
长上下文 LLM 支持从 128K 到 10M 个 token 的扩展上下文窗口,从而支持诸如存储库级代码分析、长文档问答和多镜头上下文学习等高级应用。然而,这些功能在推理过程中面临着计算效率和内存使用方面的挑战。利用键值 (KV) 缓存的优化已经出现,旨在解决这些问题,重点是提高多轮交互中共享上下文的缓存重用率。PagedAttention、RadixAttention 和 CacheBlend 等技术旨在降低内存成本并优化缓存利用率,但通常仅在单轮场景中进行评估,而忽略了现实世界的多轮应用。
改进长上下文推理的努力主要集中在减少预填充和解码阶段的计算和内存瓶颈。预填充优化(例如稀疏注意、线性注意和快速压缩)降低了处理大型上下文窗口的复杂性。解码策略(包括静态和动态 KV 压缩、缓存卸载和推测解码)旨在有效管理内存限制。虽然这些方法提高了效率,但许多方法依赖于有损压缩技术,这可能会在前缀缓存至关重要的多轮设置中损害性能。现有的对话基准测试优先考虑单轮评估,在评估现实场景中共享上下文的解决方案方面存在差距。
微软和萨里大学的研究人员推出了 SCBench,这是一种基准测试,旨在通过以 KV 缓存为中心的方法评估 LLM 中的长上下文方法。SCBench 评估了 KV 缓存的四个阶段:生成、压缩、检索和加载,涉及 12 个任务和两种共享上下文模式(多轮和多请求)。该基准测试分析了 Llama-3 和 GLM-4 等模型上的稀疏注意、压缩和检索等方法。结果强调,在多轮场景中,sub-O(n) 内存方法表现不佳,而 O(n) 内存方法表现稳健。SCBench 深入了解了稀疏效应、任务复杂性以及长生成场景中的分布变化等挑战。
以 KV 缓存为中心的框架将 LLM 中的长上下文方法分为四个阶段:生成、压缩、检索和加载。生成包括稀疏注意和即时压缩等技术,而压缩涉及 KV 缓存删除和量化等方法。检索侧重于获取相关的 KV 缓存块以优化性能,而加载涉及动态传输 KV 数据进行计算。SCBench 基准测试通过 12 个任务评估这些方法,包括字符串和语义检索、多任务处理和全局处理。它分析了性能指标,例如准确性和效率,同时提供了对算法创新的见解,包括改进多请求场景的 Tri-shape 稀疏注意。
研究人员评估了六种开源长上下文 LLM,包括 Llama-3.1、Qwen2.5、GLM-4、Codestal-Mamba 和 Jamba,代表了各种架构,例如 Transformer、SSM 和 SSM-Attention 混合体。实验在 NVIDIA A100 GPU 上使用 BFloat16 精度,使用 HuggingFace、vLLM 和 FlashAttention-2 等框架。测试了八种长上下文解决方案,包括稀疏注意、KV 缓存管理和提示压缩。结果表明,MInference 在检索任务中表现出色,而 A-shape 和 Tri-shape 在多轮任务中表现出色。KV 压缩方法和提示压缩产生的结果好坏参半,通常在检索任务中表现不佳。SSM-attention 混合体在多轮交互中表现不佳,门控线性模型总体表现不佳。
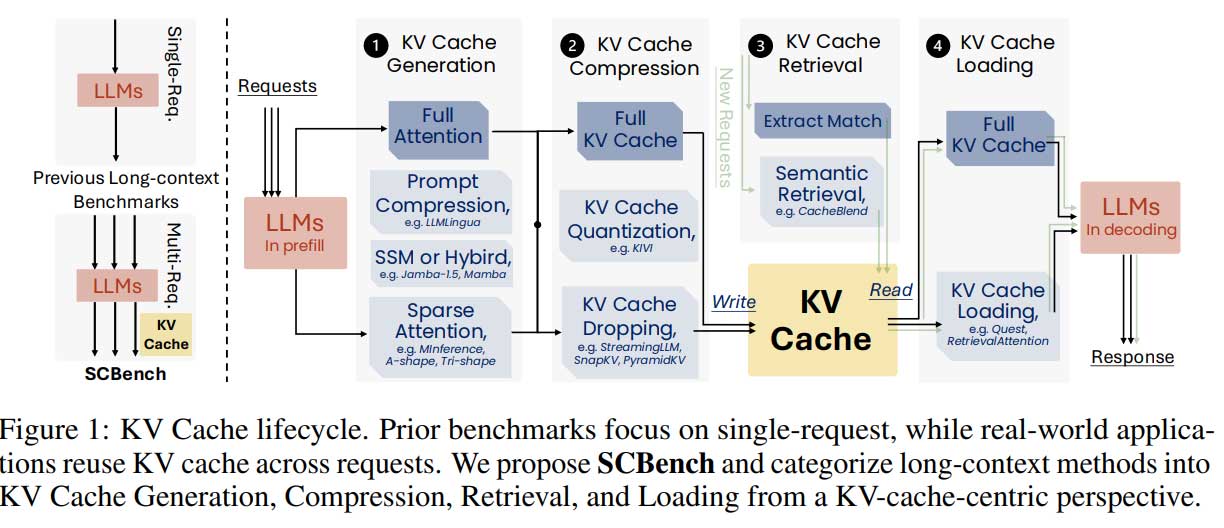
总之,这项研究强调了评估长上下文方法的一个关键差距,该方法传统上侧重于单轮交互,而忽略了现实世界 LLM 应用中普遍存在的多轮共享上下文场景。引入 SCBench 基准来解决这个问题,从 KV 缓存生命周期的角度评估长上下文方法:生成、压缩、检索和加载。它包括两种共享上下文模式的 12 个任务和四种关键功能:字符串检索、语义检索、全局信息处理和多任务处理。评估八种长上下文方法和六种最先进的 LLM 表明,sub-O(n)方法在多轮设置中表现不佳。相比之下,O(n) 方法表现出色,为改进长上下文 LLM 和架构提供了宝贵的见解。
更多详细信息请查看:https://huggingface.co/datasets/microsoft/SCBench
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54762.html
