
大型语言模型 (LLM) 是众多应用的支柱,例如对话代理、自动内容创建和自然语言理解任务。它们的有效性在于它们能够从庞大的数据集中建模和预测复杂的语言模式。然而,由于训练的计算成本巨大,开发 LLM 是一项重大挑战。这涉及在海量语料库上优化具有数十亿个参数的模型,需要大量的硬件和时间。因此,需要创新的训练方法来缓解这些挑战,同时保持或提高 LLM 的质量。
在开发 LLM 时,传统的训练方法效率低下,因为它们会平等对待所有数据,无论其复杂程度如何。这些方法不会优先考虑可以加快学习速度的特定数据子集,也不会利用现有模型来协助训练。这通常会导致不必要的计算工作量,因为简单的实例与复杂的实例一起处理,且没有进行区分。此外,标准的自监督学习(其中模型预测序列中的下一个标记)无法利用规模较小、计算成本较低的模型的潜力,而这些模型可以为大型模型的训练提供信息和指导。
知识蒸馏(Knowledge Distillation,KD)通常用于将知识从较大、训练有素的模型转移到较小、更高效的模型。然而,这个过程很少被逆转,即较小的模型协助训练较大的模型。这一差距代表着错失的机会,因为较小的模型尽管容量有限,但可以为数据分布的特定区域提供有价值的见解。它们可以有效地识别“简单”和“困难”的实例,这可以显著影响 LLM 的训练动态。
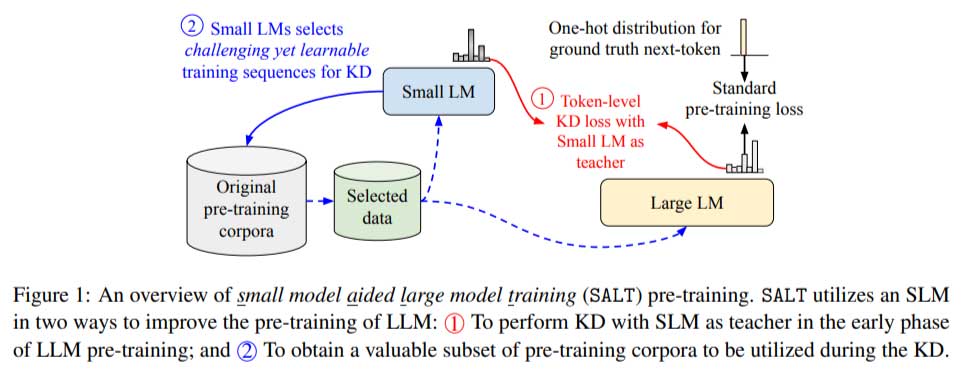
谷歌研究院和谷歌 DeepMind 的研究人员提出了一种名为“小型模型辅助大型模型训练” (SALT)的新方法来解决上述挑战。该方法创新性地采用了较小的语言模型(SLM)来提高 LLM 训练的效率。SALT通过两种方式利用 SLM:在初始训练阶段提供软标签作为额外的监督来源,并选择对学习特别有价值的数据子集。该方法确保 LLM 在 SLM 的指导下优先考虑信息丰富且具有挑战性的数据序列,从而降低计算要求,同时提高训练模型的整体质量。
SALT 采用两阶段方法运作:
- 在第一阶段,SLM 充当教师,通过知识提炼将其预测分布转移到 LLM。此过程侧重于在 SLM 擅长的领域将 LLM 的预测与 SLM 的预测保持一致。此外,SLM 还会识别既具有挑战性又可学习的数据子集,使 LLM 能够在训练初期专注于这些关键示例。
- 第二阶段过渡到传统的自监督学习,允许 LLM 独立完善对更复杂数据分布的理解。
这个两阶段过程平衡了利用 SLM 的优势和最大化 LLM 的固有能力。
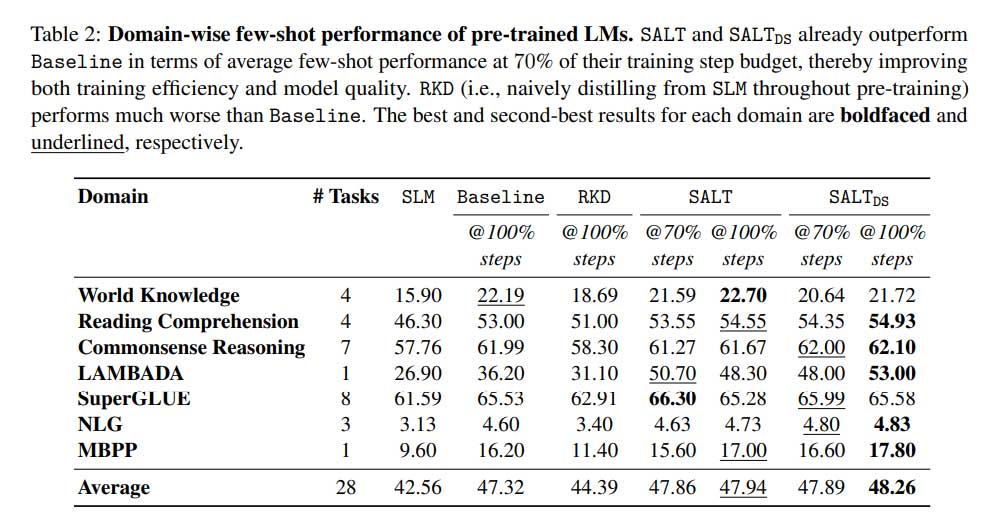
在实验结果中,使用 SALT 在 Pile 数据集上训练的 28 亿参数 LLM 的表现优于使用传统方法训练的基线模型。值得注意的是,SALT 训练的模型在阅读理解、常识推理和自然语言推理等基准测试中取得了更好的结果,同时仅使用了 70% 的训练步骤。这意味着挂钟训练时间减少了约 28%。此外,使用 SALT 预训练的 LLM 在下一个标记预测中的准确率为 58.99%,而基线为 57.7%,并且对数困惑度较低,为 1.868,而基线为 1.951,这表明模型质量有所提高。
该研究的主要结论包括:
- SALT 将训练 LLM 的计算要求降低了近 28%,主要是通过使用较小的模型来指导初始训练阶段。
- 该方法在各种任务中始终能够产生表现更佳的 LLM,包括总结、算术推理和自然语言推理。
- 通过使较小的模型能够选择具有挑战性但可学习的数据,SALT 确保 LLM 专注于高价值数据点,从而加快学习速度而不影响质量。
- 该方法对于计算资源有限的机构尤其有前景。它利用较小、成本较低的模型来协助开发大规模的 LLM。
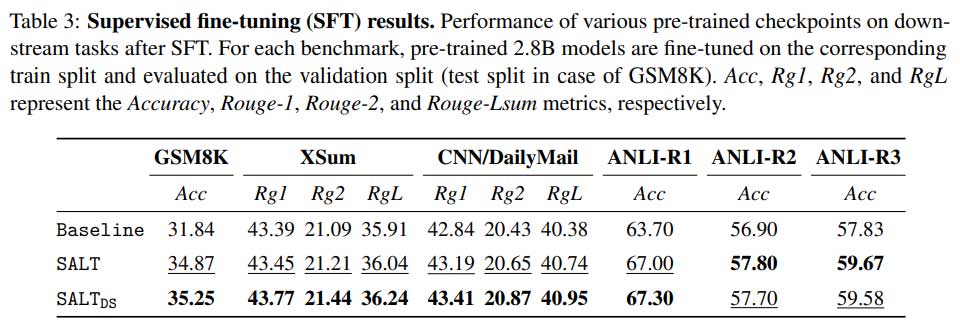
- 经过监督微调后,SALT 训练的模型在小样本评估和下游任务中表现出更好的泛化能力。
总之,SALT 通过将较小的模型转变为有价值的训练辅助工具,有效地重新定义了 LLM 训练的范式。其创新的两阶段流程实现了效率和有效性的罕见平衡,使其成为机器学习的开创性方法。SALT 将有助于克服资源限制、提高模型性能和实现尖端 AI 技术的民主化。这项研究强调了重新思考传统做法和利用现有工具以更少的投入实现更多成果的重要性。
论文地址:https://arxiv.org/abs/2410.18779
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54800.html
