
大型语言和多模态语音文本模型的进步为无缝、实时、自然和类人语音交互奠定了基础。要实现这一点,系统需要处理语音内容、情绪语调和音频提示,同时给出准确而连贯的响应。然而,在克服语音和文本序列的差异、语音任务的有限预训练以及保留语言模型中的知识方面仍然存在挑战。该系统也无法填补语音翻译、情感识别和对话期间同时处理等功能的空白。
目前,语音交互系统分为原生多模态模型和对齐多模态模型。原生多模态模型集成了语音和文本的理解和生成。然而,它们面临着语音标记序列比文本序列长的挑战,这使得它们随着模型规模的扩大而变得低效。这些模型还难以处理有限的语音数据,导致灾难性遗忘等问题。对齐多模态模型旨在将语音功能与预训练的文本模型相结合。然而,这些模型是在小数据集上训练的,缺乏对情绪识别或说话人分析等复杂语音任务的关注。此外,这些模型还没有得到适当的评估,无法处理不同的说话风格或全双工对话,而这些对于无缝语音交互至关重要。
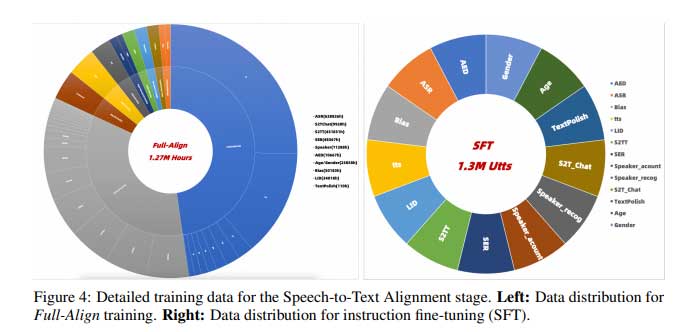
为了缓解当前多模态模型的问题,Tongyi Lab(通义实验室)和阿里巴巴集团的研究人员提出了MinMo,这是一种新的多模态大型语言模型,旨在提高语音理解和生成能力。研究人员在语音转文本、文本转语音和语音转语音等各种任务上对超过140 万小时的语音数据进行了训练。这种广泛的训练使 MinMo 在多个基准测试中实现了最佳性能,同时避免了文本LLM功能的灾难性遗忘。与之前的模型不同,MinMo 无缝集成了语音和文本,而不会损失文本任务的性能,并增强了语音交互功能,如情感识别、说话人分析和多语言语音识别。

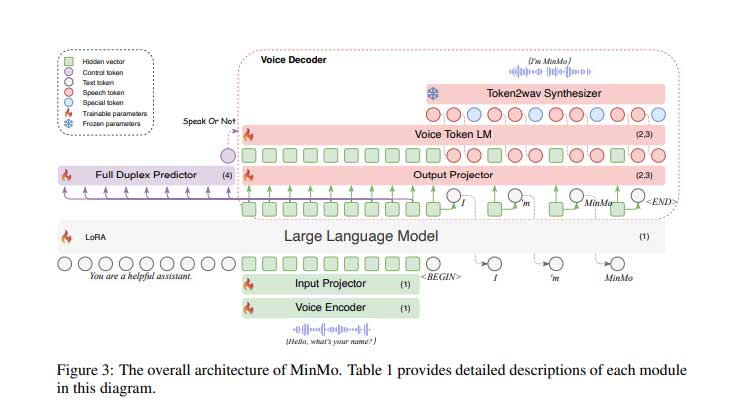
研究人员设计了MinMo,采用多阶段训练方法将语音和文本模式结合起来,实现语音转文本、文本转语音、语音转语音和双工交互。该模型利用预训练的文本 LLM,并包括用于多语言语音和情感识别的SenseVoice-large语音编码器、用于文本处理的Qwen2.5-7B-instruct LLM 和用于高效音频生成的 CosyVoice 2 等核心组件。MinMo 还引入了AR 流式 Transformer 语音解码器,可提高性能并减少延迟。该模型拥有约 80 亿个参数,可提供实时响应和全双工交互,延迟约为600 毫秒。
研究人员在多个基准测试中对MinMo进行了测试,包括多语言语音识别、语音转文本增强和语音生成。结果表明,MinMo 的表现优于大多数模型,包括 Whisper Large v3,尤其是在多语言语音识别任务中,并在多语言语音翻译中取得了最先进的性能。它在语音转文本增强、语音情感识别 (SER) 和音频事件理解方面也表现出色。
MinMo使用Fleur 的数据集实现了85.3% 的语言识别准确率,超越了所有之前的模型。在性别检测、年龄估计和标点符号插入等任务中,MinMo 表现强劲,超越了Qwen2.5-7B和 SenseVoice-L 等模型。它在语音生成的方言和角色扮演任务中也表现出色,准确率为98.4%,而GLM-4-Voice 的准确率为 63.1%。尽管由于复杂度的原因,MinMo 在语音转语音任务中的表现有所下降,但在对话任务和逻辑推理方面表现良好。该模型在话轮转换方面实现了高灵敏度,预测性能约为99% ,在全双工交互中响应延迟约为600 毫秒。
总之,提出的MinMo模型通过解决序列长度差异和灾难性遗忘等挑战,推动了语音交互系统的发展。其多阶段对齐策略和语音解码器可实现多语言语音和情感识别性能。MinMo 为自然语音交互设定了新的基准,可以作为未来研究的基线,在指令遵循和端到端音频生成方面具有潜在的改进。未来的发展可以集中在改进发音处理和开发完全集成的系统上。
更多详细信息请查看:https://funaudiollm.github.io/minmo/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/55340.html
