

研究意义
文本驱动的视频编辑要求编辑后的视频应忠实地保留源视频的内容,各帧之间保持时间一致性,并且与目标文本以及 (optional) 参考图像对齐。然而,同时满足这三个要求存在很大的挑战。生活中的视频往往有几百帧,直接将其输入到网络显然显存不够,如何在有限的显存实现长时间的时间一致性也是一个研究难点。
尽管现有工作取得了不错的结果,它们依然无法解决上述的两项挑战:(1)同时满足文本驱动的视频编辑的三个目标;(2)聚焦于短视频编辑(少于24帧),长视频间的一致性尚未探索。
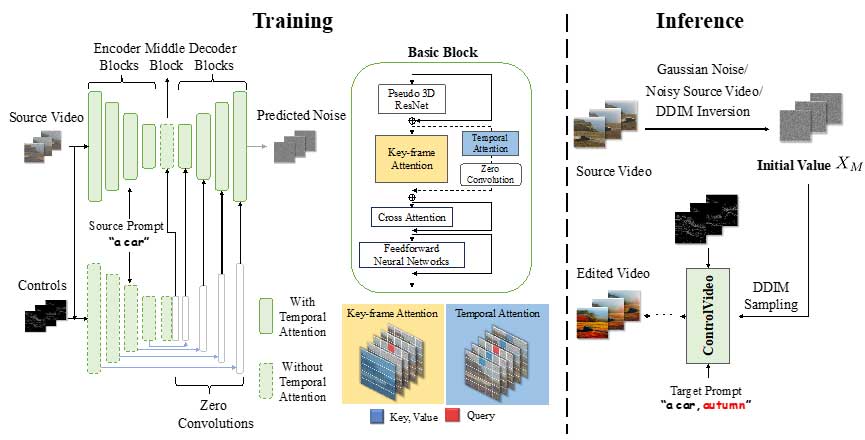
因此,本文基于预训练的图文大模型提出ControlVideo,该模型通过引入额外的条件控制信息、精心设计并微调key-frame attention和temporal attention以增强忠实性和时间一致性。通过引入Lora层学习参考图像的概念,ControlVideo还有能力生成和参考图像对齐的视频。除此之外,通过将ControlVideo应用在重叠的短视频以及关键帧视频并进一步通过预定义的权重融合,我们可以实现140帧的视频编辑,是以往工作的可处理帧数的5.83-17.5倍。
本文工作
1. ControlVideo
本文首先展示ControlVideo如何实现视频编辑的三个目标:
(1) 针对文本对齐目标,考虑到图文大模型已经在大规模图文数据预训练过,所以本文采用它作为backbone以利用其图文对齐的能力;
(2) 针对忠实性,本文提出直接将原视频的信息作为额外的条件控制(如边缘图)输入在噪声预测网络里,加强原视频的引导。由于不同的control含有原视频不同程度的信息,本文通过把多个control的特征加权来利用它们各自的优势;
(3) 为了解决时间一致性问题,本文对原始视频扩散模型中的自注意力机制进行了改进,加入了帧间交互,并提出了关键帧注意力机制。该机制通过选择视频中的某一帧作为信息传播的核心节点,使得其他帧与该关键帧保持一致,从而提升视频整体的时间连贯性。
2. Extended ControlVideo
尽管上述的 ControlVideo 方法能够取得较好的效果,但由于显存的限制,其处理包含数百帧长视频的能力仍然有限。为了解决这一问题,我们采用了分段生成策略,首先使用可控视频扩散模型生成一系列较短的视频片段,然后通过预定义的权重在相邻片段间实现平滑过渡。该策略有效解决了相邻片段间的一致性问题,通过在后续的去噪步骤中使不重叠和重叠帧的特征逐步靠拢,从而间接增强了全局一致性。此外,为进一步提升全局一致性,我们还构建了一个关键帧视频,用于直接引导整个视频序列的生成过程。
3. 本文的主要贡献
(1) 基于预训练的图文大模型提出ControlVideo,通过引入额外的条件控制信息、精心设计并微调key-frame attention和temporal attention以增强忠实性和时间一致性。通过引入Lora层学习参考图像的概念,ControlVideo还有能力生成和参考图像对齐的视频。
(2) 提出适合长视频编辑的采样算法,通过将ControlVideo应用在重叠的短视频以及关键帧视频并通过预定义的权重进一步融合,我们可以实现140帧的视频编辑,是以往工作的可处理帧数的5.83-17.5倍。
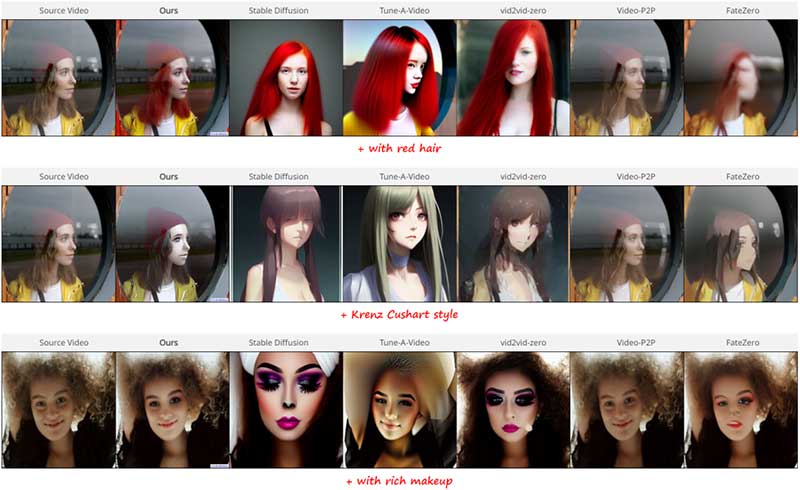
实验结果
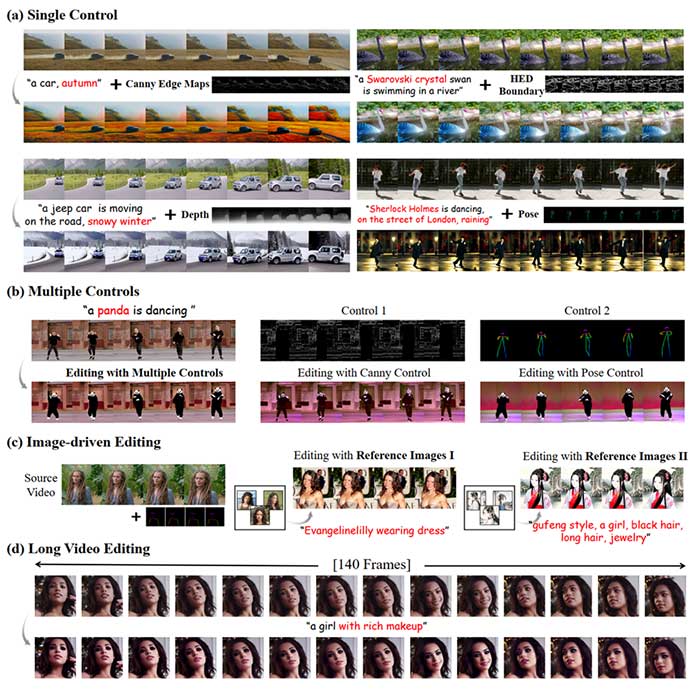
1. 应用
如图2所示,本文可以成功实现:
(a) 根据不同的control完成不同的编辑场景。例如,HED boundary 可以忠实地属性编辑,成功将天鹅变成施华洛施奇材质的天鹅。Pose可以灵活地改变形状和背景。
(b) 结合多控制条件同时保留背景和改变前景的形状。
(c) 将原视频的人物改成和参考图像中的Evangeline Lilly。
(d) 在数百帧的视频中保持时间一致性,维持人物身份不变。
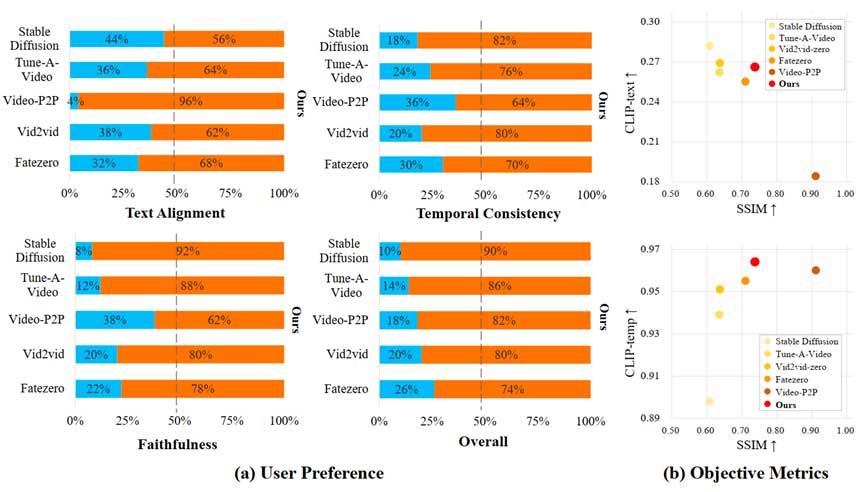
2. 与现有SOTA方法对比
如图3所示,本文编辑的结果可以同时满足视频编辑的三个目标,优于现有SOTA方法。除此之外,通过引入高斯噪声,本文可以更有效地全局编辑同时变动的背景和前景。例如图3的第三个例子中,本文可以成功生成熊猫在草地上跳舞的视频。图4的量化指标表明,综合全面的指标,我们的方法优于现有SOTA方法。

论文链接:https://www.sciengine.com/SCIS/doi/10.1007/s11432-023-4184-4
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
