
语音处理系统通常难以在嘈杂的环境中提供清晰的音频。这一挑战影响了助听器、自动语音识别 (ASR) 和说话人验证等应用。传统的单通道语音增强 (SE) 系统使用 LSTM、CNN 和 GAN 等神经网络架构,但它们并非没有局限性。例如,基于注意力的模型(如 Conformers)虽然功能强大,但需要大量计算资源和大型数据集,这对于某些应用来说可能不切实际。这些限制凸显了对可扩展且高效的替代方案的需求。
xLSTM-SENet 简介
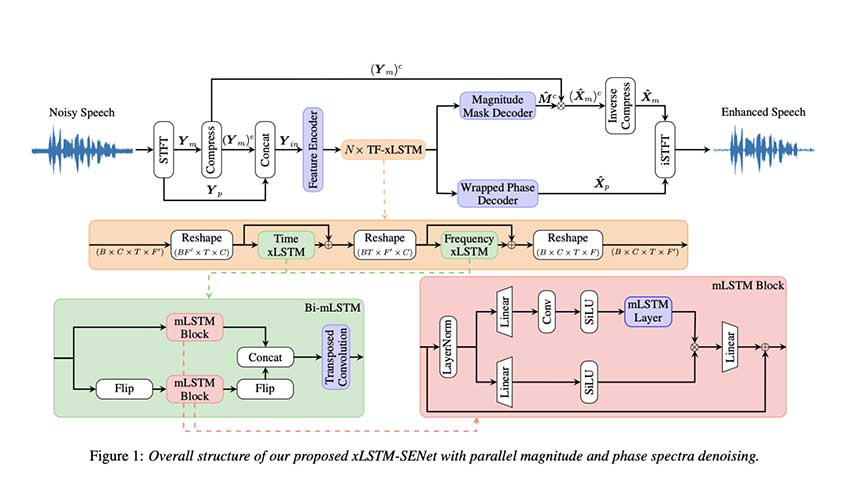
为了应对这些挑战,奥尔堡大学和 Oticon A/S 的研究人员开发了 xLSTM-SENet,这是首个基于 xLSTM 的单通道 SE 系统。该系统以扩展长短期记忆(xLSTM)架构为基础,通过引入指数门控和矩阵记忆改进了传统的 LSTM 模型。这些改进解决了标准 LSTM 的一些局限性,如存储容量受限和并行性有限。通过将 xLSTM 集成到 MP-SENet 框架中,新系统可以有效处理幅度和相位频谱,为语音增强提供了一种简化方法。
技术概述和优势
xLSTM-SENet 采用时频 (TF) 域编码器-解码器结构设计。其核心是 TF-xLSTM 块,使用 mLSTM 层来捕获时间和频率依赖性。与传统 LSTM 不同,mLSTM 采用指数门控来实现更精确的存储控制,并采用基于矩阵的内存设计来增加容量。双向架构进一步增强了模型利用过去和未来帧的上下文信息的能力。此外,该系统还包括用于幅度和相位谱的专用解码器,有助于提高语音质量和清晰度。这些创新使 xLSTM-SENet 高效且适用于计算资源有限的设备。
表现与结果
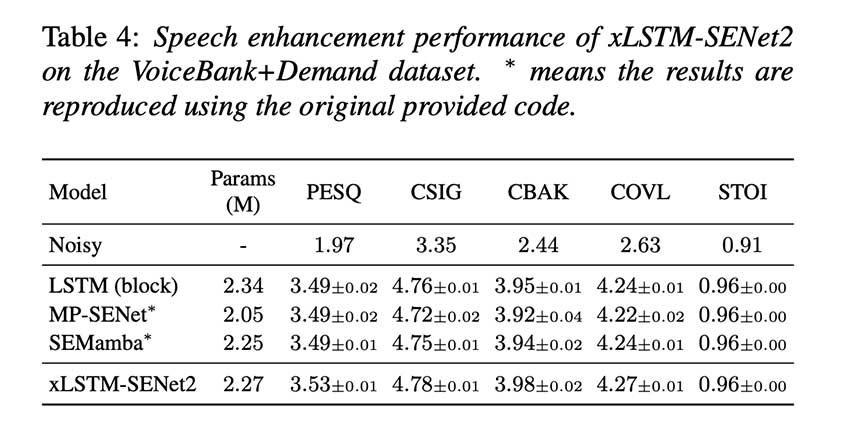
使用 VoiceBank+DEMAND 数据集进行的评估凸显了 xLSTM-SENet 的有效性。该系统取得的结果可与 SEMamba 和 MP-SENet 等最先进的模型相媲美甚至更好。例如,它记录的语音质量感知评估 (PESQ) 得分为 3.48,短期客观可理解性 (STOI) 为 0.96。此外,CSIG、CBAK 和 COVL 等综合指标显示出显着的改进。消融研究强调了指数门控和双向性等特征对提高性能的重要性。虽然该系统需要比一些基于注意力的模型更长的训练时间,但其整体性能证明了其价值。
结论
xLSTM-SENet 为单通道语音增强的挑战提供了周到的应对方案。通过利用 xLSTM 架构的功能,该系统在可扩展性和效率与稳健性能之间实现了平衡。这项工作不仅推动了语音增强技术的发展,还为其在助听器和语音识别系统等现实场景中的应用打开了大门。随着这些技术的不断发展,它们有望使高质量的语音处理更易于获取,并满足各种需求。
论文地址:https://arxiv.org/abs/2501.06146
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/55346.html
