
近年来,文本转语音 (TTS) 技术取得了长足进步,但在创建自然、富有表现力和高保真的语音合成方面仍然存在挑战。许多 TTS 系统难以复制人类语音的细微差别,例如语调、情感和口音,因此经常产生听起来像人造的声音。此外,精确的语音克隆仍然很困难,限制了生成个性化或多样化语音输出的能力。这些挑战促使人们继续研究更复杂的 TTS 模型,以便能够生成实时、富有表现力和逼真的语音。
Zyphra 推出了 Zonos-v0.1 的测试版,该版本包含两个具有高保真语音克隆功能的实时 TTS 模型。该版本包括一个 16 亿参数的变换器模型和一个大小相似的混合模型,均在 Apache 2.0 许可下提供。这项开源计划旨在通过让开发人员和研究人员更容易获得高质量的语音合成技术来推动 TTS 研究。
Zonos-v0.1 模型基于大约 200,000 小时的语音数据进行训练,涵盖中性和表达性语音模式。虽然主要数据集由英语内容组成,但已纳入大量中文、日语、法语、西班牙语和德语语音,从而实现多语言支持。这些模型使用说话人嵌入或音频前缀从文本提示生成逼真的语音。它们只需 5 到 30 秒的样本语音即可进行语音克隆,并可控制语速、音调变化、音频质量以及悲伤、恐惧、愤怒、快乐和惊讶等情绪等参数。合成语音以 44 kHz 采样率产生,确保高音频保真度。
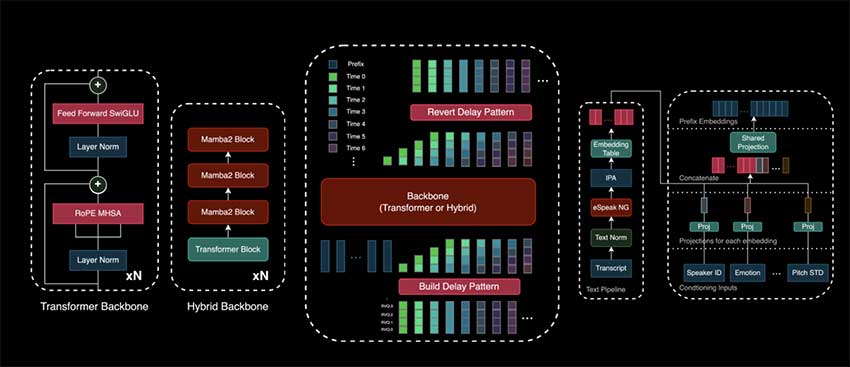
Zonos-v0.1 包含几个主要功能:
- 具有语音克隆的零样本 TTS:用户可以通过在文本输入旁边提供简短的说话人样本来生成语音,从而可以用最少的数据合成语音。
- 音频前缀输入:通过加入音频前缀,模型可以更好地匹配说话者的特征,甚至可以重现特定的说话风格,例如耳语。
- 多语言支持:系统支持多种语言,包括英语、日语、中文、法语和德语,提高了其全球应用的通用性。
- 音频质量和情感控制:用户可以微调音调、频率范围和情绪基调等方面,以创造更具表现力和自然的语音输出。
- 高效性能:在 RTX 4090 上以大约两倍实时速度运行,模型针对实时应用进行了优化。
- 用户友好界面:基于 Gradio 的 WebUI 简化了语音生成,使更广泛的用户可以使用。
- 直接部署:使用提供的 Docker 设置可以轻松安装和部署模型,确保轻松集成到现有工作流程中。
这些功能使 Zonos-v0.1 成为各种 TTS 应用程序的灵活工具,从内容创建到辅助功能工具。
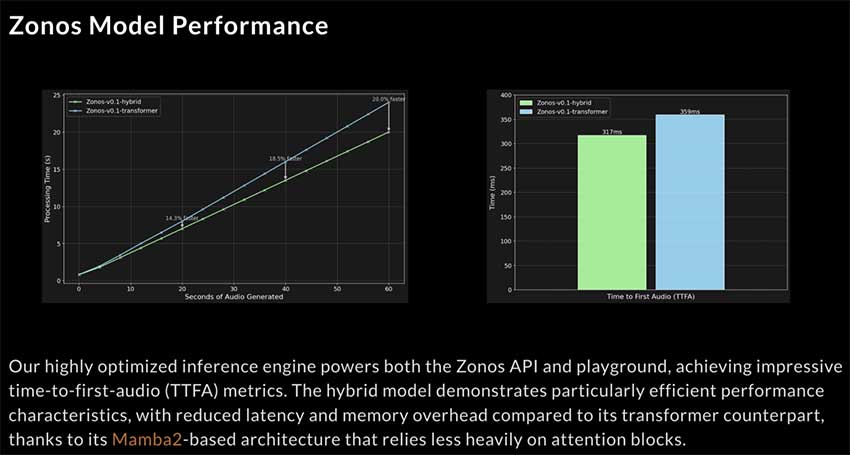
早期评估表明,Zonos-v0.1 可提供高质量的语音生成,通常可与领先的专有系统相媲美甚至超过它们。虽然客观音频评估仍然很复杂,但与其他模型(包括 ElevenLabs 和 Cartesia 等专有解决方案以及 FishSpeech-v1.5 等开源替代方案)的比较凸显了 Zonos 生成清晰、自然且富有表现力的语音的能力。与 Transformer 变体相比,混合模型尤其具有更低的延迟和更低的内存使用率,这得益于其基于 Mamba2 的架构,该架构最大限度地减少了对注意力机制的依赖。
Zonos-v0.1 测试版代表开源 TTS 开发向前迈出了重要一步。通过在可访问的许可下提供高保真、富有表现力和实时的语音合成工具,Zyphra 为开发人员和研究人员提供了推进 TTS 应用程序的强大资源。它结合了语音克隆、多语言支持和细粒度音频控制,使其成为该领域的多功能补充,在辅助技术、内容创建等领域具有潜在的应用。
更多详细信息和技术细节请查看:https://www.zyphra.com/post/beta-release-of-zonos-v0-1
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/55690.html
