
优化大规模语言模型需要先进的训练技术,以降低计算成本并保持高性能。优化算法对于确定训练效率至关重要,尤其是在具有大量参数的大型模型中。虽然像 AdamW 这样的优化器已被广泛采用,但它们通常需要细致的超参数调整和大量计算资源。寻找一种更有效的替代方案,既能确保训练稳定性,又能降低计算要求,对于推进大规模模型开发至关重要。
训练大规模模型的挑战源于计算需求的增加以及有效参数更新的必要性。许多现有的优化器在扩展到更大的模型时表现出效率低下,需要频繁调整,从而延长训练时间。稳定性问题(例如不一致的模型更新)会进一步降低性能。可行的解决方案必须通过提高效率并确保强大的训练动态来解决这些挑战,而无需过多的计算能力或调整工作。
现有的优化器(如 Adam 和 AdamW)依靠自适应学习率和权重衰减来改善模型性能。虽然这些方法在各种应用中都表现出色,但随着模型规模的扩大,它们的效果会逐渐减弱。它们的计算需求显著增加,使得它们无法进行大规模训练。研究人员一直在研究替代优化器,以提供更好的性能和效率,从而消除了进行大量超参数调整的需要,同时实现稳定且可扩展的结果。
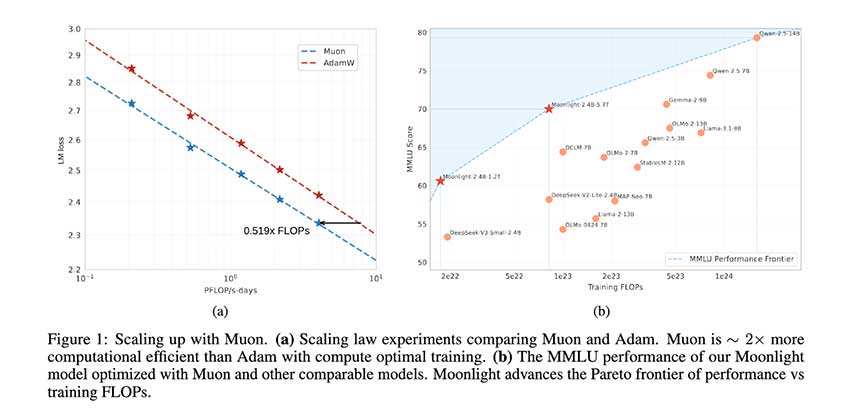
Moonshot AI 和加州大学洛杉矶分校的研究人员推出了 Muon,这是一种优化器,旨在克服现有方法在大规模训练中的局限性。Muon 最初在小规模模型中被证明是有效的,但在扩大规模方面面临挑战。为了解决这个问题,研究人员实施了两项核心技术:权重衰减以增强稳定性,以及一致的均方根 (RMS) 更新,以确保不同参数之间的统一调整。这些增强功能使 Muon 能够高效运行,而无需进行大量的超参数调整,使其成为开箱即用的大规模模型训练的有力选择。
基于这些进步,研究人员推出了 Moonlight,这是一种混合专家 (MoE) 模型,具有 3B 和 16B 参数配置。Moonlight 使用 5.7 万亿个 token 进行训练,利用 Muon 优化性能,同时降低计算成本。还使用 ZeRO-1 风格的优化开发了 Muon 的分布式版本,提高了内存效率并最大限度地减少了通信开销。这些改进带来了稳定的训练过程,使 Moonlight 能够以比以前的模型低得多的计算成本实现高性能。
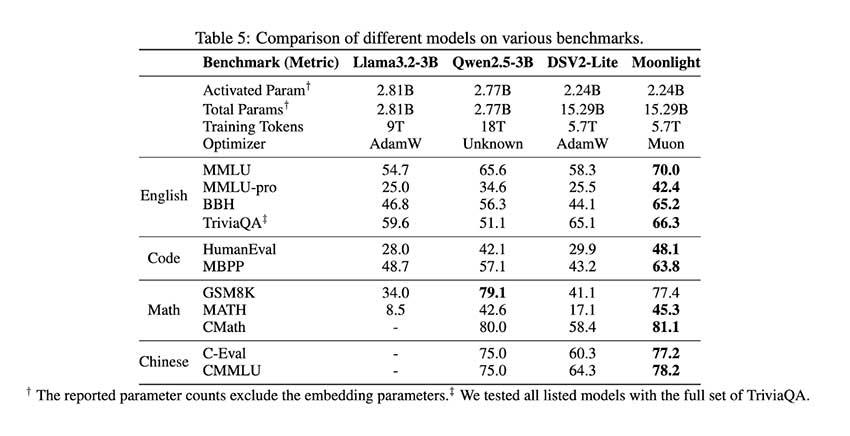
性能评估表明,Moonlight 的表现优于现有的同类规模的先进模型,包括 LLAMA3-3B 和 Qwen2.5-3B。缩放定律实验表明,Muon 的采样效率约为 Adam 的两倍,能够在保持竞争力的同时显著减少训练 FLOP。Moonlight 在多个基准测试中表现出色,在 MMLU 中取得了 70.0 分,超过了 54.75 分的 LLAMA3-3B 和 65.6 分的 Qwen2.5-3B。在更专业的基准测试中,Moonlight 在 MMLU-pro 中获得了 42.4 分,在 BBH 中获得了 65.2 分,突显了其增强的性能。该模型在 TriviaQA 中也表现出色,得分为 66.3,超越了所有同类模型。
Moonlight 在代码类任务中取得 HumanEval 48.1 分和 MBPP 63.8 分,在参数规模相近的模型中表现优异;数学推理任务中取得 GSM8K 77.4 分和 MATH 45.3 分,展现出卓越的问题解决能力;中文任务中也取得优异成绩,C-Eval 77.2 分和 CMMLU 78.2 分,进一步证明了其在多语言处理中的有效性。该模型在多项基准测试中的优异表现表明其强大的泛化能力,同时显著降低了计算成本。
Muon 的创新解决了训练大型模型的关键可扩展性挑战。通过结合权重衰减和一致的 RMS 更新,研究人员提高了稳定性和效率,使 Moonlight 能够突破性能界限,同时降低训练成本。这些进步巩固了 Muon 作为 Adam 优化器引人注目的替代方案的地位,无需大量调整即可提供卓越的样本效率。Muon 和 Moonlight 的开源进一步支持了研究界,促进了对大规模模型高效训练方法的进一步探索。
模型地址:https://huggingface.co/moonshotai
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/56227.html
