
由大型语言模型(LLM)驱动的自主代理研究已显示出在提高人类生产力方面的巨大潜力。这些代理旨在协助完成各种任务,例如编码、数据分析和网页导航。它们通过自动执行常规数字任务,让用户专注于创造性和战略性工作。然而,尽管取得了进展,这些系统在实现实际应用所需的效率和可靠性方面仍面临挑战,特别是在适应新环境方面。
该领域最大的限制之一是缺乏高质量、特定于环境的数据集。目前的 LLM 基本上是静态的,依赖于预训练数据,而这些数据并未考虑现实环境中遇到的动态和多变场景。无法适应导致 LLM 难以完成需要情境理解或多步推理的任务,从而导致这些系统的潜力与实际能力之间存在巨大差距。
传统技术依靠人工注释数据和快速工程来提高 LLM 的性能。这些技术通常涉及从现有库中检索实例或从预训练模型中提取信息。但这样做存在严重缺陷,例如成本高、创建多轮交互数据集效率低下以及无法扩展到大量领域。其他方法(例如强化学习或检索增强生成 ( RAG ))在一定程度上解决了这些缺陷,但可能会出现噪声数据,或者无法充分处理复杂的轨迹。
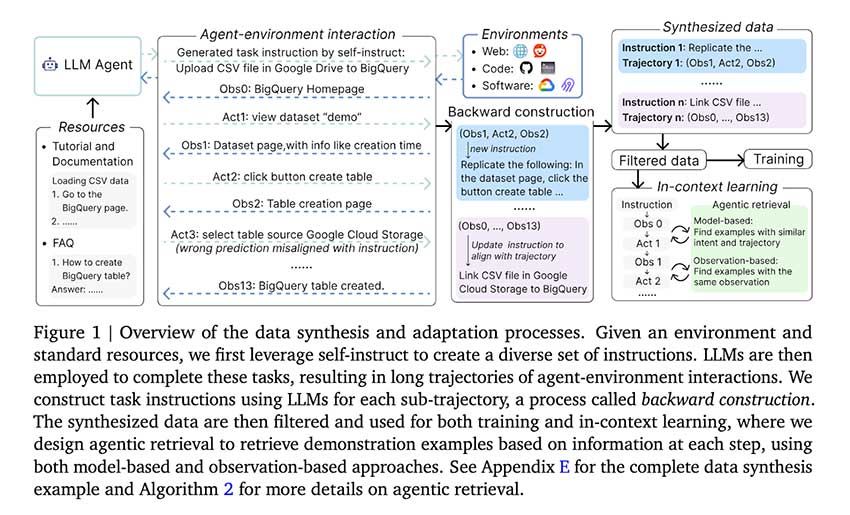
谷歌和香港大学的研究人员提出了“通过互动学习”框架,该框架解决了上述限制。通过互动学习,我们可以在任何可访问的资源(在本例中是文档和教程)的基础上自动完成交互数据合成。该框架允许代理生成任务指令并在环境中自主交互。这些交互通过向后构建进行总结和细化,从而使生成的轨迹与任务目标保持一致。这项创新确保用于训练和推理的数据是连贯且高质量的。
互动学习背后的方法包含几个关键过程。首先,该框架使用自我指导从现有资源中创建各种任务指令。代理通过生成交互轨迹在模拟环境中执行这些指令,然后将其总结为新的任务指令。反向构造是此过程的一个组成部分,它抽象并重新调整轨迹与预期结果,以确保任务与合成数据之间的一致性。系统中的过滤机制会过滤掉噪声数据,仅使用高质量的示例来推进该过程。此外,新颖的检索流程通过合并基于观察和基于模型的方法来提高检索的相关性和效率,从而进一步增强了合成数据的使用。
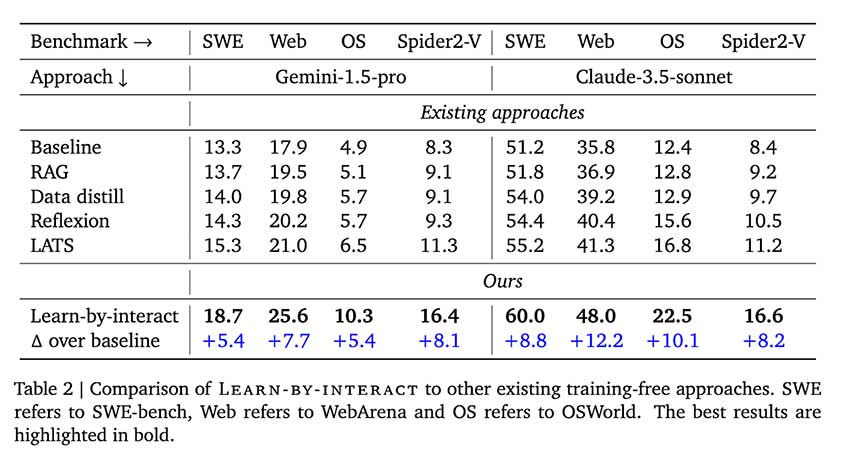
在四个基准测试中对 Learn-by-Interact 进行了全面评估:SWE-bench、WebArena、OSWorld 和 Spider2-V。该框架始终表现出比传统方法更好的性能。例如,在 OSWorld 上,该框架几乎使 Claude-3.5 的基准性能提高了一倍,准确率从 12.4% 提高到 22.5%。在基于训练的评估中,Codestral-22B 在使用该框架合成的数据进行训练后,准确率从 4.7% 提高到 24.2%。在所有基准测试中,Learn-by-Interact 在无训练设置中平均提高了 8.8%。这些结果强调了该框架的稳健性和可扩展性,使其成为各种实际应用的有效工具。
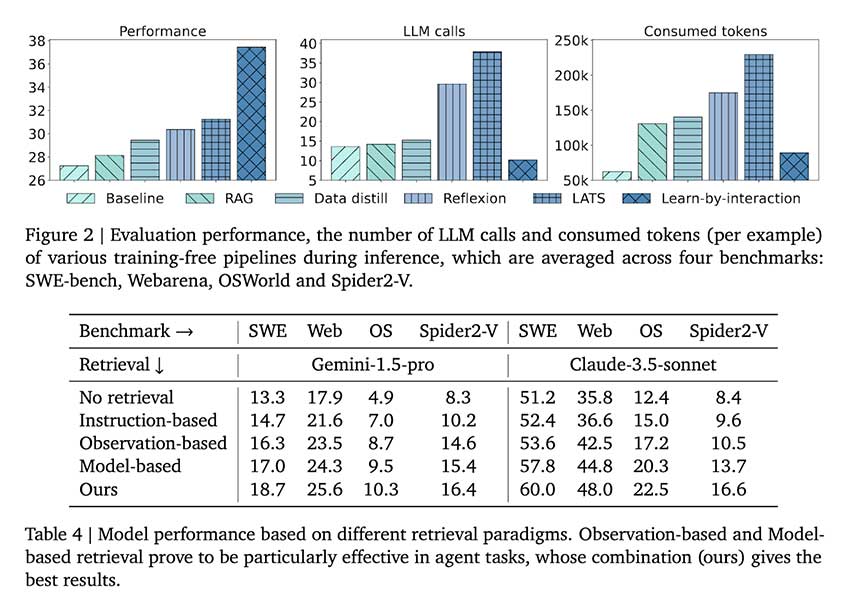
除了良好的性能指标外,研究还指出了该框架的效率。与消耗大量计算资源的传统方法不同,Learn-by-Interact 通过减少评估期间消耗的语言模型调用和标记数量来优化推理。该框架的效率和自主生成高质量数据的能力使其成为开发自适应 LLM 代理的重大进步。
Learn-by-Interact 解决方案解决了该领域最艰巨的挑战之一:大规模高质量、特定于环境的合成。它在对昂贵且耗时的人工注释的需求下降的背景下为合成此类数据带来了可扩展性,同时在不同任务中实现了卓越的性能。这为开发更可靠的 LLM 代理带来了重大进步,这些代理可用于在现实环境中部署。该框架引入了后向构造和高级检索技术的使用,从而提高了性能,并成为自主代理研究中效率和适应性的新基准。
论文地址:https://arxiv.org/abs/2501.10893
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/55553.html
