
文本转音频生成技术彻底改变了音频内容的创建方式,使传统上需要大量专业知识和时间的流程自动化。该技术可以将文本提示转换为丰富多样且富有表现力的音频,从而简化音频制作和创意行业的工作流程。将文本输入与逼真的音频输出相结合,为多媒体叙事、音乐和声音设计等应用开辟了可能性。
文本转音频系统面临的一个重大挑战是确保生成的音频与文本提示完全一致。当前的模型通常无法捕捉复杂的细节,从而导致完全不一致。一些输出会忽略基本元素或引入意外的音频伪影。缺乏优化这些系统的标准化方法进一步加剧了这一问题。与语言模型不同,文本转音频系统无法从强大的对齐策略(例如带有人工反馈的强化学习)中受益,因此有很大的改进空间。
以前的文本转音频生成方法严重依赖基于扩散的模型,例如 AudioLDM 和 Stable Audio Open。虽然这些模型提供了不错的质量,但它们也有局限性。它们依赖于大量的去噪步骤,这使得它们在计算上非常昂贵且耗时。此外,许多模型都是在专有数据集上进行训练的,这限制了它们的可访问性和可重复性。这些限制阻碍了它们的可扩展性和有效处理多样化和复杂提示的能力。
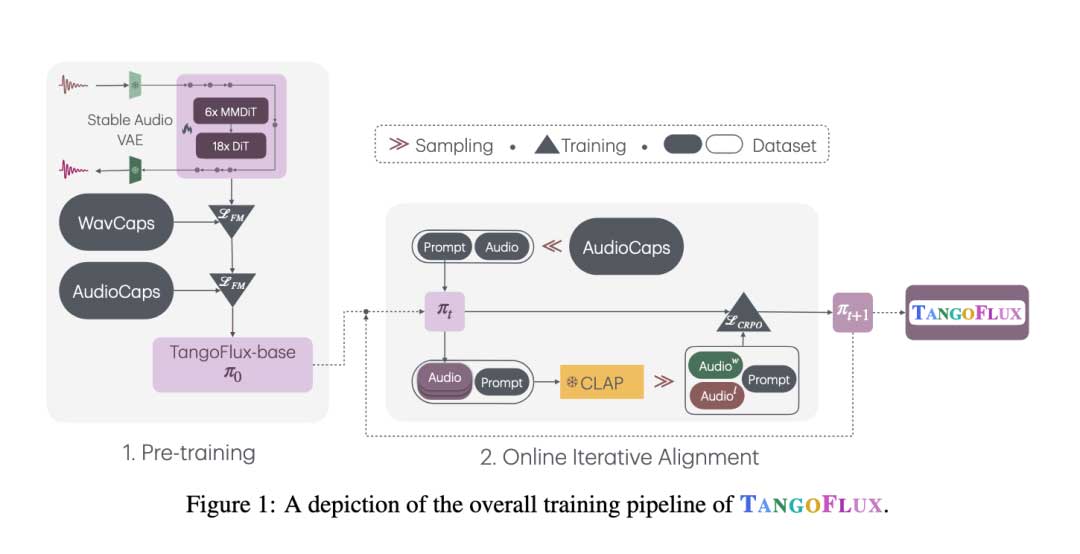
为了应对这些挑战,新加坡科技设计大学 (SUTD) 和 NVIDIA 的研究人员推出了先进的文本转音频生成模型 TANGOFLUX。该模型旨在实现高效和高质量的输出,与以前的方法相比取得了显著的改进。TANGOFLUX 利用 CLAP-Ranked Preference Optimization (CRPO) 框架来改进音频生成,并确保与文本描述迭代对齐。其紧凑的架构和创新的训练策略使其能够表现出色,同时需要更少的参数。
TANGOFLUX 集成了先进的方法,以实现先进的结果。它采用了一种混合架构,结合了扩散变换器 (DiT) 和多模态扩散变换器 (MMDiT) 块,使其能够处理可变持续时间的音频生成。与依赖多个去噪步骤的传统扩散模型不同,TANGOFLUX 使用流匹配框架来创建从噪声到输出的直接整流路径。这种整流方法减少了高质量音频生成所需的计算步骤。
在训练期间,系统结合了文本和持续时间调节,以确保精确捕捉输入提示的细微差别和音频输出的所需长度。CLAP 模型通过生成偏好对并迭代优化它们来评估音频和文本提示之间的对齐,这一过程受到语言模型中使用的对齐技术的启发。
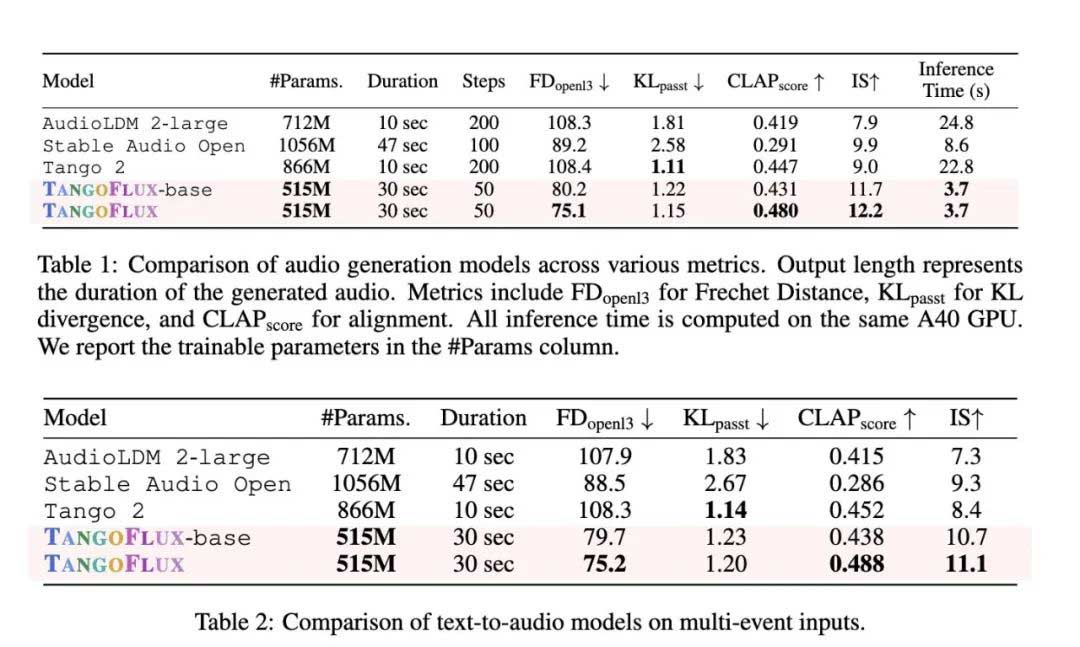
在性能方面,TANGOFLUX 在多个指标上都超越了其前代。它使用单个 A40 GPU 仅用 3.7 秒就生成了 30 秒的音频,表现出卓越的效率。该模型的 CLAP 得分为 0.48,FD 得分为 75.1,均表明其音频输出质量高且文本对齐。与 CLAP 得分为 0.29 的 Stable Audio Open 相比,TANGOFLUX 显著提高了对齐精度。
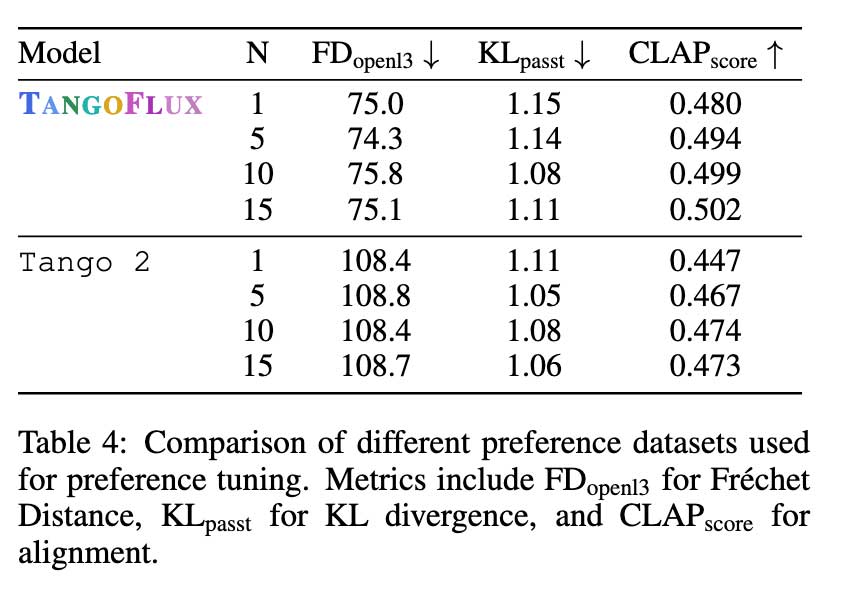
在多事件场景中,提示包含多个不同的事件,TANGOFLUX 表现出色,展示了其有效捕捉复杂细节和时间关系的能力。该系统的稳健性进一步凸显在其即使在减少采样步骤的情况下仍能保持性能的能力,这一特性增强了其在实时应用中的实用性。人工评估证实了这些结果,TANGOFLUX 在总体质量和及时相关性等主观指标中得分最高。注释者一致认为其输出比 AudioLDM 和 Tango 2 等其他模型更清晰、更一致。
研究人员还强调了 CRPO 框架的重要性,该框架允许创建一个优于 BATON 和 Audio-Alpaca 等替代方案的偏好数据集。该模型通过在每次训练迭代期间生成新的合成数据,避免了通常与离线数据集相关的性能下降。
该研究通过引入 TANGOFLUX 成功解决了文本转音频系统的关键限制,TANGOFLUX 将效率与卓越性能相结合。其对整流流和偏好优化的创新使用为该领域的未来发展树立了标杆。这一发展提高了生成的音频的质量和对齐,并展示了可扩展性,使其成为广泛采用的实用解决方案。
信息源于:marktechpost
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
