
大型语言模型 (LLM) 预训练的主要方法依赖于下一个标记预测,这种方法已被证明可以有效捕捉语言模式。然而,这种方法也有明显的局限性。语言标记通常传达的是表层信息,需要模型处理大量数据才能开发出更深层次的推理能力。此外,基于标记的学习难以捕捉长期依赖关系,这使得需要规划和抽象的任务更加困难。研究人员已经探索了替代策略,例如知识提炼和结构化输入增强,但这些方法并没有完全解决基于标记的学习的局限性。这引出了一个重要的问题:LLM 能否以将标记级处理与概念理解相结合的方式进行训练?Meta AI 引入了连续概念混合 (CoCoMix)作为一种潜在的解决方案。
CoCoMix:一种不同的预训练方法
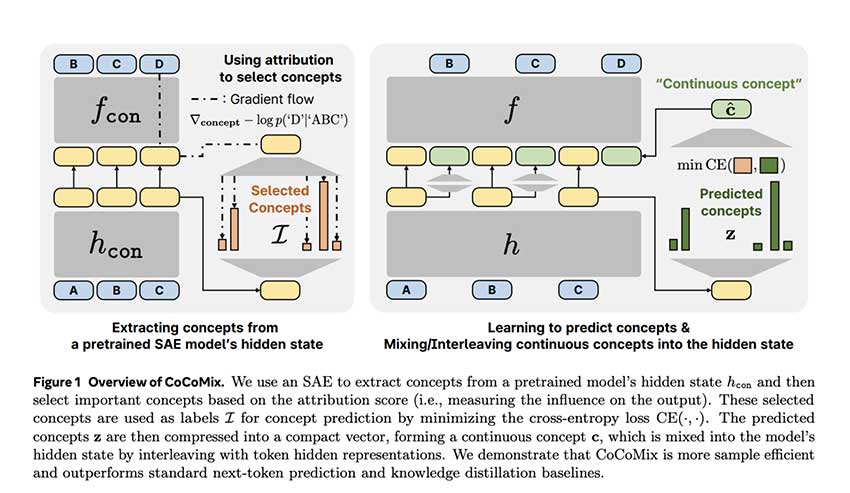
CoCoMix 将 token 预测与从预训练模型的隐藏状态中得出的连续概念建模相结合。该方法采用稀疏自动编码器 (SAE)来提取高级语义表示,然后通过将它们与 token 嵌入交织在一起来将其纳入训练过程。这种设计使模型能够保留基于 token 的学习的优势,同时增强其识别和处理更广泛概念结构的能力。通过使用概念级信息丰富基于 token 的范式,CoCoMix 旨在提高推理效率和模型可解释性。
技术细节和优势
CoCoMix 通过三个主要组件运行:
- 通过稀疏自动编码器 (SAE) 进行概念提取:预训练的 SAE 从模型的隐藏状态中识别潜在语义特征,捕获超出单个标记的信息。
- 概念选择与归因评分:并非所有提取的概念都对预测有同等贡献。CoCoMix 采用归因方法来确定哪些概念最具影响力且应予以保留。
- 将连续概念与标记表示交错:选定的概念被压缩为连续向量,并与标记嵌入一起集成到隐藏状态中,从而允许模型同时利用标记级和概念信息。
这种方法提高了样本效率,使模型能够以更少的训练标记实现相当的性能。此外,CoCoMix通过允许检查和调整提取的概念来增强可解释性,从而更清楚地了解模型如何处理信息。

性能与评估
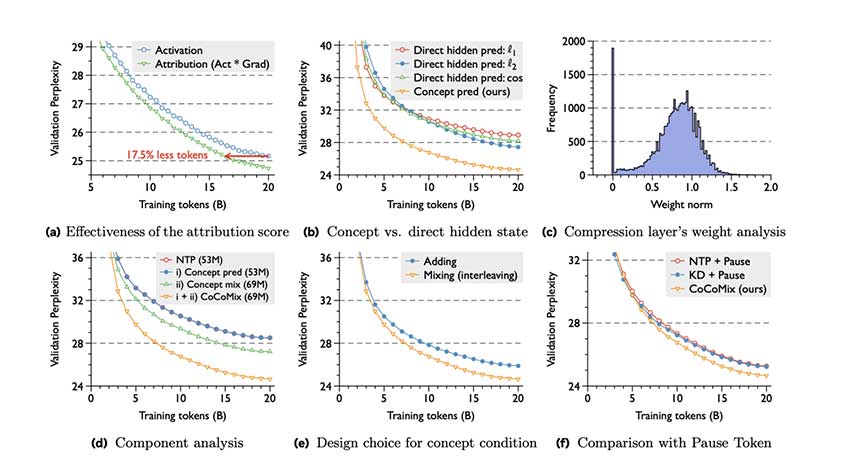
Meta AI 通过多个基准评估了 CoCoMix,包括 OpenWebText、LAMBADA、WikiText-103、HellaSwag、PIQA、SIQA、Arc-Easy 和 WinoGrande。研究结果表明:
- 提高样本效率:CoCoMix 匹配下一个标记预测的性能,同时需要的训练标记减少了 21.5%。
- 增强的泛化能力:在各种模型大小(69M、386M 和 1.38B 参数)中,CoCoMix 在下游任务性能方面表现出持续的改进。
- 有效的知识转移:CoCoMix 支持从小模型到大模型的知识转移,其表现优于传统的知识提炼技术。
- 更高的可解释性:连续概念的整合使得模型决策具有更大的控制力和透明度,从而可以更清楚地理解其内部过程。
结论
CoCoMix 通过将 token 预测与基于概念的推理相结合,提出了一种 LLM 预训练的替代方法。通过结合通过 SAE 提取的结构化表示,CoCoMix 提高了效率和可解释性,而不会破坏底层的下一个 token 预测框架。实验结果表明,这种方法提供了一种平衡的方式来改进语言模型训练,特别是在需要结构化推理和透明决策的领域。未来的研究可能侧重于改进概念提取方法,并进一步将连续表示集成到预训练工作流程中。
更多详细信息请查看:https://github.com/facebookresearch/RAM/tree/main/projects/cocomix
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/55858.html
