
音频语言模型 (ALM) 在各种应用中发挥着至关重要的作用,从实时转录和翻译到语音控制系统和辅助技术。然而,许多现有解决方案都面临着诸如高延迟、大量计算需求以及对基于云的处理依赖等限制。这些问题对边缘部署提出了挑战,因为低功耗、最小延迟和本地化处理至关重要。在资源有限或隐私要求严格的环境中,这些挑战使得大型集中式模型不切实际。解决这些限制对于在边缘场景中充分发挥 ALM 的潜力至关重要。
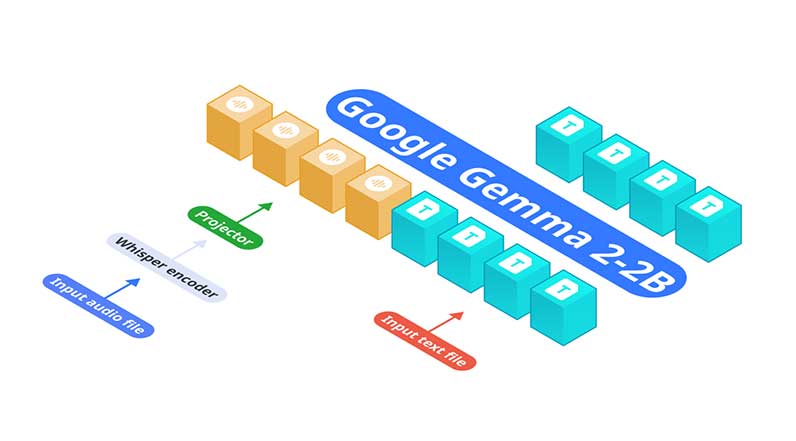
Nexa AI 宣布推出专为边缘部署设计的音频语言模型 OmniAudio-2.6B。与将自动语音识别 (ASR) 和语言模型分开的传统架构不同,OmniAudio-2.6B 将 Gemma-2-2b、Whisper Turbo 和自定义投影仪集成到一个统一的框架中。这种设计消除了与链接单独组件相关的低效率和延迟,使其非常适合计算资源有限的设备。
OmniAudio-2.6B 旨在为边缘应用提供实用、高效的解决方案。通过专注于边缘环境的特定需求,Nexa AI 提供了一种平衡性能与资源限制的模型,展现了其对推进 AI 可访问性的承诺。
技术细节和优势
OmniAudio-2.6B 的架构针对速度和效率进行了优化。Gemma-2-2b(精炼 LLM)和 Whisper Turbo(强大的 ASR 系统)的集成确保了无缝且高效的音频处理管道。定制投影仪连接了这些组件,从而减少了延迟并提高了运营效率。主要性能亮点包括:
- 处理速度:在 2024 Mac Mini M4 Pro 上,使用 Nexa SDK,OmniAudio-2.6B 以 FP16 GGUF 格式实现每秒 35.23 个令牌,以 Q4_K_M GGUF 格式实现每秒 66 个令牌。相比之下,一个著名的替代方案 Qwen2-Audio-7B 在类似硬件上每秒仅处理 6.38 个令牌。这一差异代表了速度的显著提升。
- 资源效率:该模型的紧凑设计最大限度地减少了对云资源的依赖,使其成为功率和带宽有限的可穿戴设备、汽车系统和物联网设备中应用的理想选择。
- 准确性和灵活性:尽管注重速度和效率,OmniAudio-2.6B 也具有很高的准确性,可以灵活地完成转录、翻译和摘要等任务。
这些进步使 OmniAudio-2.6B 成为寻求响应迅速、隐私友好的基于边缘的音频处理解决方案的开发人员和企业的实用选择。
性能洞察
基准测试凸显了 OmniAudio-2.6B 的出色性能。在 2024 Mac Mini M4 Pro 上,该型号每秒最多可处理 66 个令牌,大大超过了 Qwen2-Audio-7B 每秒 6.38 个令牌的速度。速度的提升扩大了实时音频应用的可能性。
例如,OmniAudio-2.6B 可通过实现更快的设备响应来增强虚拟助手,而无需担心云依赖带来的延迟。在医疗保健等实时转录和翻译至关重要的行业中,该模型的速度和准确性可以提高结果和效率。其边缘友好型设计进一步增强了其对需要本地化处理的场景的吸引力。
结论
OmniAudio-2.6B 代表着音频语言建模领域迈出的重要一步,解决了延迟、资源消耗和云依赖性等关键挑战。通过将高级组件集成到一个有凝聚力的框架中,Nexa AI 开发了一种平衡边缘环境速度、效率和准确性的模型。
OmniAudio-2.6B 的性能指标比现有解决方案高出 10.3 倍,为各种边缘应用提供了强大且可扩展的选项。该模型反映了人们对实用、本地化的 AI 解决方案的日益重视,为满足现代应用需求的音频语言处理技术的发展铺平了道路。
详细信息:https://huggingface.co/NexaAIDev/OmniAudio-2.6B
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54690.html
