
摘要:在现有CDN中,很多的空间用于存储基于影视作品的流媒体文体,而这些文件很多内容一样,但编码方式、码率等不一样,重复存储浪费了大量存储空间,增加了运营成本。针对影视内容的流媒体文体,提出一种采集相邻 I 帧时间信息进行内容相似度识别的方法,可以有效解决基于不同编码方式、码率,但内容一致的流媒体文件的识别问题。
关键词:流媒体;相似;I 帧
中图分类号:TP37 文献标志码:A
引用格式:刘述, 孔玲, 田辉. 流媒体视频文件相似性识别的方法[J]. 信息通信技术与政策, 2022,48(10):87-90.
DOI:10.12267/j.issn.2096-5931.2022.10.013
0 引言
在进行内容分发网络(Content Delivery Network,CDN)项目时,甲方提出一个需求,CDN中的视频文件,特别是电影、电视剧等流媒体文件有大量的重复,同一内容在CDN中可能有多个副本,占用了大量的存储资源。如果减少这些重复文件的存储,对于降低CDN的运营成本会有非常大的帮助。基于此,本文提出一种采集相邻I帧时间信息进行内容相似度识别的方法。
1 常规的解决方法
对于甲方的需求,设备商提供了初步的解决方案,对于视频文件,设备商进行文件大小的比对,大小一致的文件可能是同一个视频文件。显然这种方法是非常粗糙的,在此不进行讨论。
进一步,设备商提供对视频文件进行摘要计算,凡是摘要一样的视频文件,虽然文件名不同,也可以认定是同一个视频文件。这种方法的优点是准确匹配,可以减少同一文件的副本数,但即使视频文件内容相同也会有多种差别,如每秒帧数可以是25 fps,也可以是30 fps;解析度可以是4K或1 080P等;视频编码可以是MPEG-2或H.264;配音的编码可以是MP3或ACC。此外,对视频文件加入内嵌字幕、水印或数字版权等信息,都会使视频文件的摘要发生变化。这种方法体现出的问题在于,针对上述不同配置相同内容的视频文件无法识别。
另一种解决方案是提取视频文件中一系列的画面来进行比对,该方案需要用到人工智能等技术,这类解决方案对于单一视频文件识别会有比较好的效果。对一个内容进行不断的训练,会使识别正确率不断提升,但是这样的解决方案过于复杂,需要计算资源和内存资源比较多,而且每识别一个新的内容都要重新进行训练。
2 新方案的提出和验证
本文提出一个新的视频文件相似度比对的方法,特别适用于影视内容的流媒体视频文件的识别。该方法的复杂度不高,但应用效果却非常理想。
2.1 基础知识
网上流媒体服务的成功,很大归功于视频压缩编码的运用。流媒体文件在编码时,通过画面信息的预测,大大减小了传输的数据量,实现的视频文件的压缩,使视频流媒体可以在互联网上传送。视频文件原始数据虽然数据量巨大,但邻近帧之间的差异很小,只需要传送这种帧间变化的信息就可以实现数据量的压缩。
目前,视频流媒体编码主要包括MPEG-2、H.264和H.265等,这些编码有很多相似之处,如帧内预测(Intra Prediction)、帧间预测(Inter Prediction)等手段[3]。
帧内预测帧使用帧内编码帧进行数据传送,该帧称为I帧,又称为内部画面(Intra Picture),经过适度压缩,作为随机访问的参考点。I帧特点:它是一个全帧压缩编码帧,信息量比之后的帧间预测帧信息量大;它将全帧图像信息进行JPEG压缩编码及传输,且独立于其他的图像类型;每个图像群组由此类型的图像开始,解码时仅用I帧的数据就可重构完整图像;在I帧之后都是对I帧进行补偿的帧,如前向预测帧P帧、双向预测帧B帧等。
笔者直观感到,在影视流媒体作品中,画面变化最剧烈的时候应该是镜头切换的时刻,这时流媒体中应会出现一个新的I帧,经过观测的视频文件的解码并对比视频播放,证明笔者的猜测是正确的。实际上,I帧也会出现在不是镜头切换的时刻,但是每当画面出现镜头切换时出现的I帧,都会标明是Key-I 帧。图1是视频文件开始的第一个I帧信息,表明这是一个Key-I 帧。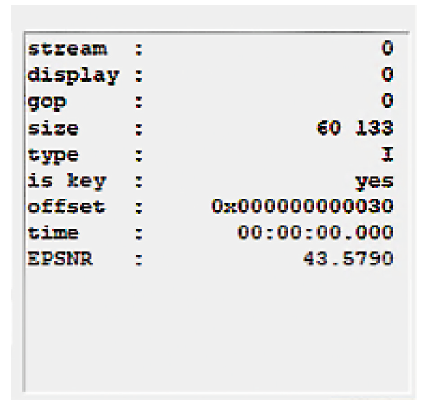
 图1 第一个镜头的第一个I帧信息
图1 第一个镜头的第一个I帧信息
2.2 新方案的提出和验证有了上述的验证,笔者提出了一个视频文件相似性比较的方法,这里有两个视频文件分别对视频文件Key-I帧出现的时间进行采样,各形成一个时间序列。再对这两个时间序列进行比较,最容易实现的比较方法是进行相关系数的计算,如果两个时间序列相关系数越接近1,说明两个时间序列一致性越强。时间序列代表了视频文件中镜头切换的时间,如果两个视频文件镜头切换的时间高度一致,可以初步判断两个视频文件为同一内容。为了证明此方法,笔者将同一个视频文件进行了新的格式编辑,文件1视频文件解析度为480P每秒20帧(见图2),文件2视频文件解析度为1 036P每秒30帧(见图3)。两个文件的帧分布进行比较,如图4所示,其中箭头标出的是前4个Key-I帧。
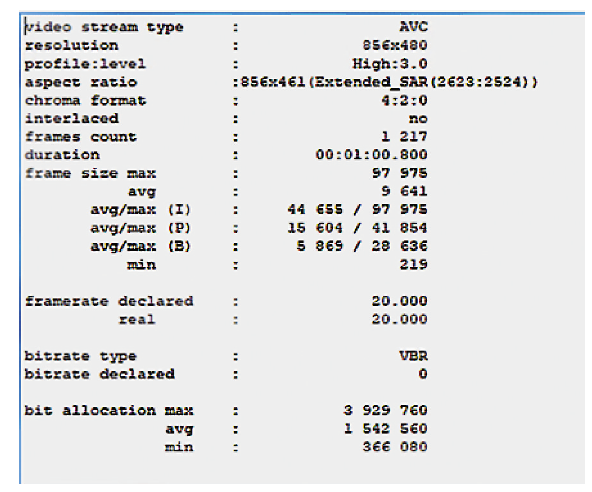
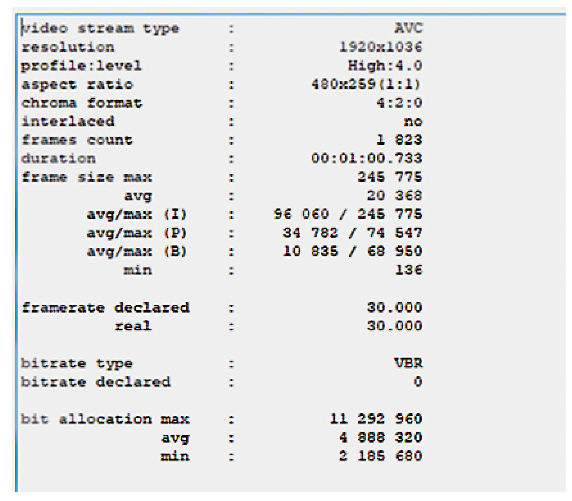 图3 1 036P.30 fps文件2的信息
图3 1 036P.30 fps文件2的信息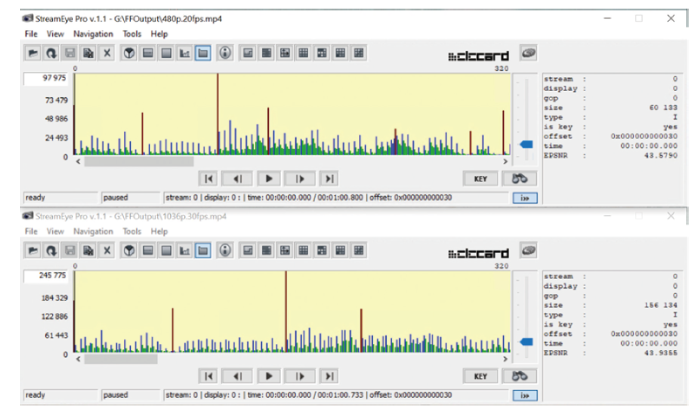 图4 文件1和文件2中Key-I帧出现时的比较
图4 文件1和文件2中Key-I帧出现时的比较
表1为提取两个视频文件前4个Key-I帧的出现时刻信息。表1 文件1和文件2中Key-I帧出现的时间序列
如果计算两个序列的线性相关度,相关系数为0.999961,说明两个序列的相关性非常高。由于两个视频文件中镜头切换的时刻高度一致,可以初步判断这两个视频文件是同一内容。
实践中也会常用相邻样本间的差做时间序列,以表1数据做差分计算为例,两镜头之间的时间差各形成一个序列(见表2)。表2 文件1和文件2中 Key-I帧的时间差的序列
计算这两个序列相关系数为0.99161,说明文件1和文件2中Key-I帧出现时刻高度一致。
3 结束语
本文提出的方案适用于时间较长的影视作品的比较。时间较长,I帧进行采样的样本数较多,结果会更加理想。目前,互联网上流行的短视频镜头切换较少,如果进行副本的识别应使用别的方法或方案。本文提出的两个视频文件比较的方法采用了相关系数的计算,相关系数计算对序列要求比较严格,如果视频文件中多插入或删除一两个镜头,则两个文件线性相关性会大大降低。在序列相似性比较或序列片段相似性比较的研究中,生物学中对基因序列的研究可以在进一步的研究中提供更多借鉴[1-2](注:本文中的数据采样使用Elecard公司的StreamEyes Demo版产品)。
参考文献
[1] 陈雪刚, 张家录, 程杰仁. 基于信息量的 DNA 序列相似性分析[J]. 计算机应用研究, 2013,30(5):1381-1384. [2] 刘兵, 柳菁筠, 李大超. 一种新的相似性度量及其在DNA 序列相似性分析中的应用(英文) [J]. 海南师范大学学报(自然科学版), 2009,22(1):21-26+41.
A method to identify the similarity of the contents of streaming video files
LIU Shu1, KONG Ling2, TIAN Hui1
(1. Technology and Standards Research Institute, China Academy of Information and Communications Technology, Beijing 100191, China; 2. People’s Liberation Army of China 93303 Unit, Shenyang 110069, China)
Abstract: In CDN, a lot of space is wasted for storage of those stream media files who have same content, but employdifferent CODEC or bit rate etc. This article presents a new method which identifies the similarity of the contentsbetween a group of streaming video files by the time information of adjacent I frames, and it works for those streammedia files just mentioned. Keywords: stream media; similarity; I frame
本文刊于《信息通信技术与政策》2022年 第10期
作者简介
刘述 中国信息通信研究院技术与标准研究所高级工程师,长期从事IP网络技术、软件测试、网络设备测试的研究工作 。
孔玲 中国人民解放军 93303 部队工程师,主要从事固定及便携移动通信设备的使用和维护工作 。
田辉 中国信息通信研究院技术与标准研究所互联网中心主任,长期从事数据通信领域标准和测评技术研究等工作。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。