
标记化是将文本分解成更小单元的过程,长期以来一直是自然语言处理 (NLP) 中的一个基本步骤。然而,它带来了一些挑战。基于标记器的语言模型 (LM) 经常难以处理多语言文本、词汇表外 (OOV) 的单词以及拼写错误、表情符号或混合代码文本等输入。这些问题会降低模型的稳健性并增加预处理管道的复杂性。此外,标记化通常无法无缝适应多模式任务,从而导致效率低下并使可扩展性复杂化。要解决这些限制,需要超越基于标记的处理,采用更通用、适应性更强的方法。
香港大学研究人员提出了 EvaByte,这是一种开源的无标记器语言模型,旨在解决这些挑战。这个字节级模型拥有 65 亿个参数,性能可与现代基于标记器的 LM 相媲美,同时所需的数据量减少了 5 倍,解码速度提高了 2 倍。EvaByte 由 EVA 提供支持,EVA 是一种高效的注意力机制,专为可扩展性和性能而设计。通过处理原始字节而不是依赖标记化,EvaByte 可以一致且轻松地处理各种数据格式(包括文本、图像和音频)。这种方法消除了常见的标记化问题,例如不一致的子词拆分和严格的编码边界,使其成为多语言和多模式任务的可靠选择。此外,其开源框架鼓励协作和创新,使更广泛的社区能够使用尖端的 NLP。
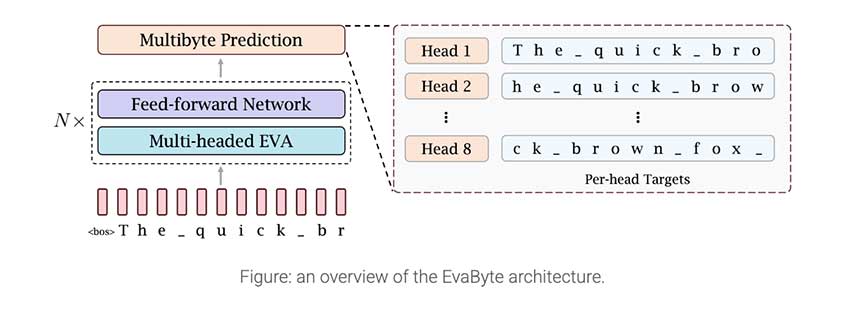
技术细节和优势
EvaByte 采用字节级处理策略,使用原始字节作为训练和推理的基本单位。这种设计天生就支持所有语言、符号和非文本数据,无需专门的预处理。其 6.5B 参数架构在计算效率和高性能之间取得了平衡。
EvaByte 的主要优点包括:
- 数据效率:该模型通过在字节级别进行操作来最大限度地减少冗余,从而以明显更小的数据集实现具有竞争力的结果。
- 更快的解码:EvaByte 的精简架构提高了推理速度,使其适用于实时应用。
- 多模式功能:与传统的 LM 不同,EvaByte 可以自然扩展到多模式任务,允许统一处理多种数据类型。
- 稳健性:通过消除标记化,EvaByte 可以一致地处理各种输入格式,从而提高跨应用程序的可靠性。
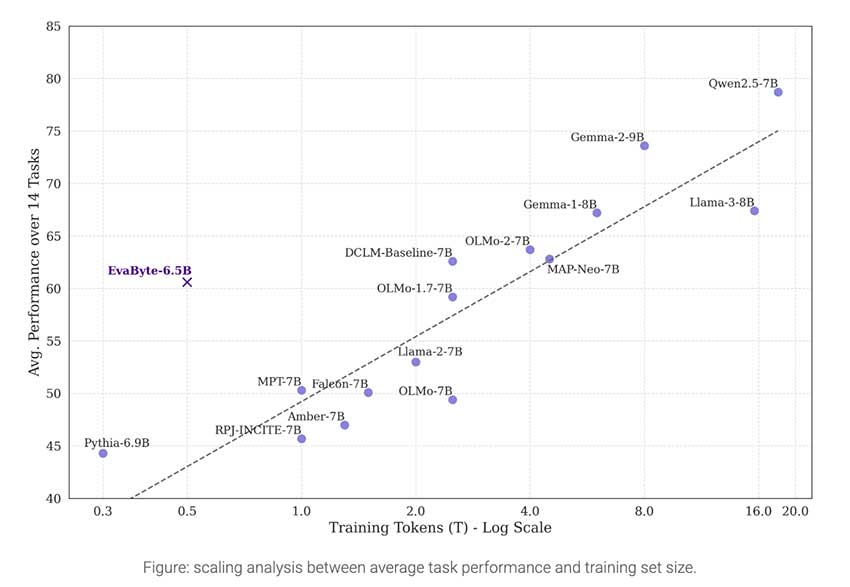
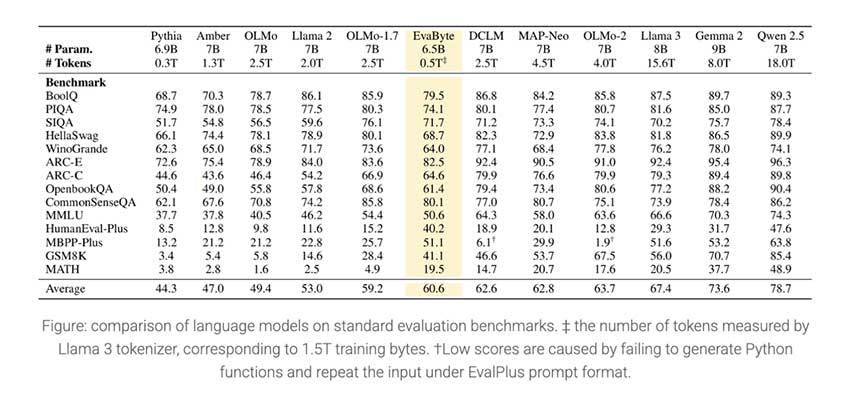
成果与见解
EvaByte 的性能非常显著。尽管使用的数据少了 5 倍,但它在标准 NLP 基准测试中取得了与基于标记符的领先模型相当的结果。EvaByte 的跨语言泛化能力使其在多语言场景中尤为有效,其表现始终优于传统模型。EvaByte 还在图像字幕和音频-文本整合等多模态任务中表现出强劲的性能,无需大量微调就能获得具有竞争力的结果。
开源版本包括预训练检查点、评估工具以及与 Hugging Face 的集成,使其可用于实验和开发。研究人员和开发人员可以将 EvaByte 用于从对话代理到跨模态信息检索等各种应用,并从其高效性和多功能性中获益。
结论
EvaByte 为传统标记化的局限性提供了周到的解决方案,提出了一种兼具效率、速度和适应性的无标记器架构。通过解决 NLP 和多模态处理中长期存在的挑战,EvaByte 为语言模型树立了新标准。它的开源性质促进了协作和创新,确保更广泛的受众能够使用先进的 NLP 功能。对于那些希望探索尖端 NLP 解决方案的人来说,EvaByte 代表了语言理解和生成方面迈出的重要一步。
查看更多详细信息:https://hkunlp.github.io/blog/2025/evabyte/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/55518.html
