
AI 系统正在通过实现与动态环境的实时交互来模拟人类认知。从事 AI 工作的研究人员旨在开发无缝集成音频、视频和文本输入等多模态数据的系统。通过模仿人类的感知、推理和记忆,这些系统可以应用于虚拟助手、自适应环境和持续实时分析。多模态大型语言模型 (MLLM) 的最新发展已在开放世界理解和实时处理方面取得了重大进展。然而,在开发能够同时感知、推理和记忆且不会因交替执行这些任务而效率低下的系统方面,仍存在一些挑战需要解决。
由于存储大量历史数据的效率低下以及需要同时处理能力,大多数主流模型都需要改进。许多 MLLM 中普遍存在的序列到序列架构迫使人们在感知和推理之间进行切换,就像人们在感知周围环境时无法思考一样。此外,对于长期应用来说,依赖扩展上下文窗口来存储历史数据可能更具可持续性,因为视频和音频流等多模态数据会在数小时内(更不用说数天)生成大量 token 。这种低效率限制了此类模型的可扩展性及其在需要持续参与的现实应用中的实用性。
现有方法采用各种技术来处理多模态输入,例如稀疏采样、时间池化、压缩视频标记和记忆库。虽然这些策略在特定领域有所改进,但它们无法实现真正类似人类的认知。例如,Mini-Omni 和 VideoLLM-Online 等模型试图弥合文本和视频理解差距。尽管如此,它们仍受到对顺序处理和有限记忆集成的依赖的限制。此外,当前系统以笨重的、依赖于上下文的格式存储数据,需要更大的灵活性和可扩展性才能实现连续交互。这些缺点凸显了对创新方法的需求,该方法将感知、推理和记忆分解为不同但协作的模块。
为了应对这些挑战,来自上海人工智能实验室、香港中文大学、复旦大学、中国科学技术大学、清华大学、北京航空航天大学和商汤集团的研究人员推出了 InternLM -XComposer2.5-OmniLive (IXC2.5-OL),这是一个专为实时多模态交互而设计的综合人工智能框架。该系统集成了尖端技术来模拟人类认知。IXC2.5 -OL 框架包含三个关键模块:
- 流式感知模块
- 多模式长记忆模块
- 推理模块
这些组件协同工作,处理多模态数据流、压缩和检索内存,并高效准确地响应查询。这种模块化方法受到人类大脑特殊功能的启发,可确保动态环境中的可扩展性和适应性。
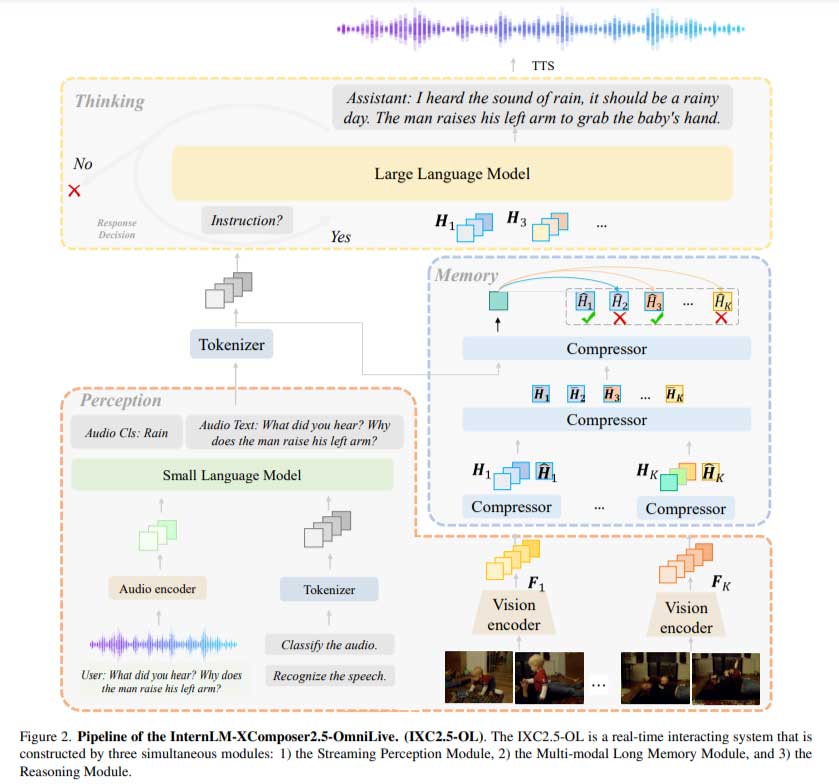
流式感知模块负责实时音视频处理,采用先进的音频编码模型Whisper和视频感知模型OpenAI CLIP-L/14,从输入流中获取高维特征,识别关键信息(如人类语音、环境声音等)并编码到内存中。同时,多模态长记忆模块将短期记忆压缩为高效的长期表征,并将其整合在一起,以提高检索准确率,降低内存成本。例如,它可以将数百万个视频帧压缩为紧凑的内存单元,大大提高系统的效率。推理模块采用先进的算法,从内存模块中检索相关信息,以执行复杂任务并回答用户查询,使IXC2.5-OL系统能够同时感知、思考和记忆,突破了传统模型的局限性。
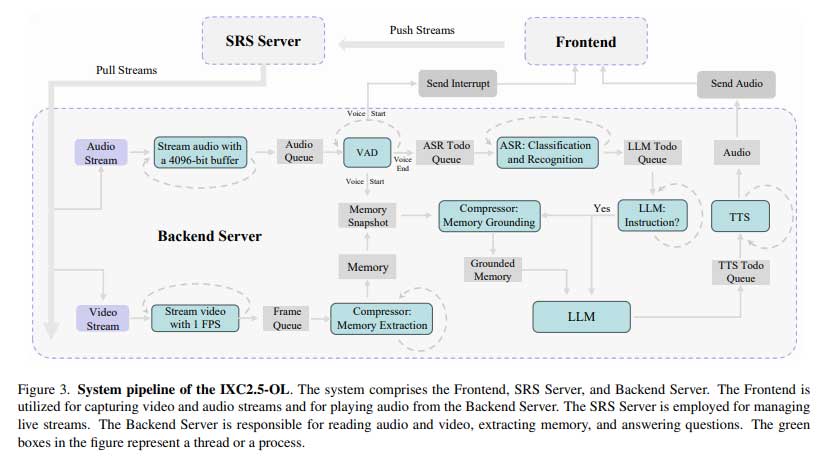
IXC2.5-OL 已在多个基准测试中得到评估。在音频处理中,该系统在 Wenetspeech 的中文测试网上实现了 7.8% 的词错误率 (WER),在 Test Meeting 上实现了 8.4% 的词错误率,优于 VITA 和 Mini-Omni 等竞争对手。对于 LibriSpeech 等英语基准测试,它在干净数据集上的 WER 为 2.5%,在嘈杂环境中的 WER 为 9.2%。在视频处理中,IXC2.5-OL 在主题推理和异常识别方面表现出色,在 MLVU 上实现了 66.2% 的 M-Avg 分数,在 StreamingBench 上实现了 73.79% 的最佳分数。该系统同时处理多模态数据流,确保出色的实时交互。
这项研究的主要结论包括:
- 该系统的架构模仿人类的大脑,将感知、记忆和推理分成不同的模块,确保可扩展性和效率。
- 它在 Wenetspeech 和 LibriSpeech 等音频识别基准以及异常检测和动作推理等视频任务中取得了最先进的结果。
- 该系统通过将短期记忆压缩为长期格式来有效处理数百万个标记,从而减少计算开销。
- 所有代码、模型和推理框架均可供公众使用。
- 该系统能够同时处理、存储和检索多模式数据流,从而实现动态环境中的无缝、自适应交互。
总之,InternLM-XComposer2.5-OmniLive 框架正在克服同时感知、推理和记忆的长期局限性。该系统利用受人类认知启发的模块化设计,实现了卓越的效率和适应性。它在 Wenetspeech 和 StreamingBench 等基准测试中实现了最先进的性能,展示了卓越的音频识别、视频理解和记忆集成能力。因此,InternLM-XComposer2.5-OmniLive 提供了无与伦比的实时多模式交互和可扩展的类人认知。
更多详细信息:https://github.com/InternLM/InternLM-XComposer/tree/main/InternLM-XComposer-2.5-OmniLive
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54668.html
