
说话人日志任务(Speaker Diarization)是指将音频划分为属于不同说话人的多个段落。其目标是确定音频中有多少个不同的说话人,并且识别出每个说话人在音频中的开始时间和结束时间。
3D-Speaker开源工具针对该功能进行了更新升级,在部分基准测试上获得优秀水平。
代码仓库
Github地址:https://github.com/modelscope/3D-Speaker/blob/main/egs/3dspeaker/speaker-diarization
立即体验:https://github.com/modelscope/3D-Speaker/blob/main/egs/3dspeaker/speaker-diarization/run_audio.sh
核心模型与算法亮点
说话人日志中最为常用的方法是基于“特征提取-无监督聚类”的框架,其一般串联语音活动端点检测(voice activity detection,VAD),划窗分段,特征提取,无监督聚类4个模块进行识别。由于该范式无法识别重叠语音说话人(overlapping speaker),最近基于端到端说话人日志(end-to-end diarization,EEND)网络的方法逐渐被提出并受到了广泛的关注。
EEND网络输入语音帧后能直接输出每个说话人的语音活动检测结果,因而可以识别任意说话人重叠区域。但是EEND也受限制于真实标注对话数据稀少、人数估计困难和难以计算长时音频等因素,而无法在实际应用中单独使用。合适搭配两者通常能突破各自的效果上限而成为当前最佳说话人日志系统的主流方案。
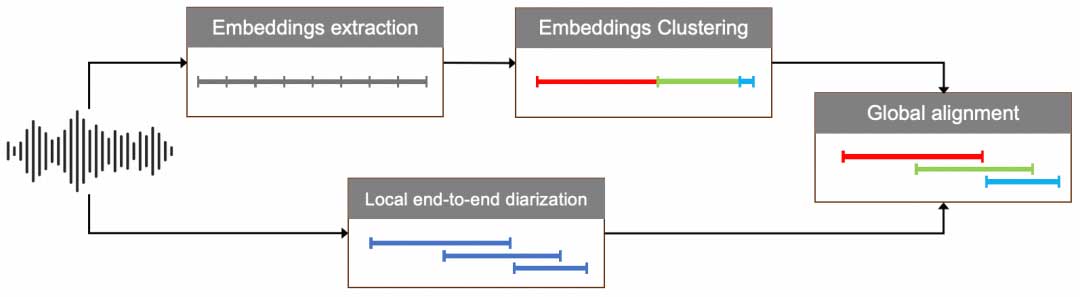
3D-Speaker针对此范式更新了Speaker diarization框架,从基于“特征提取-无监督聚类”的框架升级至和EEND并行处理框架,EEND分支负责检测局部的overlapping speaker,输出细粒度的帧级结果;“特征提取-无监督聚类”负责检测全局人数,输出粗粒度的说话人ID段落结果。后处理对齐模块将对齐两者的结果,输出每个说话人的语音活动区域。其中speaker embedding网络采用大规模说话人识别数据训练的CAM++模型,EEND采用来自于pyannote/segmentation开源的SincNet模型。
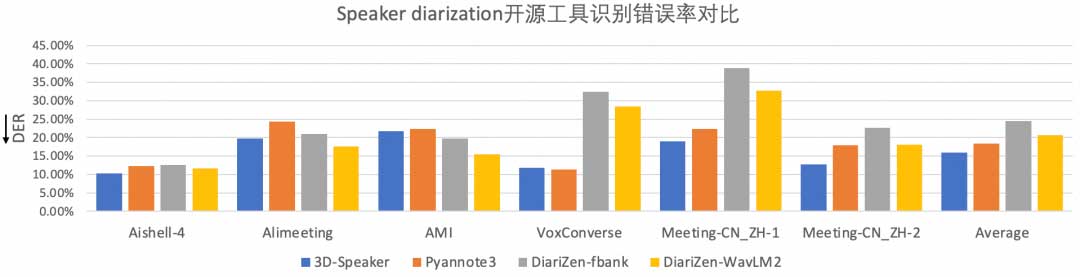
该方法在多个基准测试中,部分识别结果达到优秀水平。由于该框架中采用的模型均为小参数量模型,整个流程推理速度在CPU设备上实际测试RTF达0.03,相比其他speaker diarization开源工具具有明显的效率优势,可用于大规模对话数据进行高效推理。

效果体验
点击以下链接即可轻松上手:https://github.com/modelscope/3D-Speaker/blob/main/egs/3dspeaker/speaker-diarization/run_audio.sh
相关文献参考:
【1】 H. Wang et al, “CAM++: A Fast and Efficient Network For Speaker Verification Using Context-Aware Masking,” in Proc. Interspeech 2023.
【2】A. Plaquet and H. Bredin, “Powerset multi-class cross entropy loss for neural speaker diarization,” in Proc. Interspeech 2023.
【3】J. Han et al, “Leveraging Self-Supervised Learning for Speaker Diarization,”arXiv abs/2409.09408.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
