
LLM 的最新进展(例如 GPT 系列和新兴的“o1”模型)凸显了扩展训练和推理时间计算的好处。虽然在训练期间扩展(通过增加模型大小和数据集量)是一种行之有效的策略,但最近的研究结果强调了推理时间扩展的优势,即在测试期间增加计算资源可提高输出质量和任务复杂性处理能力。这一原理已在基于文本的模型中得到广泛探索,但在语音合成中仍未得到充分利用。现有的文本转语音 (TTS) 系统通常采用多阶段架构,将 LLM 与扩散模型或其他处理模块相结合,从而使扩展决策变得复杂。与遵循标准化 Transformer 框架(允许系统性扩展研究)的文本模型不同,TTS 研究主要集中于架构改进,而不是优化推理时间计算。
通过直接建模离散语音标记而不是依赖中间声学表示,向单级 TTS 架构的转变解决了多级管道的低效率问题。这种方法降低了复杂性,增强了可扩展性,并实现了大规模训练而不受重大内存限制。对此类架构的评估表明,它在零样本语音合成、跨语言自适应和情感保存方面具有最先进的性能,超越了传统的多级模型。此外,集成扩展策略可提高 ASR 准确性,弥合基于文本和语音的 LLM 应用程序之间的差距。通过采用统一的、计算效率高的框架,TTS 的最新进展与文本 LLM 中看到的可扩展方法更加紧密地结合在一起,从而实现了更灵活、更高质量的语音合成解决方案。
西北工业大学 ASLP 实验室、北京科技大学、萨里大学、香港中文大学、香港浸会大学、罗切斯特大学和上海出门问问信息技术有限公司的研究人员推出了 Llasa,这是一种基于 Transformer 的 TTS 模型,符合标准 LLM 架构。扩展训练时间计算可提高语音的自然度和韵律,而推理时间计算与语音理解验证器一起可提高情感表现力、音色一致性和内容准确性。对多个数据集的评估显示了最先进的结果,并且模型和代码已公开,以鼓励进一步的 TTS 研究。
TTS 框架与标准文本 LLM 范式保持一致,使用标记器和基于 Transformer 的 LLM。它采用语音标记器 Xcodec2,可将波形编码为离散标记,并将其解码为高质量音频。该模型学习文本和语音标记的联合分布,优化基于文本输入生成语音标记的条件概率。语音标记器使用双编码器系统集成语义和声学特征。该方法扩展训练数据和模型大小以提高性能,并评估训练时间和推理时间计算策略,重点关注文本理解和上下文学习能力。
该研究将提出的语音分词器与现有编解码器进行了比较,并评估了其在 TTS 系统中的性能。使用诸如词错误率 (WER)、语音质量感知评估 (PESQ) 和说话人相似度 (SPK SIM) 等指标,对语音分词器进行了各种模型测试。结果表明,分词器在低分词率下表现良好,语音质量优于其他编解码器。TTS 模型的文本理解和上下文学习能力经过评估,随着模型大小和训练数据的扩展而得到改进。推理时间计算扩展也提高了性能,平衡了说话人相似度和转录准确性。
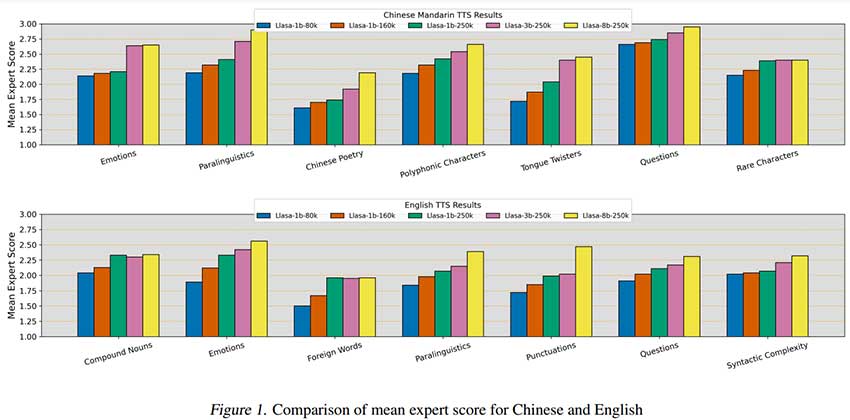
最后,本研究介绍了 Llasa,这是一个可扩展的 TTS 系统,使用单个 Transformer 模型和标记器,与基于文本的 LLM 保持一致。本研究探索了训练时间和推理时间计算扩展,表明更大的模型和数据集可以提高语音的自然度、韵律和理解力。此外,使用语音理解模型作为验证器,推理时间扩展可以增强说话者的相似性、情感表达力和准确性。
Llasa 的实验展示了最先进的性能和强大的零样本 TTS 功能。作者发布了他们的模型和训练代码,以鼓励该领域的进一步研究。更多详细信息请查看:https://github.com/zhenye234/LLaSA_training
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/55749.html
