
多模态大型语言模型 (MLLM) 的发展为人工智能带来了新的机遇。然而,在整合视觉、语言和语音模态方面仍然存在重大挑战。虽然许多 MLLM 在视觉和文本方面表现良好,但整合语音仍然是一个障碍。语音是人类互动的自然媒介,在对话系统中起着至关重要的作用,但模态之间的差异——空间与时间数据表示——在训练过程中会产生冲突。传统的系统依赖于单独的自动语音识别 (ASR) 和文本转语音 (TTS) 模块,通常速度很慢,不适用于实时应用。
来自南京大学、腾讯优图实验室、厦门大学和中国科学院人工智能研究所的研究人员推出了 VITA-1.5,这是一种多模态大型语言模型,通过精心设计的三阶段训练方法将视觉、语言和语音融为一体。与依赖外部 TTS 模块的前身 VITA-1.0 不同,VITA-1.5 采用端到端框架,减少了延迟并简化了交互。该模型结合了视觉和语音编码器以及语音解码器,可实现近乎实时的交互。通过渐进式多模态训练,它解决了模态之间的冲突,同时保持了性能。研究人员还公开了训练和推理代码,促进了该领域的创新。
技术细节和优势
VITA-1.5 旨在平衡效率和能力。它使用视觉和音频编码器,对图像输入采用动态修补,对音频采用下采样技术。语音解码器结合了非自回归 (NAR) 和自回归 (AR) 方法,以确保流畅且高质量的语音生成。训练过程分为三个阶段:
- 视觉语言训练:此阶段侧重于视觉对齐和理解,使用描述性标题和视觉问答 (QA) 任务来建立视觉和语言模式之间的联系。
- 音频输入调整:音频编码器使用语音转录数据与语言模型对齐,从而实现有效的音频输入处理。
- 音频输出调整:语音解码器使用文本-语音配对数据进行训练,实现连贯的语音输出和无缝的语音到语音交互。
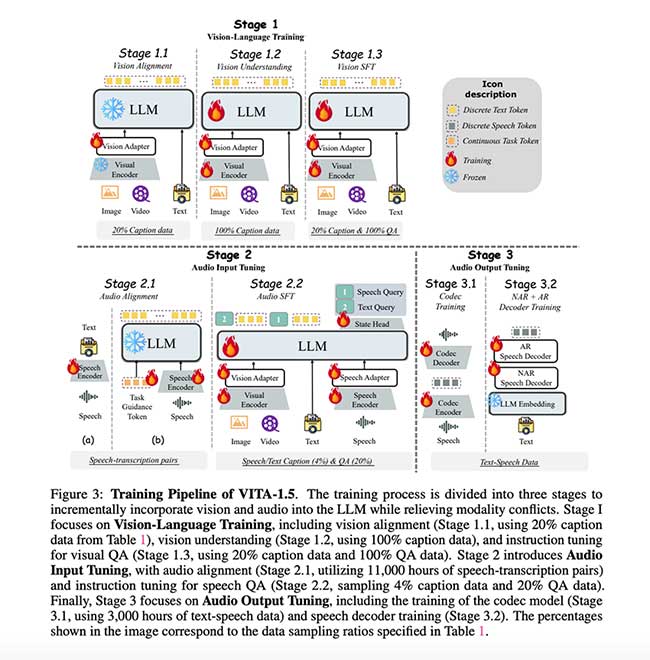
这些策略有效地解决了模态冲突,使 VITA-1.5 能够无缝处理图像、视频和语音数据。集成方法增强了实时可用性,消除了传统系统中常见的瓶颈。
结果和见解
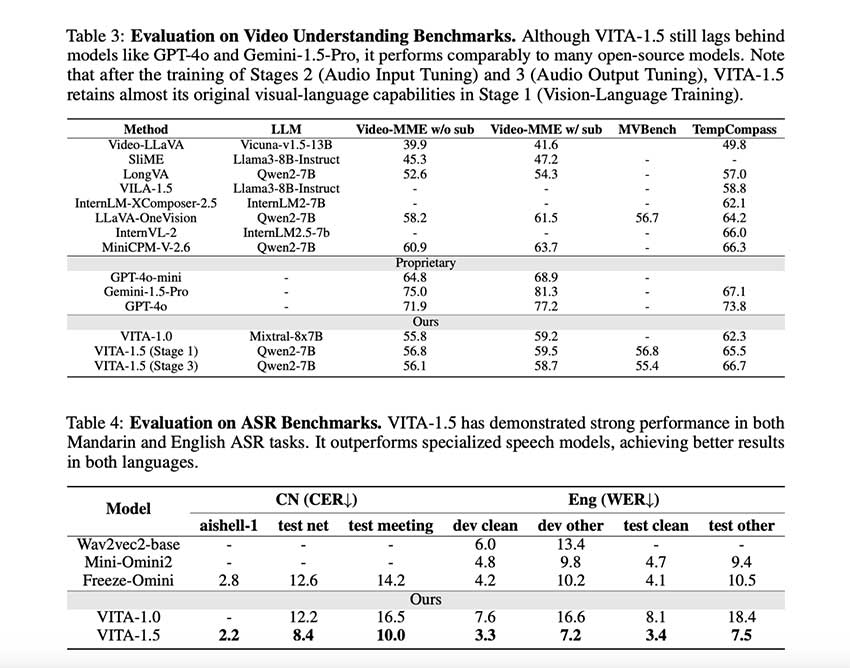
VITA-1.5 在各种基准测试中的评估证明了其强大的功能。该模型在图像和视频理解任务中表现出色,取得了与领先的开源模型相当的结果。例如,在 MMBench 和 MMStar 等基准测试中,VITA-1.5 的视觉语言能力与 GPT-4V 等专有模型相当。此外,它在语音任务中表现出色,普通话字符错误率 (CER) 较低,英语单词错误率 (WER) 较低。重要的是,加入音频处理不会损害其视觉推理能力。该模型在各种模态中的一致性能凸显了其实际应用的潜力。
结论
VITA-1.5 代表了一种解决多模态集成挑战的深思熟虑的方法。通过解决视觉、语言和语音模态之间的冲突,它为实时交互提供了一种连贯而有效的解决方案。它的开源可用性确保研究人员和开发人员可以在其基础上继续发展,推动多模态 AI 领域的发展。VITA-1.5 不仅增强了当前的能力,还为 AI 系统指明了更加集成和互动的未来。
GitHub地址:https://github.com/VITA-MLLM/VITA
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/55124.html
