
视频语言表征学习是多模态表征学习的一个重要子领域,它专注于视频与其相关文本描述之间的关系。它在许多领域都有应用,从问答和文本检索到摘要。在这方面,对比学习已经成为一种强大的技术,它通过使网络能够学习判别表征来提升视频语言学习。在这里,预定义的视频文本对之间的全局语义交互被用于学习。
这种方法的一个大问题是,它损害了模型在下游任务中的质量。这些模型通常使用视频文本语义来执行粗粒度特征对齐。因此,对比视频模型无法对齐精细调整的注释,以捕捉视频的细微差别和可解释性。解决细粒度注释问题的最简单方法是创建一个大规模的高质量注释数据集,但遗憾的是,目前还没有这样的数据集,尤其是对于视觉语言模型而言。本文将讨论通过游戏解决细粒度对齐问题的最新研究。
北京大学和鹏程实验室的研究人员引入了一种分层 Banzhaf 交互方法来解决通用视频语言表征学习中的对齐问题,将其建模为多变量合作博弈。作者设计了这个游戏,将视频和文本作为玩家。为此,他们将多个表征的集合分组为一个联盟,并使用博弈论交互指数 Banzhaf 交互来衡量联盟成员之间的合作程度。
研究团队在其会议论文的基础上扩展了分层 Banzhaf 交互的学习框架,利用跨模态语义测量作为视频文本合作游戏中玩家的功能特征。在本文中,作者提出了 HBI V2,它利用单模态和跨模态表征来减轻 Banzhaf 指数中的偏差并增强视频语言学习。在 HBI V2 中,作者通过整合单模态和跨模态表征来重建游戏的表征,这些表征经过动态加权以确保各个表征的细粒度,同时保留跨模态交互。
在影响方面,HBI V2 凭借执行各种下游任务的能力超越了 HBI,从文本视频检索到 VideoQA 和视频字幕。为了实现这一点,作者将之前的结构修改为一个灵活的编码器-解码器框架,其中解码器适用于特定任务。
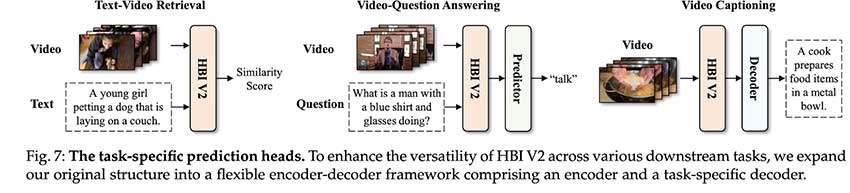
HBI V2 的这个框架分为三个子模块:表示重建、HBI 模块和特定任务预测头。第一个模块促进了单模态和跨模态组件的融合。研究团队使用 CLIP 生成两种表示。对于视频输入,帧序列使用 ViT 编码成嵌入。这种组件集成有助于克服动态编码视频的问题,同时保留固有的粒度和适应性。对于 HBI 模块,作者将视频文本建模为多元合作游戏中的玩家,以处理细粒度交互期间的不确定性。前两个模块为框架提供了灵活性,使第三个模块能够针对给定任务进行定制,而无需复杂的多模态融合或推理阶段。
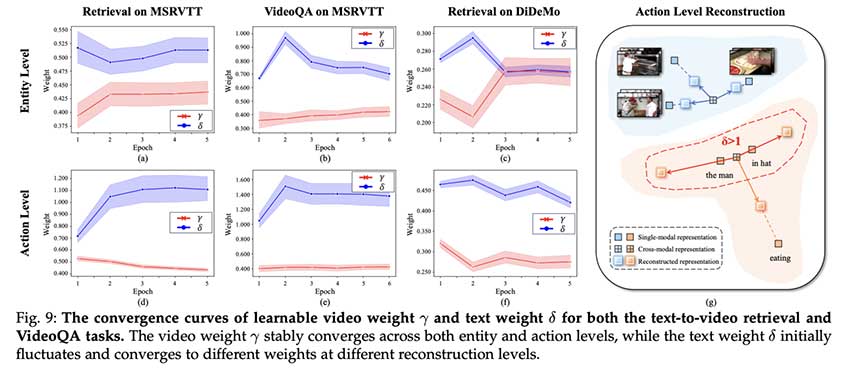
论文中,HBI V2 在各种文本视频检索、视频问答和视频字幕数据集上进行了评估,每个数据集都采用了多个合适的指标。令人惊讶的是,所提出的方法在所有下游任务上都优于其前身和所有其他方法。此外,该框架在 MSVD-QA 和 ActivityNet-QA 数据集上取得了显著的进步,这评估了其问答能力。关于可重复性和推理,整个测试数据的推理时间为 1 秒。
结论:所提出的方法独特而有效地利用了 Banzhaf 交互,无需人工注释即可为视频文本关系提供细粒度标签。HBI V2 在前一个 HBI 的基础上进行了扩展,将单一表示的粒度融入跨模态表示中。该框架表现出优越性,并具有执行各种下游任务的灵活性。
更多详细信息请查看:https://github.com/jpthu17/HBI
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/55161.html
