
当前的图像标记化方法需要大量标记来捕获图像中包含的信息。尽管图像的信息量不同,但大多数图像分词器仅支持固定长度的分词化,导致分词分配效率低下。在本研究中,本文介绍了 One-D-Piece,一种专为可变长度分词化而设计的离散图像分词器,实现了质量可控机制。为了实现可变压缩率,本文将一种名为 “Tail Token Drop” 的简单但有效的正则化机制引入离散的一维图像分词器中。这种方法鼓励关键信息集中在标记序列的头部,从而支持可变参数标记化,同时保持最先进的重建质量。本文在多个重建质量指标上评估本文的分词器,发现它在较小的字节大小下提供的感知质量明显优于现有的质量控制压缩方法,包括 JPEG 和 WebP。此外,本文还在各种下游计算机视觉任务上评估了本文的分词器,包括图像分类、对象检测、语义分割和深度估计,证实了与其他可变速率方法相比,它对众多应用的适应性。本文的方法展示了可变长度离散图像标记化的多功能性,在压缩效率和重建性能方面建立了新的范式。最后,本文通过对分词器的详细分析来验证尾部分词掉落的有效性。
题目: One-D-Piece: Image Tokenizer Meets Quality-Controllable Compression
作者: Keita Miwa, Kento Sasaki, Hidehisa Arai, Tsubasa Takahashi, Yu Yamaguchi
论文链接: arXiv:2501.10064
来源:arxiv 2025
内容整理: 周楚骎
简介
近年来,随着视觉语言模型( vision language models,VLMs ) 和图像视频生成模型的快速发展,类似于语言标记化的视觉数据离散标记化的概念引起了越来越多的关注。该方法能够与基于Transformer的模型无缝集成,简化模型架构,降低计算复杂度。
然而,视觉数据的离散标记化仍然存在挑战,尤其是在捕获空间结构方面,这通常需要长而固定长度的标记序列。例如,典型的图像分词器(Tokenizer)需要多达 256 个token来表示单个 256×256 像素的图像,这限制了它们在实际应用中的灵活性。为了克服这一限制,出现了一维 (1D) 标记化方法,旨在在保持重建质量的同时实现更高的压缩率。值得注意的是,SEED 分词器 可以通过因果一维序列在语义上表示图像,而 TiTok 分词器 只需 32 个分词即可实现高质量的图像重建。这些方法有效地将整个图像编码为紧凑的 1D 序列,从而显著减少了所需的标记数量。然而,压缩率和重建质量之间存在基本的权衡;压缩率越高,降级程度越高,尤其是对于复杂图像。由于当前的图像分词器旨在产生固定数量的令牌,因此无法根据特定要求控制质量。
相比之下,JPEG 等经典图像压缩方法长期以来一直通过允许用户根据所需的质量调整压缩率来解决这种权衡。这些方法为平衡文件大小和视觉保真度提供了完善的机制,使其在各种应用程序中具有高度的通用性。然而,传统的压缩算法并不是为直接用作神经网络的输入表示而设计的,这使得将它们集成到 VLM 等神经模型中具有挑战性。此外,这些算法与现代图像分词器中使用的自适应、模型驱动策略有着根本的不同,这使得已建立的压缩技术向分词化领域的转移变得复杂。
鉴于这些差异,迫切需要一种新的方法,将标记化方法的适应性与传统压缩格式的效率联系起来。为了应对这一挑战,本文提出了 One-D-Piece,一种新的可变长度离散图像分词器,它结合了分词化的优势和经典压缩方法的灵活性。本文的方法引入了一种简单而有效的正则化技术 Tail Token Drop,它将关键信息集中在 Token 序列的开头,从而实现高效和自适应Token 长度范围为 1 到 256 个 Token。这允许在令牌数量较少的情况下保持高重建质量,从而提供适合各种应用的灵活压缩。如下面两图所示,本文的模型支持可变长度图像标记化,即使只有 8 或 16 个标记,也可以有效地产生视觉上准确的标记化和重建。


本文不仅使用标准图像质量指标进一步评估了本文的方法,还通过评估其在一系列下游任务上的性能,展示了优于经典图像压缩技术的实际优势。本文通过对各种计算机视觉任务(包括图像分类、对象检测和语义分割)进行广泛实验来展示 One-D-Piece 的有效性。本文的结果表明,One-D-Piece 在感知质量方面优于现有的可变长度压缩方法,包括 JPEG、JPEG 2000和 WebP,尤其是在低令牌数量时。
本文的贡献总结如下:
- 本文介绍了 One-D-Piece,这是一种可变长度的离散图像分词器,利用了一种新颖的 Tail Token Drop 正则化技术。
- 本文的方法实现了有竞争力的重建质量,同时支持灵活的令牌长度,使其成为满足不同压缩需求的多功能解决方案。
- 本文通过对感知质量和下游任务性能的全面评估来验证本文的方法,证明了它优于传统的图像压缩方法。
- 本文详细分析了模型的行为,揭示了本文的 Tail Token Drop 方法可以有效地将重要信息集中在头部。
方法
本文介绍了 One-Dimensional Image Piece Tokenizer (One-D-Piece),这是一种专为高效图像压缩而设计的新型离散分词器。与通常生成固定长度序列的现有图像分词器相比,OneD-Piece 生成可变长度的词元,类似于 WordPiece 和 SentencePiece 等文本分词器。
Tail Token Drop
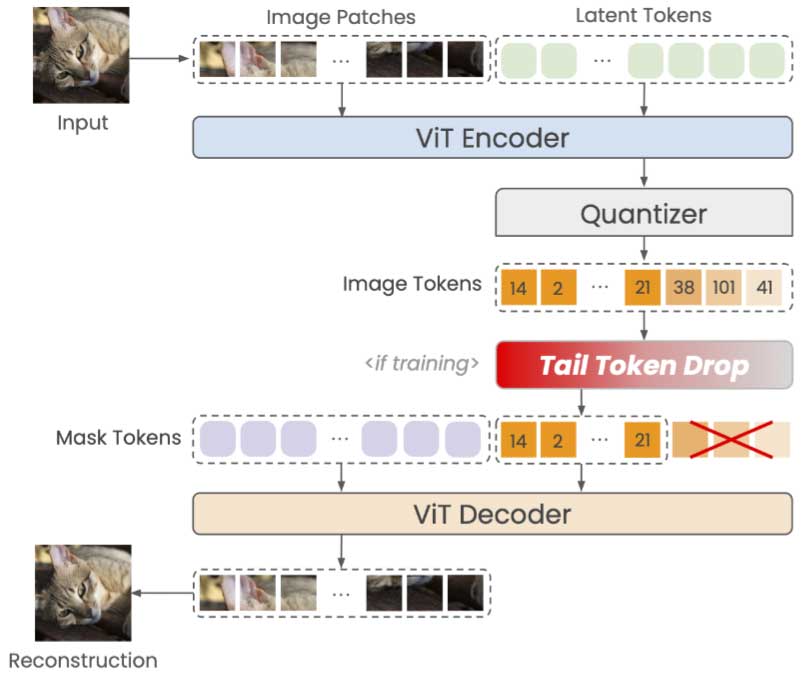
最初引入一种称为 “tail drop” 的正则化技术,通过动态控制潜在表示的维数来提高压缩效率。Tail drop 可以看作是 Dropout 的一种变体,其中 dropout 率在潜在向量的末端(尾部)逐渐增加。此技术优先考虑学习早期(头部)神经元中最重要的特征,同时逐渐丢弃尾部中不太关键的信息。因此,tail drop 实现了灵活的压缩,其中可以在推理时调整维度,同时控制重建的质量。
本文通过修改将这种简单而有效的图像标记化方法进行了调整,引入了“Tail Token Drop”,它涉及随机截断标记序列的尾部,并且可以应用于 1D 标记器,从而产生无结构的图像标记。
形式上,设 q = [ q1,q2,…,qN] 是本文的 1D 分词器生成的分词序列,其中 qi 表示序列中的每个分词,N 是分词的总数。在训练期间,要从均匀分布中采样要丢弃的令牌数 k:k ~ U(0,N-1)。
因此,应用 Tail Token Drop 后的标记序列(表示为 q′)由下式给出:
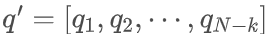
通过应用这种正则化,鼓励分词器通过在尾端随机截断标记来在序列开始时积累更多关键信息,而不太重要的信息往往在结束时积累,这更有可能被截断。因此,使用 Tail Token Drop 技术训练的分词器允许通过自适应地切割尾部,根据图像的信息内容灵活地调整分词序列长度。
架构
One-D-Piece 的架构侧重于两个重要需求。首先,生成的令牌必须形成一个 1D 序列。它们不应该像大多数 2D 分词器那样明确对应于 2D 结构。存在此限制是因为无法为 2D 令牌定义 tail,从而阻碍了 Tail Token Drop 的应用。其次,detokenizer 必须处理可变长度的令牌;否则,无法应用 Tail Token Drop 技术。

训练
本文们使用 TiTok 采用的两阶段训练策略。在第一阶段,该模型经过训练,可以使用交叉熵损失来预测预训练分词器的 logits。第二阶段涉及训练模型在第一阶段学习 logits 后重建图像本身。在这里,预训练的分词器被合并到解码器中,而编码器保持冻结状态。然后使用重建损失对模型进行优化。损失函数包括减少失真的 L2 损失,以及用于提高视觉质量的感知损失和 GAN 损失。为了支持可变长度的标记化,本文在训练期间应用 Tail Token Drop 来动态调整标记长度。对于每个批次,将统一采样从 1 到 256 的索引(表示最小值到最大值),并截断超出此索引的标记。
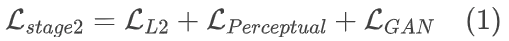
训练和评估均使用 ImageNet-1K 数据集进行,该数据集包含 1,000 个对象类、1,281,167 个训练图像、50,000 个验证图像和 100,000 个测试图像。
实验
这些实验的主要目标是评估本文的 One-D-Piece 在不同设置下的有效性,包括重建质量,以及各种下游任务。通过与包括 JPEG、JPEG 2000 和 WebP 在内的压缩算法以及现有的图像分词器进行比较,本文展示了本文方法的优势。
本文训练 One-D-Piece 模型时,每张图像最多使用 256 个标记。为了探索不同的模型复杂性,本文训练了三个变体,S-256、B-256 和 L-256,它们在 Vision Transformer 的参数大小上有所不同。超参数设置严格遵循 TiTok 使用的超参数设置。
训练分两个阶段进行:第一阶段在 ImageNet-1K 上进行 100 个时期,然后是第 2 阶段的 200 个时期。本文使用 8 个 NVIDIA H100 80 GB GPU。训练时间因模型复杂度而异:S-256 大约需要 5 天,B-256 大约需要 6 天,L-256 大约需要 9 天。这种差异反映了较大模型的参数数量和计算需求的增加。
重建
本文评估了 One-D-Piece 模型的三种变体的重建质量,并将它们与其他图像分词器和标准图像格式进行比较。
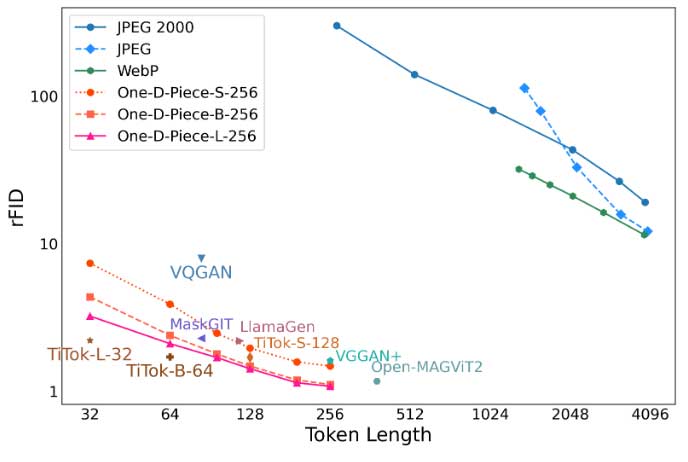
下表包括本文的主要指标,用于评估感知质量的 FID,以及用于测量失真的 PSNR。与其他图像分词器相比,本文的模型表现出足够好的性能,B-256 和 L-256 变体在 256 个分词时实现了最低的 rFID 分数,分别为 1.11 和 1.08。
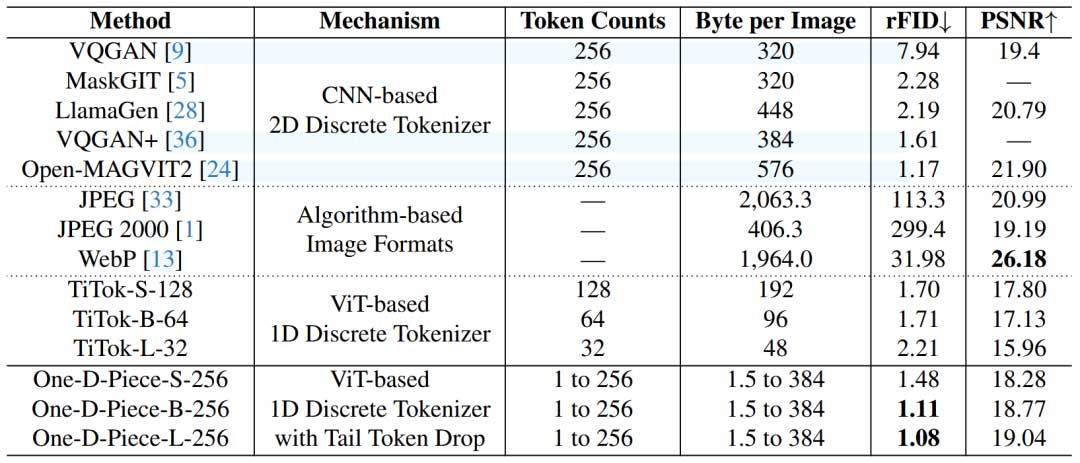
对于图像格式,本文控制了质量设置,以使每张图像的平均字节数与本文的模型保持一致。具体来说,本文使用每个令牌 1.5 字节(12 位)的速率将令牌计数转换为字节。对于 JPEG 和 WebP,本文使用了最低质量设置来最小化字节大小。对于 JPEG 2000,本文验证了 0.002 的目标压缩率产生的平均字节大小为 406.3,与本文具有 256 个令牌的模型相当。值得注意的是,与神经图像分词器(包括本文的模型)相比,这些传统图像格式在 rFID 指标上表现不佳。
值得一提的是,PSNR 指标显示出相反的趋势;与图像格式相比,本文的模型表现出相对较低的性能。这是因为本文模型的训练目标,包括 GAN 损失和感知损失,专注于提高感知质量,而不是减少像素级失真。该结果说明了速率-失真-感知权衡。尽管如此,与这些支持可变长度标记化的图像格式相比,本文的标记器表现出更好的感知质量。
为了检查令牌长度变化时的重建质量,本文在下图中提供了 rFID 图。随着更多代币的出现,rFID 稳步提高,与基于算法的图像压缩格式相比,本文的模型表现出更好的效率。本文还将模型的 rFID 与下表 中的 TiTok 变体进行了比较。虽然本文的模型以 256 个令牌表现出最低的 rFID,但对于等效模型大小,本文的模型在 32、64 和 128 个令牌计数上与 TiTok 不匹配。本文将这一结果归因于 Tail Token Drop 的引入。这凸显了在较小 token 大小下提高感知质量的挑战,但本文将其留给未来的探索。
分析
第一个令牌对全局信息进行编码
虽然本文对 token 贡献的分析证实,更重要的信息集中在 head token 中,但这些信息的实际内容仍不清楚。为了定性地研究这一点,本文按第一个标记进行聚类并显示结果。
下图(A) 说明了 ImageNet 验证拆分,由第一个标记聚类。可以观察到,第一个标记捕获图像之间的整体相似性,表明它们包含有关图像的全局信息。此外,本文发现替换第一个标记会导致重建图像发生相应的变化,如下图 (B) 所示。虽然这种影响随着标记序列的延长而减弱,但在序列较短的重建中可以看到显着的影响。

One-D-Piece 的token更具语义性
本文的分析表明,Tail Token Drop 有效地将全局信息聚合到标记序列的头部,其中前导标记捕获图像的整体相似性。为了进一步检查 One-D-Piece 标记的语义行为,本文遵循 TiTok 报告 中使用的 MAE 协议,通过线性探测实验进行了分析。具体来说,本文为 One-D-Piece 编码器的输出附加了一个线性分类器,并针对 ImageNet-1K 分类任务对其进行训练。该评估测量编码表示的线性可分性,表明潜在特征捕获语义信息的能力。
与预训练的 TiTok 模型相比,本文的模型实现了卓越的线性探测精度。有趣的是,这一结果与 TiTok 的说法形成鲜明对比,据报道,由于潜在空间中的约束更强,最大潜在标记较少的模型获得了更好的准确性。本文将这种相反的结果归因于本文的 Tail Token Drop 技术,该技术通过丢弃信息较少的尾部标记来有效地模拟紧凑潜在空间的好处。这一结果进一步凸显了 Tail Token Drop 方法促进全球信息聚合的有效性。
总结
本文引入了 One-D-Piece,这是一种能够进行质量控制标记化的离散图像标记器,旨在解决仅支持固定数量标记的现有图像标记化方法的压缩率和重建质量之间的权衡问题。本文的方法通过采用 “Tail Token Drop” 技术来支持从 1 到 256 的动态令牌计数,该技术将关键信息集中在序列的开头。即使使用较少的标记,也能实现高重建质量,在同等字节大小下,与 JPEG 等传统方法相比,感知质量得到了显著提高。
ImageNet-1K 上的实验结果验证,OneD-Piece 不仅在 256 个标记上实现了 1.08 的 rFID,超越了以前的方法,而且在各种下游任务中都表现出色,包括图像分类、对象检测和语义分割。本文的详细分析验证了 Tail Token Drop 正则化的有效性,它鼓励模型将重要信息集中在序列的头部。这些结果突出了 One-D-Piece 作为适用于各种计算机视觉应用的高效自适应分词器的潜力。通过启用可变长度标记化,本文的模型在压缩效率和质量方面树立了新的标杆,在视觉语言模型以及图像和视频生成任务中提供了有前途的应用。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
