
内容摘要: 随着3D显示和虚拟现实的日益普及,多视角视频成为一种极具前景的格式。然而,其高分辨率和多相机拍摄导致数据量大幅增加,使得存储和传输成为一项具有挑战性的任务。为了解决这些困难,我们提出了一种隐式-显式集成的多视角视频压缩表示方法。具体来说,我们首先使用基于显式表示的2D视频编解码器对其中一个源视角进行编码。随后,我们提出使用基于隐式神经表示(INR)的编解码器对剩余的视角进行编码。隐式编解码器以多视角视频的时间和视角索引作为坐标输入,并生成相应的隐式重建帧。为了增强压缩性能,我们在隐式编解码器中引入了多级特征网格嵌入和全卷积架构。这些组件分别促进了坐标-特征和特征-RGB的映射。为了进一步提高INR编解码器的重建质量,我们利用显式编解码器生成的高质量重建帧进行视角间补偿。最后,将补偿结果与INR生成的隐式重建结果融合,得到最终的重建帧。我们提出的框架结合了隐式神经表示和显式2D编解码器的优势。在公开数据集上进行的大量实验表明,所提出的框架在视角压缩和场景建模方面能够达到甚至优于最新的多视角视频压缩标准 MIV 和其他基于 INR 的方案。
论文名称: Implicit-explicit Integrated Representations for Multi-view Video Compression
作者及机构: Chen Zhu, Guo Lu, Bing He, Rong Xie, Li Song, Medialab@SJTU
项目主页: https://github.com/zc-lynen/MV-IERV
论文链接: https://ieeexplore.ieee.org/document/10871929
整理人: 何冰
体积视频压缩背景
背景概述
体积视频是近期出现的一种基于体素的三维视频显示技术。为了生成体积视频,需要使用多个摄像机从不同角度对场景中物体的形状进行捕捉。相较于传统的二维视频,体积视频的一大显著特征是其庞大的数据量,这已成为限制其应用的一个关键因素。具体而言,体积视频的数据规模是二维视频的几十倍之多,这对存储系统和传输网络提出了极高的要求。因此,开发高效、先进的体积视频编码压缩技术对于推动相关应用具有决定性意义。当前国内外关于体积视频编码的研究可以分为两类:基于显式表达的方法和基于隐式神经表达(Implicit Neural Representation,INR,简称为隐式表达)的方法。
显式方法
基于显式表达的方法通过在三维空间中手工建立一个参数化的函数来捕获和压缩场景的结构和光照等属性,其中的代表性算法包括:基于体素的算法、基于网格的算法、点云算法。国际标准化组织MPEG在此领域尤为活跃,已推出一系列三维视频编码标准,包括文献[1]中的基于几何的点云压缩(Geometry-based Point Cloud Compression,G-PCC)和基于视频的点云压缩(Video-based Point Cloud Compression,V-PCC()),以及文献[2]中的 MPEG 沉浸式视频(MPEG Immersive Video,MIV)。G-PCC将点云表示为物体表面的三角形网格,并对网格模型进行分层编码。V-PCC将点云数据转化为二维几何和属性图像,然后进行二维编码压缩。MIV则将多个源视角内容打包到一个二维视频中,这个视频可以通过任意的二维编码器进行处理,比如HEVC和VVC。显式表达方法的压缩效率高,但是计算过程较为复杂。
隐式方法
基于隐式表达的方法聚焦于利用神经网络来刻画场景的颜色分布和不透明度特性。其中,神经辐射场(Neural radiance fields,NeRF)[3]是最具代表性的工作,它能够将给定观察方向的3D位置坐标映射至相应的颜色和体积密度值,并且使用神经网络对整个静态场景内容进行统一表征。在文献[4]中,Wang等人在NeRF的基础上提出了面向动态场景的隐式表达方法。隐式表达方法已展现出强大的模型表现力,然而,此类方法所面临的一项挑战是如何兼容现有成熟的视频编码框架并提升三维压缩效率。
核心思想
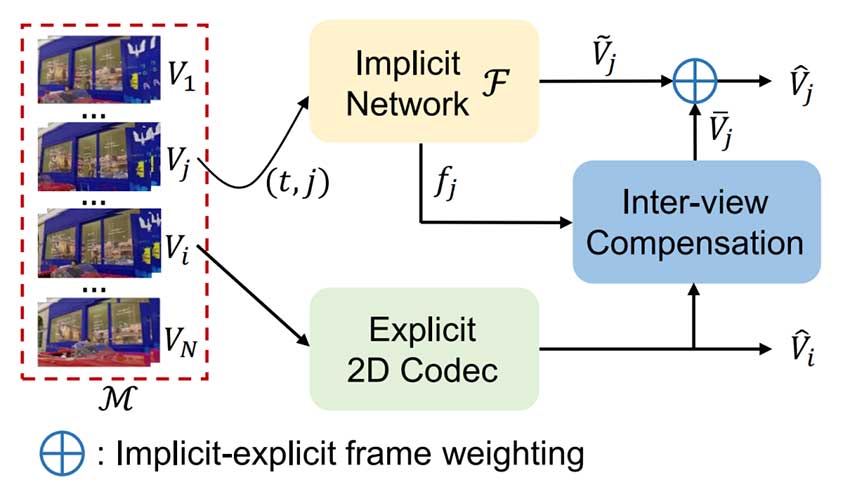
显式表示:使用现有的2D视频编解码器(如HEVC或VVC)对其中一个源视角进行编码,生成高质量的重建帧。
隐式表示:使用隐式神经表示(INR)对剩余的视角进行编码。INR以时间和视角索引作为输入,生成隐式重建帧。
视角间补偿:利用显式编码生成的高质量重建帧,通过视角间运动补偿提升隐式重建的质量。
特征网格嵌入:引入多级特征网格和全卷积架构,增强隐式网络的表达能力,提升压缩效率和重建质量。
具体实现
视角选择与显式压缩
通过深度图质量评估选择 基本视角(即显式编码的视角)。该部分继承 MIV 工作的相关部分,通过统计任一视角的深度图在其它视角下的一致像素比例来评估深度图的可靠性。
使用2D视频编解码器(如HEVC)对基本视角进行显式压缩,生成高质量的显示重建帧。
隐式神经网络的构建
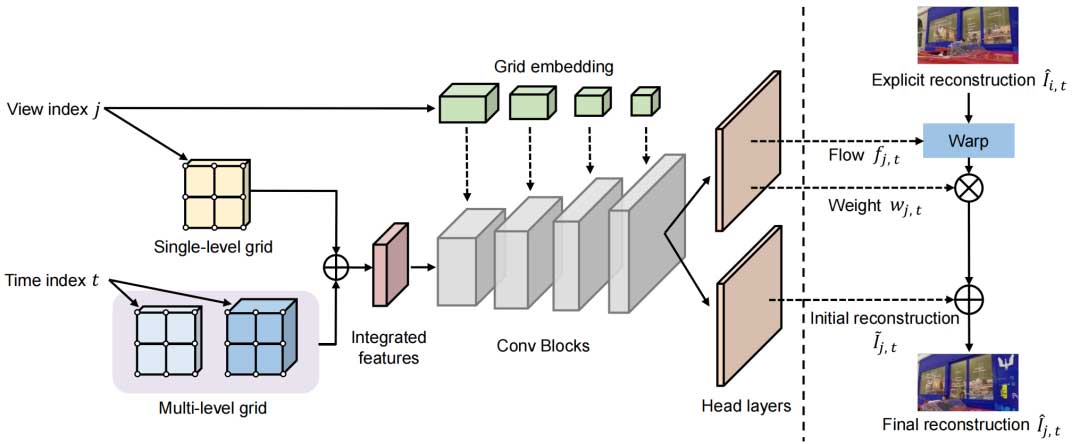
输入:时间和视角索引 (t, j)。
特征网格:使用多级时间网格 gti和视角网格 gvi捕捉时空和视角特征。通过加法调制将时间和视角特征融合,生成综合特征 feaint。
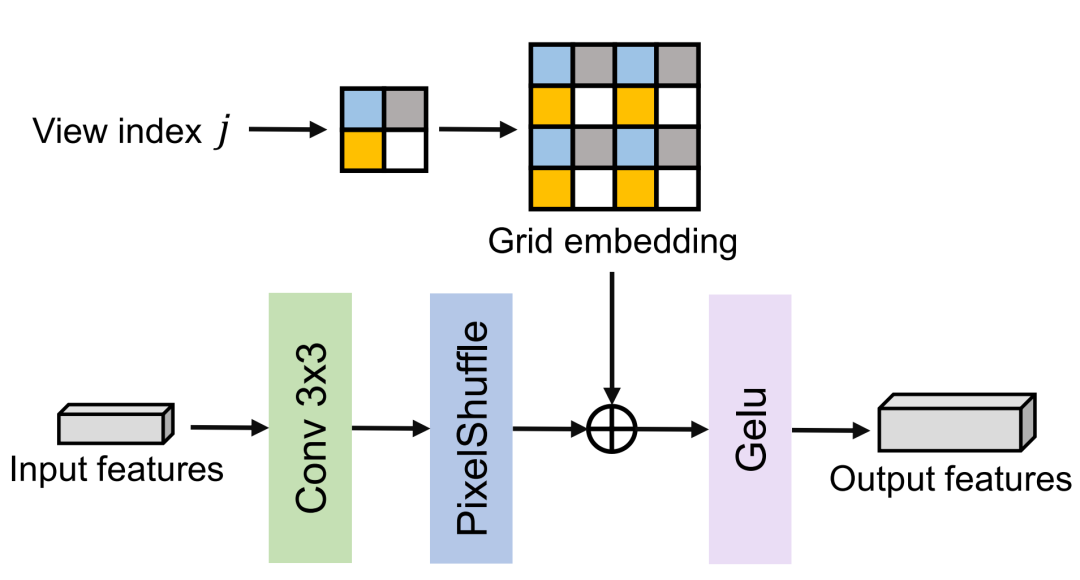
卷积结构:设计了一个包含多个上采样层和卷积块的网络,逐步将综合特征映射为高分辨率视频帧。在每个卷积块中嵌入可训练的特征网格 gem,增强网络的表达能力。
输出:生成初始的隐式重建帧。
视角间补偿
从隐式网络中提取稠密运动信息 fj 和稠密的权重信息wj 。使用运动信息对显式重建帧进行视角间运动补偿,生成补偿帧。将补偿帧与初始隐式重建帧融合,生成最终重建帧:
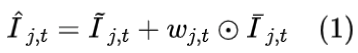
其中无上标表示真实帧,^ 表示最终重建帧,~ 表示隐式重建帧,- 表示显示重建帧。
训练损失函数
使用联合损失函数(L1损失和SSIM损失)优化隐式网络和视角间补偿模块。损失函数的严密表达如下:
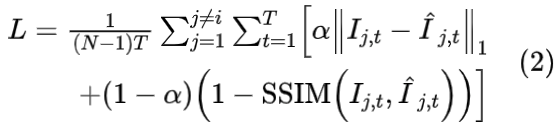
注意显示表示的视角不参与优化,因此分母中的因子为 (N-1)。
模型压缩
剪枝:给定剪枝比例,通过统计确定剪枝阈值,大小小于阈值的权重被置零。
量化:训练时使用量化感知 STE 方法,将浮点数在 tanh(·) 函数上均匀量化至 8 位。
熵编码:使用霍夫曼无损编码。
实验
数据集
实验在 MIV 标准数据集[5]上进行,每个多视角视频序列有 10-25 数量的相机,分辨率为 1920×1080。我们在前 100 帧上比较各个方法的有效性。另外我们还在 D-NeRF 数据集[6]上执行了实验,每个序列有 100-200 个视角,分辨率为 800×800.
实现细节
通过Adam优化器进行训练,学习率设置为0.0005,训练300个epoch。对于 1080p 的视频,特征网格的尺寸设置为 9,16,升采样因子设置为5,3,2,2,2。对于 800×800 的视频,特征网格尺寸设置为 10,10, 升采样因子设置为 5,2,2,2,2。损失函数中的 α 设置为 0.7 ,剪枝率设置为 0.4
R-D曲线与表格一览
高效压缩:相比传统的多视角视频压缩方法(如MIV),论文方法在相同重建质量下能够节省约37%的比特率。
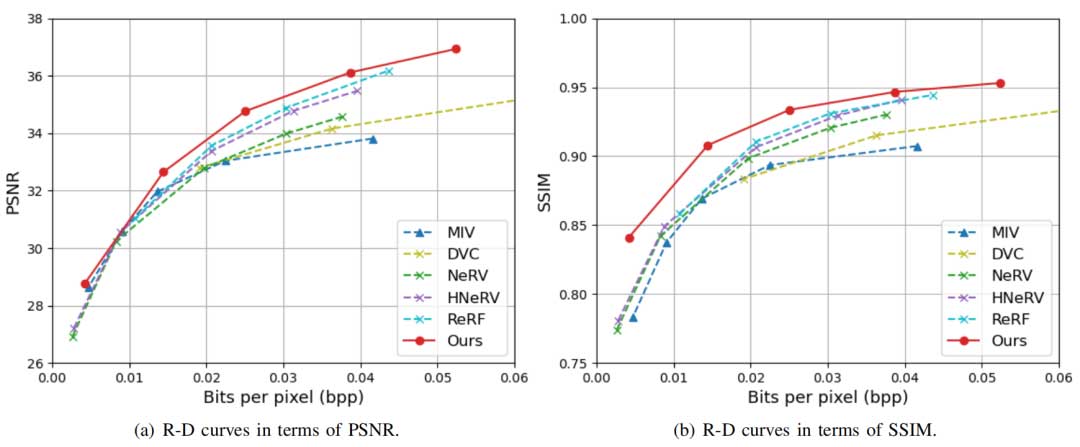
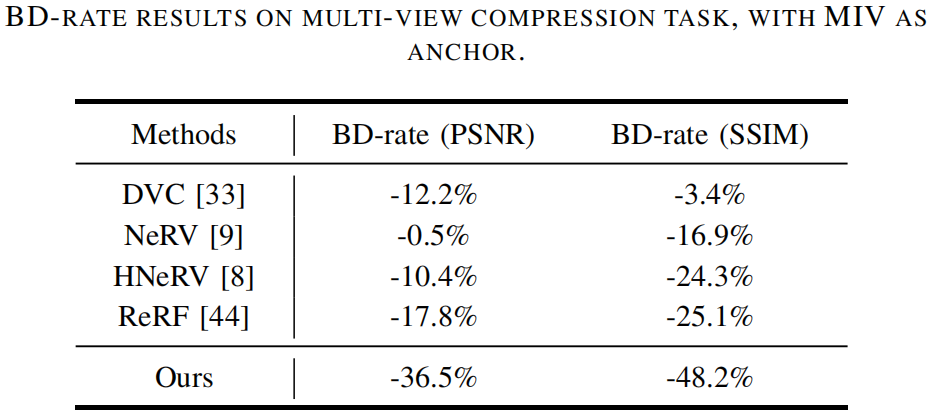
主观结果


隐式网络性能比较
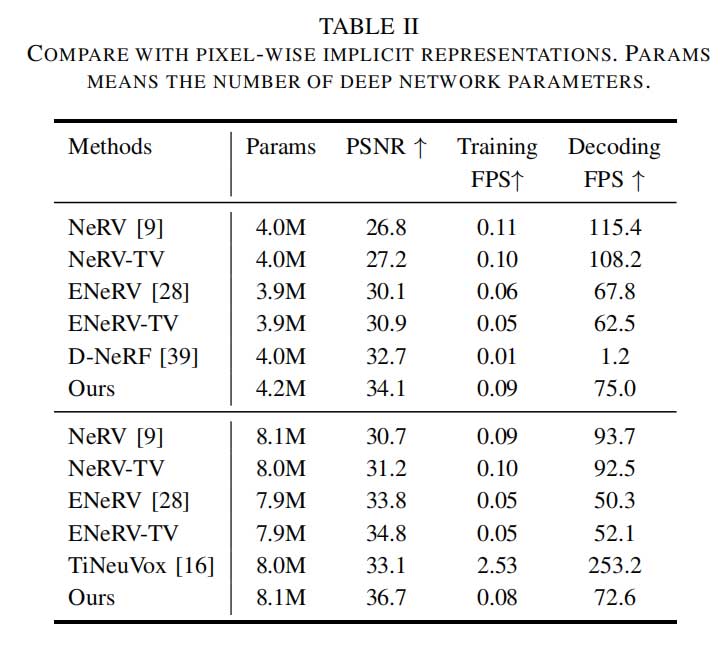
多维特征网格
多维特征网格包括时间网格(Grid-Fea-T)和视角网格(Grid-Fea-V),用于捕捉多视角视频中的时空和视角特征。
实验设置:移除时间网格(w/o Grid-Fea-T):仅使用视角网格。移除视角网格(w/o Grid-Fea-V):仅使用时间网格。移除所有特征网格(w/o Grid-Fea):使用全局共享的网格。
实验结果:移除时间网格导致PSNR下降约6.6 dB。移除视角网格导致PSNR下降约5.9 dB。移除所有特征网格导致PSNR下降约8.2 dB。
结论:时间网格和视角网格对捕捉时空和视角特征至关重要。多级时间网格的逐级启用显著提升了重建质量。
模型压缩
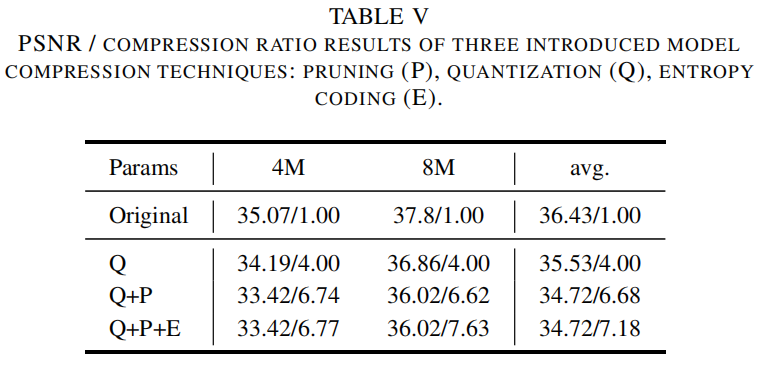
模型压缩技术包括剪枝(Pruning)、量化(Quantization)和熵编码(Entropy Coding),用于减少隐式网络的大小和传输比特率。
实验设置:仅量化(Q):仅对模型参数进行量化。量化 + 剪枝(Q + P):在量化的基础上进行剪枝。量化 + 剪枝 + 熵编码(Q + P + E):在量化和剪枝的基础上进行熵编码。
实验结果:量化(Q)带来4倍的压缩比,PSNR下降约0.9 dB。量化 + 剪枝(Q + P)带来6.7倍的压缩比,PSNR下降约1.7 dB。量化 + 剪枝 + 熵编码(Q + P + E)带来7.2倍的压缩比,PSNR下降约1.7 dB。
结论:模型压缩技术能够显著减少模型大小和传输比特率,同时保持较高的重建质量。熵编码在不影响重建质量的情况下进一步压缩模型大小。
其它
在表 3 中,我们进一步验证了网格嵌入模块和视角间补偿模块的有效性。
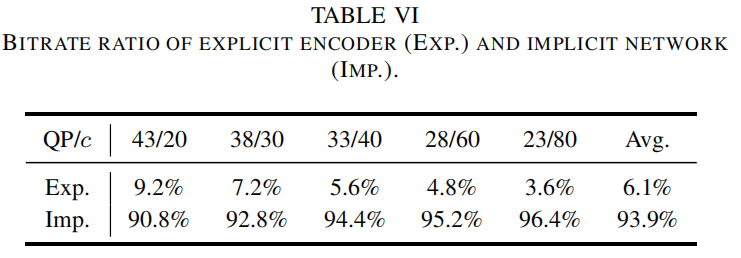
我们对隐式信息显示信息在比特流中的占比做了分析。通过使用少量的显示信息,我们的方法成功提升了隐式表达的性能。
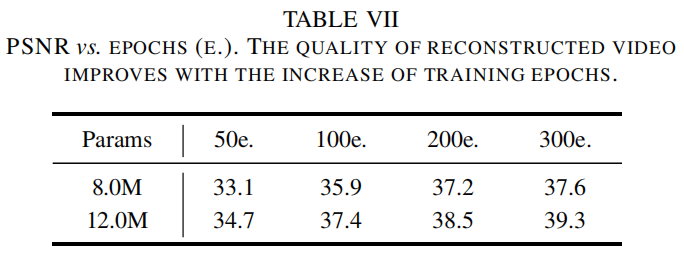
我们提供了不同大小的模型的收敛速度。
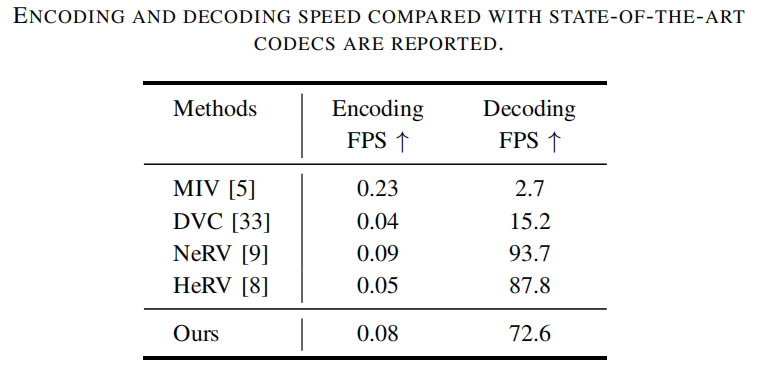
我们比较了我们的方法与其它显式或隐式方法的编解码速度。
局限性与讨论
快速运动物体的模糊:对于快速运动的物体(如电风扇),重建帧可能会出现模糊现象。
编码和解码速度:虽然隐式网络的解码速度接近70 FPS,但仍未达到实际应用的要求,尤其是在线训练时间较长。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
