
尽管人工智能驱动的人体动画取得了进展,但现有模型在动作逼真度、适应性和可扩展性方面往往面临限制。许多模型难以生成流畅的肢体动作,并且依赖于过滤后的训练数据集,这限制了它们处理各种场景的能力。面部动画已经有所改进,但由于手势准确性和姿势对齐方面的不一致,全身动画仍然具有挑战性。此外,许多框架受到特定长宽比和身体比例的限制,从而限制了它们在不同媒体格式中的适用性。要应对这些挑战,需要一种更灵活、更可扩展的动作学习方法。
字节跳动推出了 OmniHuman-1,这是一种基于扩散变换器的人工智能模型,能够从单一图像和运动信号(包括音频、视频或两者的组合)生成逼真的人体视频。与以往专注于肖像或静态人体动画的方法不同,OmniHuman-1 结合了全方位条件训练,使其能够有效扩展运动数据,改善手势逼真度、肢体运动和人与物体的交互。
OmniHuman-1 支持多种形式的动作输入:
- 音频驱动动画,通过语音输入生成同步的嘴唇动作和手势。
- 视频驱动动画,根据参考视频复制动作。
- 多模态融合,结合音频和视频信号,精确控制不同的身体部位。
它能够处理各种长宽比和身体比例,是需要人体动画应用的多功能工具,使其有别于以往的模型。
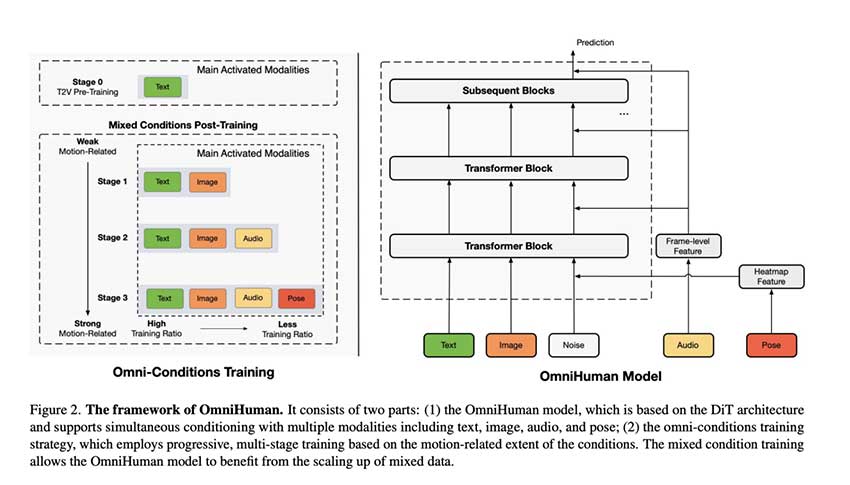
技术基础和优势
OmniHuman-1 采用扩散变换器 (DiT) 架构,整合了多种运动相关条件,以增强视频生成能力。主要创新包括:
- 多模态运动调节:在训练过程中整合文本、音频和姿势条件,使其能够适应不同的动画风格和输入类型。
- 可扩展的训练策略:传统方法会因严格的过滤而丢弃大量数据,与此不同,OmniHuman-1 可优化强运动条件和弱运动条件的使用,从而以最少的输入实现高质量的动画。
- 全方位条件训练:训练策略遵循两个原则:
- 条件较强的任务(如姿势驱动的动画)利用条件较弱的数据(如文本、音频驱动的动作)来提高数据的多样性。
- 对训练比例进行调整,以确保较弱的条件得到更多的重视,从而平衡不同模态的泛化。
- 逼真的动作生成:OmniHuman-1 擅长协同语音手势、自然的头部运动和细致的手部互动,因此对虚拟化身、人工智能驱动的角色动画和数字故事特别有效。
- 适应多种风格:该模型并不局限于逼真的输出;它支持卡通、风格化和拟人化的角色动画,从而拓宽了其创意应用领域。
性能和基准测试
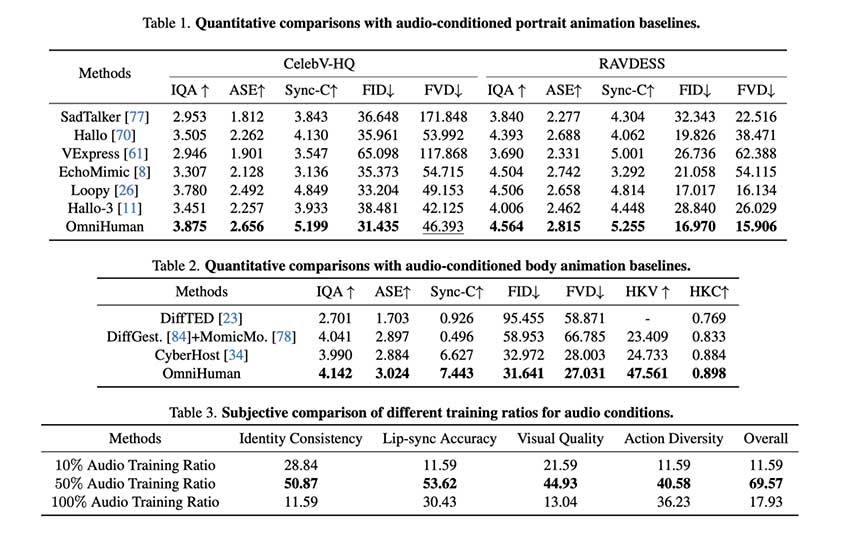
OmniHuman-1 已与包括 Loopy、CyberHost 和 DiffTED 在内的领先动画模型进行了评估,在多个指标上都表现出卓越的性能:
- 唇语同步精度(越高越好):
- OmniHuman-1:5.255
- Loopy:4.814
- CyberHost: 6.627
- Fréchet Video Distance(FVD)(越低越好):
- OmniHuman-1:15.906
- Loopy:16.134
- DiffTED:58.871
- 手势表现力(HKV 指标):
- OmniHuman-1: 47.561
- CyberHost: 24.733
- DiffGest: 23.409
- 手势关键点置信度 (HKC)
- OmniHuman-1: 0.898
- CyberHost: 0.884
- DiffTED: 0.769
消融研究进一步证实了在训练中平衡姿势、参考图像和音频条件对于实现自然而富有表现力的动作生成的重要性。该模型能够适应不同的身体比例和长宽比,与现有方法相比具有明显优势。
结论
OmniHuman-1 代表着人工智能驱动的人体动画向前迈进了一大步。通过整合全方位条件训练和利用基于 DiT 的架构,字节跳动开发出了一种模型,有效地弥补了静态图像输入与动态逼真视频生成之间的差距。字节跳动能够利用音频、视频或两者从单一图像中生成人物动画,这使其成为虚拟影响者、数字化身、游戏开发和人工智能辅助电影制作的重要工具。
随着人工智能生成的人物视频变得越来越复杂,OmniHuman-1 强调了向更加灵活、可扩展和可适应的动画模型的转变。通过解决运动逼真度和训练可扩展性方面的长期挑战,它为人类动画生成人工智能的进一步发展奠定了基础。
论文地址:https://arxiv.org/abs/2502.01061
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/55594.html
