
自回归 LLM 是复杂的神经网络,通过顺序预测生成连贯且上下文相关的文本。这些 LLMS 擅长处理大型数据集,并且在翻译、摘要和对话式 AI 方面非常强大。然而,实现高质量的视觉生成通常以增加计算需求为代价,尤其是对于更高分辨率或更长的视频。尽管使用压缩潜在空间进行高效学习,但视频扩散模型仅限于固定长度的输出,并且在GPT等自回归模型中缺乏上下文适应性。
当前的自回归视频生成模型面临许多限制。扩散模型可以出色地完成文本转图像和文本转视频任务,但依赖于固定长度的标记,这限制了它们在视频生成中的多功能性和可扩展性。自回归模型通常会遭受矢量量化问题,因为它们将视觉数据转换为离散值标记空间。更高质量的标记需要更多的标记,而使用这些标记会增加计算成本。虽然VAR和MAR等进步提高了图像质量和生成建模,但它们在视频生成中的应用仍然受到建模效率低下和适应多上下文场景的挑战的限制。
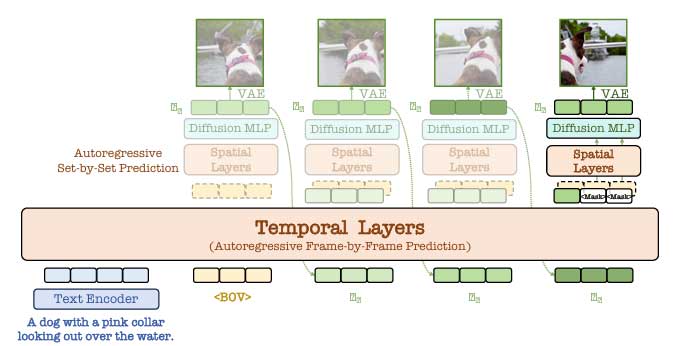
针对这些问题,来自北京邮电大学、中国科学院信息通信技术研究所、大连理工大学和北京航空航天大学的研究人员提出了一种用于视频生成的非量化自回归模型——NOVA。NOVA 通过随时间顺序预测帧并以灵活的顺序预测每帧内的空间标记集来生成视频。该模型通过分离帧和空间集的生成方式,结合了基于时间和基于空间的预测。它使用预先训练的语言模型来处理文本提示,并使用光流来跟踪运动。对于基于时间的预测,该模型应用分块因果掩蔽方法,而对于基于空间的预测,它使用双向方法来预测标记集。该模型引入了缩放层和平移层以提高稳定性,并使用正弦余弦嵌入来获得更好的定位。它还增加了扩散损失来帮助预测连续空间中的标记概率,从而使训练和推理更加高效,并提高视频质量和可扩展性。

研究人员使用高质量数据集训练NOVA ,首先从DataComp、COYO、Unsplash和JourneyDB等来源获取1600万个图像-文本对,后来扩展到来自LAION、DataComp和COYO的6 亿个对。对于文本转视频,研究人员使用了来自Panda – 70M和其他内部数据集的1900 万个视频-文本对,加上来自Pexels(一个基于Emu2-17B生成的描述的字幕引擎)的100 万个对。
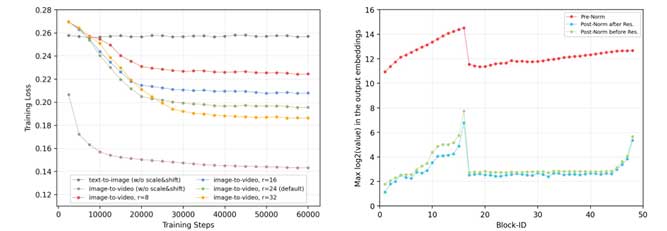
NOVA 的架构包括一个空间AR层、一个去噪MLP块和一个用于处理空间和时间成分的16 层编码器-解码器结构。时间编码器-解码器维度范围从768 到 1536,去噪 MLP 有三个1280维的块。预先训练的 VAE 模型使用掩蔽和扩散调度程序捕获图像特征。NOVA 在 16 个A100节点上使用 AdamW 优化器进行了训练。它首先接受文本转图像任务的训练,然后接受文本转视频任务的训练。
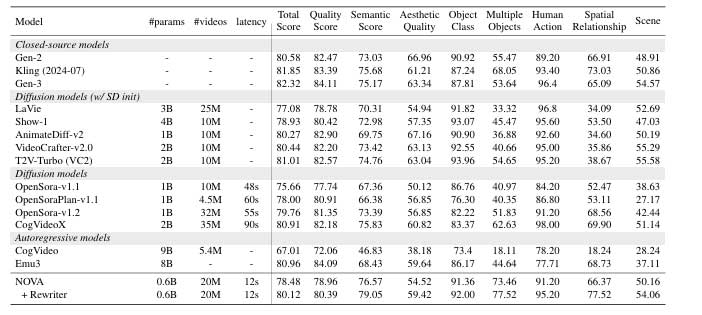
T2I-CompBench、GenEval和DPG-Bench的评估结果表明,NOVA 在文本转图像和文本转视频生成任务中的表现优于PixArt-α和SD v1/v2等模型。NOVA 生成的图像和视频质量更高,视觉效果更清晰、更细腻。它还提供更准确的结果,更好地匹配文本输入和生成的输出。
总之,所提出的 NOVA 模型显著推进了文本到图像和文本到视频的生成。该方法通过将时间逐帧和空间逐集预测与高质量输出相结合,降低了计算复杂度并提高了效率。其性能超越了现有模型,具有接近商业级的图像质量和视频保真度。这项工作为未来的研究奠定了基础,为开发可扩展模型和实时视频生成提供了基础,并为该领域的进步开辟了新的可能性。
更多详细信息:https://github.com/baaivision/nova
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54890.html
