
大型语言模型 (LLM) 已成为人工智能的关键,为从聊天机器人到内容生成工具的各种应用提供支持。然而,大规模部署它们带来了显著的挑战。高计算成本、延迟和能耗通常会限制它们的广泛使用。组织面临着平衡高吞吐量和合理运营费用的困难。此外,随着模型变得越来越大,对更高效解决方案的需求也变得越来越迫切。解决这些问题对于使 LLM 更加实用和易于使用至关重要。
Snowflake AI 研究团队推出了 SwiftKV,这是一种旨在提高 LLM 推理吞吐量并降低相关成本的解决方案。SwiftKV 使用键值缓存技术在推理过程中重用中间计算。通过消除冗余计算,它简化了推理过程并提高了 LLM 部署效率。
SwiftKV 的设计针对的是 LLM 的计算强度。传统的推理管道通常会为多个请求重新计算相同的操作,从而导致效率低下。SwiftKV 引入了一个缓存层,用于识别和存储可重复使用的计算结果。这种方法可以加速推理并减少资源需求,使其成为旨在优化 AI 操作的组织的实用选择。
SwiftKV 的技术细节和主要优势
SwiftKV 将键值内存系统融入到 LLM 推理架构中。其操作可以概括如下:
- 键值缓存:在推理过程中,SwiftKV 会捕获中间激活(键)及其对应的结果(值)。对于类似的查询,它会检索预先计算的值,而不是重新计算它们。
- 高效的存储管理:缓存机制采用最近最少使用 (LRU) 逐出等策略来有效地管理内存,确保缓存保持有用,而不会消耗过多的资源。
- 无缝集成:SwiftKV 与现有的 LLM 框架兼容,例如 Hugging Face 的 Transformers 和 Meta 的 LLaMA,因此可以轻松采用而无需对现有管道进行重大更改。
SwiftKV 的优势包括:
- 降低成本:通过避免冗余计算,SwiftKV 显著降低了推理成本。Snowflake AI Research 报告称,在某些情况下,成本可降低高达 75%。
- 增强吞吐量:缓存机制减少推理时间,提高响应速度。
- 节能:较低的计算需求意味着减少能源消耗,支持可持续的人工智能实践。
- 可扩展性:SwiftKV 非常适合大规模部署,满足企业扩展 AI 功能的需求。
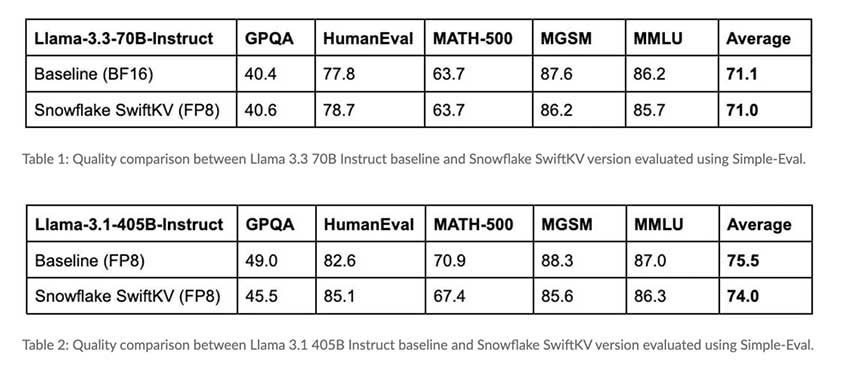
结果
Snowflake AI Research 对 SwiftKV 的评估为其有效性提供了宝贵的见解。例如,将 SwiftKV 与 Meta 的 LLaMA 模型集成可将推理成本降低 75%,而不会影响准确性或性能。这些结果凸显了这种方法可能带来的效率提升。
此外,测试表明,即使对于较大的模型,推理延迟也显著减少。缓存系统可确保复杂查询受益于更快的处理时间。这种成本效益和性能优化的结合使 SwiftKV 成为旨在以可承受的价格扩展 AI 解决方案的组织的有力选择。
SwiftKV 的开源鼓励了 AI 社区内的协作。通过分享这项技术,Snowflake AI Research 邀请开发人员、研究人员和企业探索和增强其功能,促进 LLM 效率的创新。
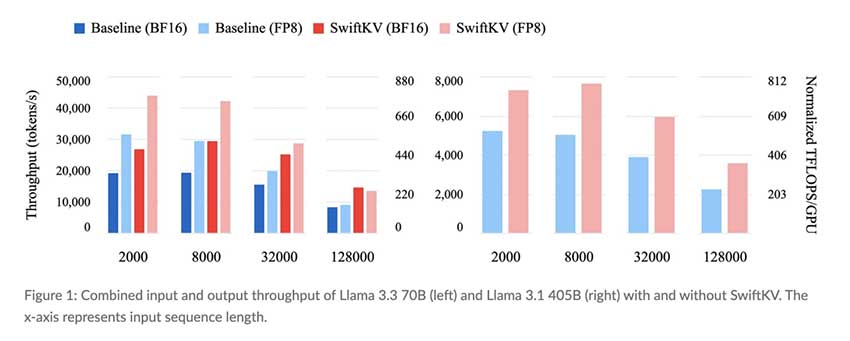
结论:LLM 效率的进步
SwiftKV 为大规模部署 LLM 的挑战提供了周到的解决方案。通过解决高计算成本和延迟问题,它有助于使 AI 应用程序更加实用和易于访问。将键值缓存纳入推理管道展示了有针对性的优化如何推动显著改进。
随着人工智能领域的进步,SwiftKV 等工具将继续塑造高效、可持续技术的发展。其开源特性确保更广泛的社区能够为其发展和应用做出贡献。通过实现更具成本效益和可扩展的 LLM 使用,SwiftKV 强调了创新对于让人工智能真正为企业和开发者带来变革的重要性。
了解更多详细信息请查看:https://www.snowflake.com/en/blog/up-to-75-lower-inference-cost-llama-meta-llm/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/55476.html
