下游任务性能。这简化了训练流程并消除了师生范式。SimDINO 降低了计算开销,同时保持了高质量的结果,使其成为视觉任务中自监督学习的更有效替代方案。

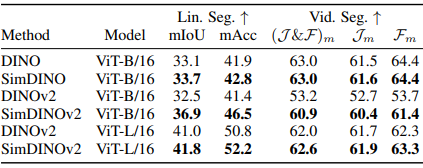
研究人员使用块大小为16 的ViT架构在ImageNet – 1K、COCO val2017、ADE20K和DAVIS – 2017上对 SimDINO 和 SimDINOv2 与 DINO 和 DINOv2 进行了评估。SimDINO 在保持稳定训练的同时实现了更高的 k-NN 和线性准确度,而 DINO 则表现下降。在 COCO val2017 上使用MaskCut进行物体检测和分割时,SimDINO 的表现优于 DINO。对于ADE20K上的语义分割,SimDINOv2在 ViT-B 上将DINOv2提高了4.4 mIoU 。在 DAVIS-2017 上,SimDINO 变体表现更佳,但由于评估敏感性,DINOv2 和 SimDINOv2 的表现不及前代产品。稳定性测试表明,DINO 对超参数和数据集变化更为敏感,在 ViT-L 上出现分歧,而 SimDINO 保持稳健,在 COCO train 2017 上训练时表现明显优于 DINO。
总之,提出的SimDINO和SimDINOv2模型通过引入与编码率相关的正则化项简化了 DINO 和 DINOv2 的复杂设计选择,使训练流程更加稳定和稳健,同时提高了下游任务的性能。这些模型通过消除不必要的复杂性,增强了 Pareto 相对于其祖先的优势,展示了直接处理视觉自监督学习中的权衡的优势。高效的框架为分析自监督学习损失的几何结构和无需自我蒸馏的模型优化奠定了基础。这些想法也可以应用于其他自监督学习模型,使训练更加稳定和高效,这使得 SimDINO 成为开发更好的深度学习模型的强大起点。
论文地址:https://arxiv.org/abs/2502.10385v1
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/56301.html
