
视频质量评估(Video Quality Assessment, VQA) 旨在以高度符合人类感知的方式预测视频质量。然而,传统基于自然图像或视频统计特性的VQA模型在面对用户生成内容(User-Generated Content, UGC)时表现有限,尤其是在大规模多样化视频数据集中表现出其局限性。随着深度神经网络和多模态大模型(Large Multimodality Models, LMMs)的快速发展,这一领域取得了显著进展。相比于以往基于手工设计特征的模型,基于深度学习的VQA模型展现了更强的性能,其发展得益于内容多样化的大规模人工标注数据集的支持,这些数据集提供了反映主观感知的真实视频质量数据。
作者: Qi Zheng, Yibo Fan, Leilei Huang, Tianyu Zhu, Jiaming Liu, Zhijian Hao, Shuo Xing, Chia-Ju Chen, Xiongkuo Min, Alan C. Bovik, Zhengzhong Tu
来源: 复旦大学 VIP-Lab, 华东师范大学, 上海交通大学 MM-Lab, 得克萨斯大学奥斯汀分校 LIVE-Lab, 得克萨斯农工大学 TACO-Group
论文题目: Video Quality Assessment: A Comprehensive Survey
论文链接: https://arxiv.org/abs/2412.04508
代码链接: https://github.com/taco-group/Video-Quality-Assessment-A-Comprehensive-Survey
本文对VQA算法的最新进展进行了全面综述,包括主观与客观质量评估方法、主流数据集的总结以及过去二十年中全参考和无参考算法的发展,重点探讨了基于深度学习的VQA模型。此外,我们对现有算法在新兴内容数据集上的效果和适应性进行了比较,深入探讨了有效神经网络模块在VQA模型中的应用。我们还分析了深度学习VQA研究在实际应用中的局限性和挑战,并详细阐述了未来研究的重要方向。我们希望这篇综述能够激发视觉分析领域的进一步研究,通过解决现有难题并探索新的研究路径,未来的研究有望充分释放VQA在媒体制作、通信等领域的潜力。
引言
近年来,流媒体技术和平台迅速发展,使视频内容成为互联网流量的主导形式。流媒体和社交媒体视频已深度融入数十亿人的日常生活,尤其随着Web 2.0的兴起,用户生成内容(UGC)呈现爆发式增长。同时,生成式人工智能(AIGC)的进步进一步推动了内容创作的革新,使各种媒体平台上的内容生成与转化更加高效便捷。在此背景下,如何提高云端视频转码技术的效率,并为用户提供令人满意的视觉体验(Quality of Experience, QoE),已成为视频服务提供商的核心任务。然而,在不断变化的网络条件下,平衡这些需求仍是一项长期存在的重大挑战。感知设计的视频质量评估模型在全球通信网络和视频处理链中扮演着“质量裁判”的角色,特别是在视频编码、增强和重建算法中,对视觉内容质量的监测和评估至关重要。
视频质量研究大致分为主观评估和客观评估两类。
主观视频质量评估
需要人在受控环境下观看视频内容,并对每段视频的感知质量进行评分。这些原始评分通常会被归一化并计算平均值,形成主观评价分数(MOS)或差异主观评价分数(DMOS)。尽管主观评估耗时费力,但它为基准测试、模型开发、对比与校准提供了宝贵的数据基础。
客观视频质量评估
则通过算法模型预测视频内容的感知质量。根据参考信号的获取情况,客观评估模型可分为全参考(Full-Reference, FR)、半参考(Reduced-Reference, RR)和无参考(No-Reference, NR)三类。全参考模型通过对比高质量参考视频与失真视频的视觉差异来评估质量,可视为感知视频保真度模型。半参考模型类似于FR模型,但仅需从参考视频中提取少量信号信息即可进行质量预测。无参考模型则在没有任何参考信号的情况下预测视频质量,在实践中尤为重要。例如,用户在YouTube或抖音等社交平台上传的视频通常没有可用的参考信号,此时NR模型是唯一能够分析和监控这些真实失真内容的工具。
视频可能会受到多种不同失真类型的影响,包括噪声、模糊、振铃效应、条带、压缩和块状效应等,这些失真不仅很难建模,而且通常会共同出现并相互作用,同时它们对视频质量的影响也因内容的不同而有所不同。此外,问题的复杂性还因多种失真的交织而加剧,尤其是当涉及复杂的物体和相机运动时。更进一步,提取质量感知的视频特征并预测视频质量,需要同时考虑空间和时间上的因素,还要考虑到人类的记忆效应,这使得问题变得更加复杂。
传统的视频质量评估(VQA)模型通常依赖于计算感知相关的视觉差异和/或自然统计规律。这些模型通常使用简单的映射引擎,例如支持向量回归(SVR),来学习如何根据失真感知特征预测质量。当然,特征提取过程对于这些VQA模型的成功至关重要。尽管这些方法在全球行业中已取得显著成功,但仍有很大的改进空间。

幸运的是,深度学习通过利用大量人工标注的图像数据集得到了复兴,这为高层次和低层次的计算机视觉任务带来了重要进展。基于海量数据训练的神经网络架构能够捕捉语义特征和通用表示,减少了对手动特征选择的依赖,并展现了显著的泛化能力。近期,在图像和视频领域创建大规模心理测量数据集的进展,进一步推动了深度学习在质量预测中的应用。现代的深度VQA模型通常采用先在丰富数据的辅助任务上进行预训练,然后在更专注的视频质量数据集上进行微调。尽管这些数据集越来越全面,但由于进行大规模主观评估的成本高昂,数据量仍然不足以训练大型模型。深度网络的应用显著提升了质量预测的性能,通过捕捉多样的失真现象和高层次的语义内容,同时与视觉感知对齐。然而,深度学习在视频质量评估中的潜力仍未完全释放,主要受限于大规模标注心理测量数据集的稀缺,以及我们对人类视觉质量感知的理解有限。
最近,随着大模型的进展(例如具有大量参数并在海量数据上训练的模型),机器的感知认知得到了显著提升。许多研究者正在探索如何将大语言模型(LLMs)和大多模态模型(LMMs)应用于IQ/VQA任务,如扩展大型模型中嵌入的语义感知特征,或通过质量感知提示提高质量评估的可解释性等。
为了帮助更好地理解当前视频质量数据集的进展,以及基于深度学习模型的发展,我们对视频质量建模领域的过去研究、近期成果和最新技术进行了全面综述。
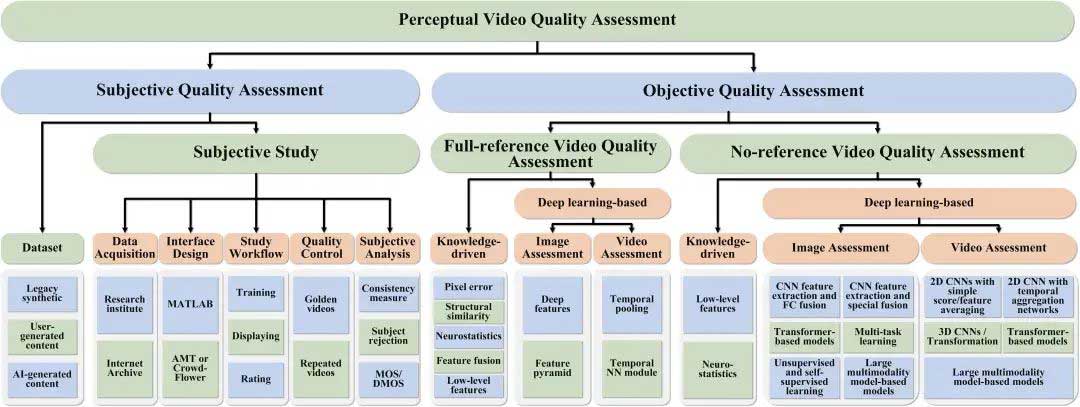
我们的主要贡献包括:
- 我们回顾了主观(数据集)和客观(算法)的质量评估模型,不仅提供了详细的分类体系,还对其演变和核心方法进行了深入分析。
- 我们向读者介绍了如何开展主观质量评估研究,并详细综述了许多广受欢迎和具有代表性的视频质量数据集,这些数据集涵盖了不同的视频内容类型及其应用场景。
- 我们总结了传统的图像和视频质量评估方法,并在此基础上深入讨论了基于深度学习的最新视频质量评估(VQA)模型,同时还探讨了常用的感知损失函数。
- 我们在新兴内容数据集上比较了典型的图像质量评估(IQA)和视频质量评估(VQA)模型的表现,从时空信息建模和大模型中先验知识的使用等角度,为模型设计提供了洞见。
- 我们探讨了基于深度学习的VQA模型的实际应用,包括在大规模商业场景中的应用,分析了当前仍然存在的核心挑战,并展望了未来改进和应用这些模型的机会,以激发视频流媒体和社交媒体领域的研究和工业部署。
论文结构如下:第二章介绍了神经统计视频失真模型和深度学习VQA模型中的关键网络层。第三章总结了主观视频质量评估方法及常用数据集。第四章回顾了有参考和无参考的VQA模型,重点讨论了深度学习方法和损失函数。第五章对新兴内容数据集上的代表性VQA模型性能进行比较。第五部分讨论了实际应用和面临的挑战。最后,第六部分展望了未来的研究方向。
基础模型
为了引出主要讨论内容,我们首先简要回顾了一些经典的视频质量评估模型,包括基于结构相似性的评估方法以及利用神经统计失真测量的方法。这些模型深深植根于视觉神经科学的基本原理,与基于深度感知的视频质量评估模型中早期网络层的处理过程密切相关。
我们也简要回顾了构成现代深度网络的主要网络层类型,包括多层感知机、卷积神经网络、循环神经网络、注意力层、Transformer。另外,大模型在视觉理解任务中表现出了卓越的能力,将其用于感知质量评估是一种直观且合理的选择,因此本节也对在质量评估任务中展现出有效性的大模型进行了介绍。
主观质量评估
主观评估研究
主观视频质量评估(VQA)通过足够多的受试者进行,是评估视频感知质量最可靠的方法。主观VQA研究通过收集人类对失真视频的评分,提供了宝贵的数据。这些研究可以是针对特定失真(如帧率变化)展开的,也可以涵盖多样化内容,如用户生成内容。这些数据为设计、评估和比较客观VQA模型提供了“黄金标准”。
主观VQA包括实验室内研究和在线众包研究两类。实验室研究在受控条件下进行,通常由可靠的评估人员完成,能够确保质量评估的准确性。而在线众包研究则能高效收集大量视频质量的人工标注,但在观看设备、环境、网络条件及参与者可靠性上控制较弱。
本文详细介绍了主观质量评估研究的全部环节,包括:
数据获取:
早期VQA数据集多从公开资源获取或自行录制,但受版权限制,视频数量有限,如LIVE VQA仅包含十几段高质量无失真视频。研究者通过模拟压缩、传输失真等方式生成不同程度的失真样本。UGC数据集则直接收集用户上传的原始视频,主要来源于社交平台,如YouTube。研究者通过特征抽样筛选代表性视频,形成规模达数万的多样化失真内容。
评估页面设计:
众包平台如Amazon Mechanical Turk和CrowdFlower是收集大规模视频质量评估标注的有效途径。视频播放在白色或灰色背景下进行,评分界面随后弹出,用户通过滑动条记录评分。同时,下一段视频会预加载,避免缓冲或卡顿干扰评分。参与者设备需满足要求,并需完成分心排除和设备调整步骤。实验室研究常用MATLAB开发界面,确保所有视频预加载以避免延迟。视频在高分辨率、适配任务的显示器上播放,需保留原始分辨率并支持高刷新率。参与者通常为普通志愿者,需通过视力测试、色觉测试等以确保结果可靠。
评估流程:
实验室和众包研究的流程相似。参与者首先接受任务说明,并观看几段包含不同失真和质量的视频样例。视频显示方法分为单刺激、双刺激和多刺激。单刺激更适合流媒体、IPTV等场景,因其更贴近实际观看体验,同时减少实验时长。但在失真较微弱的情况下,双刺激方法可能更为合适。训练阶段后,参与者开始对一组视频进行评分。常用评分方式包括离散量表(如绝对分类评分ACR、退化分类评分DCR)和连续评分量表,后者允许更自由和敏感的记录。为避免疲劳,实验通常分为多段,每段持续30-45分钟,并设置休息。对评分过于相似或不专注的参与者,其数据会被剔除。
众包评估质量控制:
在线众包研究需要严格的质量控制,以确保标签可靠。常用方法包括引入“黄金标准”视频,将工人评分与已知可靠评分对比,筛除不一致的参与者。此外,可随机重复部分视频以检测评分一致性,或通过 ITU 推荐协议和 SUREAL 方法拒绝不认真或分心的参与者。对于设备或网络不符合要求的用户,可通过检测技术参数或完全下载视频后播放来降低影响。如仍有问题,可礼貌终止测试并说明原因。Amazon Mechanical Turk 等平台提供的设备检测工具是重要的辅助措施。
主观评分分析:
为确保主观评分的一致性,可随机将参与者分为两组,计算两组平均意见分(MOS)的 Spearman 等级相关系数(SRCC),重复多次取平均值作为一致性指标。SRCC 超过 0.85 为理想,0.95 多见于简单任务。在线研究中,可通过“黄金标准”视频评分与实验室数据的差异筛选不可靠参与者,或检测重复视频的评分一致性。除了平均意见分数,差异平均意见分数(DMOS)通过计算评分与参考评分的差值,去除参考视频评分后进行归一化和线性映射,得到范围在 [0,100] 的最终结果。
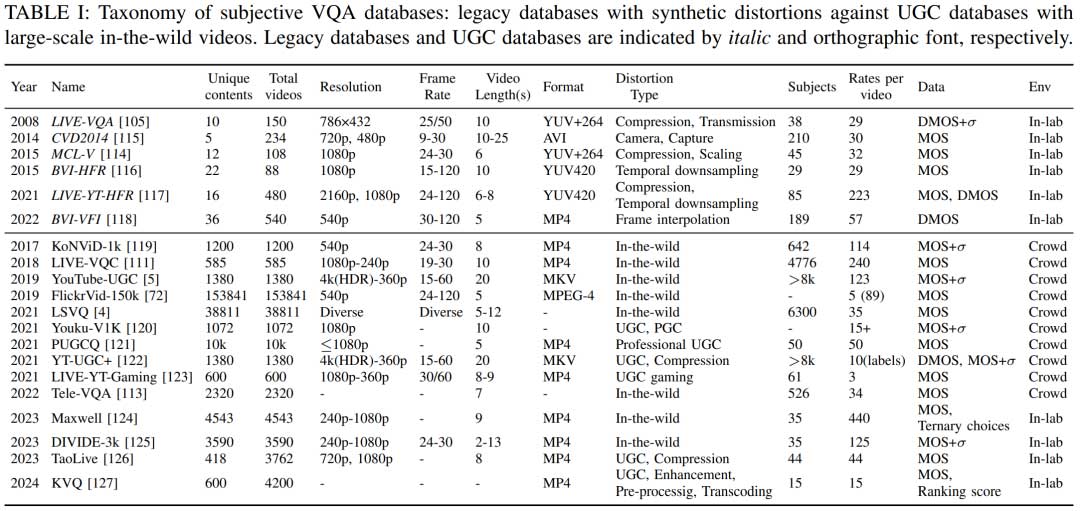
数据集
论文主要介绍了三类视频质量评估数据集,包括:
Professionally Generated Content (PGC):
早期的 VQA 数据集主要面向电视和流媒体,包含经过实验室处理的专业视频,模拟少量失真(如 MPEG 编码或数据包丢失)。这些数据集通常包括 10-20 个高质量原视频,经过特定处理后生成失真视频,由 20-40 名参与者在受控环境下获取 MOS 或 DMOS。其代表性受限,难以涵盖复杂多变的视频特性。表1总结了广泛使用的PGC VQA数据集。
User-Generated Content (UGC):
大多数早期数据库包含少量独特内容(10-15个),由少数参与者(<100)评分,数据量有限(但通常足够)。然而,在非专业环境下,视频采集或渲染、压缩、分享、重压缩、处理、传输和接收过程中可能发生多种失真,这些失真相互交织,形成新的无法命名的失真。为了模拟这些多种可能的时空失真,需要更大规模的真实视频数据集,以涵盖可能的表示空间。同时,需要更多的人工质量标注,才能准确映射视频测量到主观质量预测。因此,受LIVE挑战赛图片质量数据库启发,出现了大规模众包视频质量研究。
AI-generated Content (AIGC):
文生图(T2I)和文生视频(T2V)大模型的出现带来了评估AI生成内容(AIGC)感知质量的挑战,包括文本对齐、自然性、渲染和时间一致性。解决这些问题需要主观研究来基准测试和校准AIGC VQA模型。近年来,多个数据集致力于模拟AI生成图像的主观质量,关注人类偏好、感知质量、文本对齐和压缩感知质量。

客观质量评估
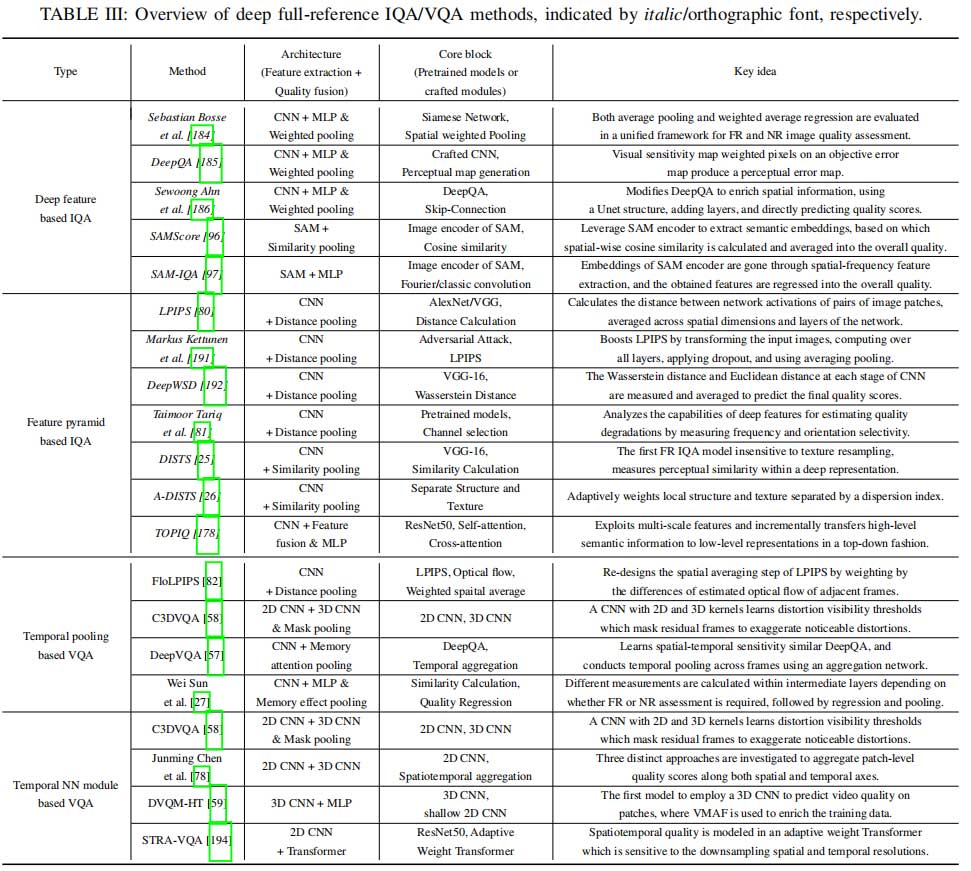
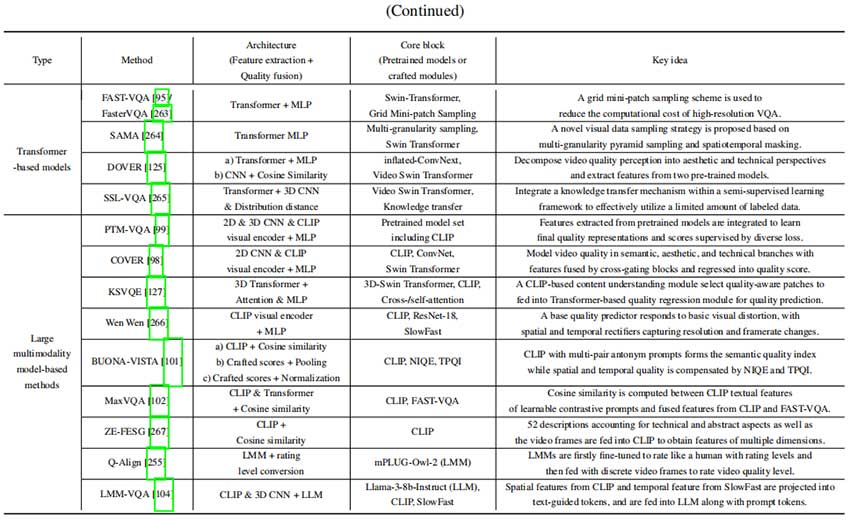
全参考和无参考质量评估模型
我们深入讨论了视频质量评估方法,涵盖全参考和无参考模型,重点分析基于深度学习的方法及常用损失函数。我们对当前主流质量评估方法进行分析、分类与总结,突出模型在质量预测中的性能与效率。下图概述了不同算法类别及其发展的时间线,为各类模型及其演化提供了结构化视图。两张表格分别总结了基于深度学习的全参考和无参考质量评估算法。详细内容请参考原论文。


基于深度学习的质量评估模型损失函数
接下来,我们结合现有质量评估模型的应用方法和评估任务,介绍了训练深度视频质量评估模型时常用的目标损失函数,包括L1/L2 loss, Monotonicity Loss, Cross entropy loss, Cosine Similarity Loss, SROCC/PLCC Loss等。
基准测试
在本节中,我们将深入比较全参考和无参考IQA/VQA算法在多个开源视频质量评估数据集上的表现。测试数据集包括LIVE-VQA, MCL-V, LIVE-YT-HFR, BVI-HFR, BVI-VFI等5类PGC数据集,LIVE-VQC, KoNViD-1k, YouTube-UGC等3类UGC数据集,T2VQA-DB,GAIA等2类AIGC数据集。

对于全参考质量评估模型,我们发现:
- 空间质量建模。参考视频可以精确地进行空间质量比较。传统模型中的结构相似性指标(如SSIM)和深度学习中的DISTS能有效建模空间质量。像DeepQA这样的模型中的视觉敏感度图也结合了人类感知,提升了空间失真的评估。
- 时间特征提取。引入光流(如FloLPIPS)或时空3D块特征(如C3DVQA)可提升在存在显著时间失真的数据集上的表现。
- 时间效应建模。注意力机制、记忆架构和记忆感知池化策略增强了时间质量预测。基于Transformer的模型(如STRA-VQA)通过动态优先处理关键时间特征,擅长捕捉长时间跨度的依赖,特别适用于可变帧率和帧插值等场景。
应用与挑战
我们讨论了深度学习视频质量评估(VQA)模型的实际应用,如图4,包括:服务端UGC视频编码与转码、面向感知质量优化的视频编码、面向感知质量优化的视觉增强、直播视频质量监测和AIGC图像视频质量评估。我们还探讨了当前面临的核心挑战以及未来的改进机会。目标是促进并激发未来在视频流媒体和社交媒体领域的研究工作和行业应用。随着技术的不断发展,如何优化VQA模型以更好地适应不同的视频质量评估需求,将成为未来研究的重点。同时,随着视频内容生成和分发模式的变化,VQA模型的创新和应用将进一步推动流媒体平台和社交媒体领域的技术进步。

总结与未来工作
我们对基于深度学习的视频质量评估研究进行了全面综述,涵盖主观和客观质量评估方法。本文总结了主观质量评估数据收集的一般流程及现有流行数据库,重点回顾了过去二十年内的全参考和无参考客观算法,特别关注近年深度学习驱动的VQA模型。其次,本文对现有FR和NR算法在新兴内容数据库上的效果和适应性进行了全面比较,并提供了有关在VQA模型中使用有效神经网络模块的见解。最后,我们讨论了深度学习VQA研究在实际应用中的局限和挑战,并对未来研究的重要方向进行了详细阐述。
基于深度学习的IQA/VQA模型在数据集、模型架构和训练策略方面面临诸多挑战,但也有广阔的改进空间。目前的视频质量评估数据集存在局限性,制约了数据驱动学习的潜力。构建大规模、无偏的数据集需耗费大量人力,包括精确的数据收集方法和心理学研究。未来的数据集需满足不断增长的流媒体需求,涵盖高帧率(HFR)、高动态范围(HDR)、虚拟/扩展现实(VR/XR)等先进格式,同时囊括多种内容类型,如屏幕内容、UGC、PGC、AIGC、远程呈现和点云数据,以适应新兴视频技术与消费者期望。
在模型架构方面,视频质量评估相比高层次计算机视觉任务有其独特挑战。尽管预训练神经网络在空间特征提取上表现出色,但应针对视频内容的低层次视觉任务设计专用架构。未来的架构需有效融合心理视觉原则,如记忆效应和感知校正,使预测更贴近人类视觉体验。此外,大模型的发展(如基于提示或特征的方法)提供了新的可能性,但需解决文本输出与人类质量判断的对齐,以及动态内容特征提取优化等问题。同时,设计兼具预测精度与计算效率的模型,如RAPIQUE、FAST-VQA和Faster-VQA,仍是重要目标。
训练策略也值得进一步探索。标注数据集的稀缺性是主要瓶颈,这凸显了局部训练、代理评分和无监督学习的重要性。损失函数的选择同样关键,Huber损失或复合损失函数可缓解复杂场景中无界损失的挑战。这些创新有助于开发出更强大、准确的VQA模型,能够应对多样化的内容类型与失真现象。
通过解决现有挑战并探索新方向,未来的研究可充分释放VQA在媒体制作、电信等领域的潜力,最终提升全球用户的视觉体验。希望本综述能激发视觉分析领域的进一步研究,并推动跨学科合作,共同推进视频质量评估的发展。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
