
将视频分解成视觉模型所需的更小、更有意义的部分仍然颇具挑战性,特别是长视频。视觉模型依靠这些较小的部分(称为标记)来处理和理解视频数据,但高效地创建这些标记却十分困难。虽然近期的工具比旧方法实现了更好的视频压缩,但它们难以有效处理大型视频数据集。一个关键问题是它们无法充分利用时间连贯性,即视频帧在短时间内往往相似的自然模式,视频编解码器利用这种模式实现高效压缩。这些工具的训练计算成本也很高,并且仅限于短片段,因此在捕捉模式和处理长视频方面效果不佳。
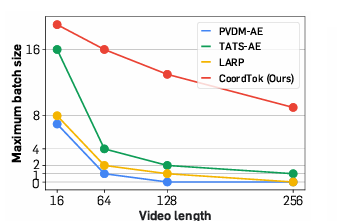
当前的视频标记方法计算成本高,难以有效处理长视频序列。早期方法使用图像标记器逐帧压缩视频,但忽略了帧之间的自然连续性,从而降低了其有效性。后来的方法引入了时空层,减少了冗余,并使用了自适应编码,但它们仍然需要在训练期间重建整个视频帧,这将它们限制为短片段。自回归方法、掩蔽生成变压器和扩散模型等视频生成模型也仅限于短序列。
为了解决这个问题,来自韩国科学技术研究院和加州大学伯克利分校的研究人员提出了CoordTok,它可以学习从基于坐标的表示到输入视频相应块的映射。受3D 生成模型的最新进展的启发,CoordTok将视频编码为分解的三平面表示,并重建与随机采样的 (x, y, t) 坐标相对应的块。这种方法允许直接在长视频上训练大型标记器模型,而无需过多的资源。视频被分成时空块并使用变换器层进行处理,解码器将采样的 (x, y, t) 坐标映射到相应的像素。这在保持视频质量的同时降低了内存和计算成本。
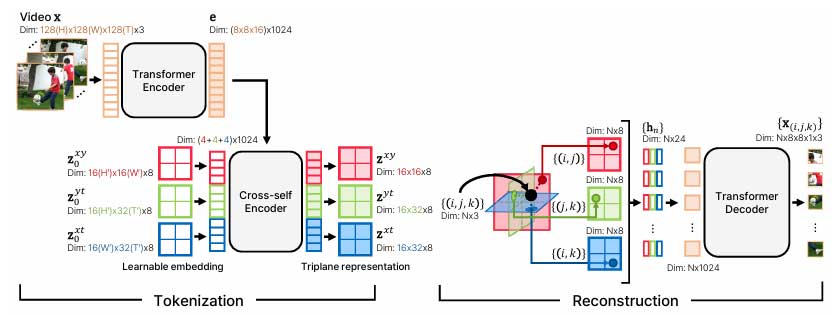
在此基础上,研究人员通过引入分层架构来更新 CoordTok,以便高效处理视频,该架构可以掌握视频中的局部和全局特征。该架构代表一个分解的三平面,用于处理空间和时间块,使长时间视频处理更容易,而无需过度使用计算资源。这种方法大大降低了内存和计算要求,并保持了较高的视频质量。

研究人员通过添加一个可以捕捉视频局部和全局特征的分层结构来提高性能。这种结构允许模型使用 Transformer 层更有效地处理时空块,这有助于生成分解的三平面表示。因此,CoordTok 可以处理更长的视频而不需要过多的计算资源。
例如,CoordTok 将128×128分辨率的128 帧视频编码为1280 个标记,而基线需要6144或8192个标记才能实现类似的重建质量。通过使用ℓ2损失和LPIPS损失进行微调,模型的重建质量得到进一步改善,提高了重建帧的准确性。这种策略组合将内存使用量降低了50%并降低了计算成本,同时保持了高质量的视频重建,其中CoordTok -L 等模型实现了26.9的PSNR。
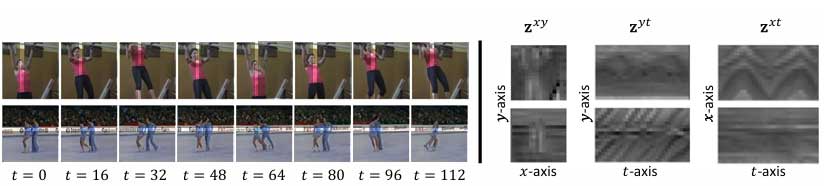
总之,研究人员提出的框架CoordTok被证明是一种高效的视频标记器,它使用基于坐标的表示来降低编码长视频时的计算成本和内存要求。
它允许对视频生成模型进行内存高效的训练,从而可以用更少的标记处理长视频。但是,它对于动态视频来说还不够强大,并提出了进一步的潜在改进,例如使用多个内容平面或自适应方法。这项工作可以作为未来可扩展视频标记器和生成的研究的起点,这对理解和生成长视频大有裨益。
查看更多详细信息:https://huiwon-jang.github.io/coordtok/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54954.html
