
CosyVoice是阿里巴巴通义实验室语音团队于今年7月份开源的语音生成大模型,依托大模型技术,实现自然流畅的语音生成体验。与传统语音生成技术相比,CosyVoice具有韵律自然、音色逼真等特点。自开源以来,CosyVoice凭借高品质的多语言语音生成、零样本语音生成、跨语言语音生成、富文本和自然语言的细粒度控制能力获得了广大社区开发者们的喜爱和支持。
如今,CosyVoice迎来全面升级,我们将发布CosyVoice2.0版本,提供更准、更稳、更快、 更好的语音生成能力。
超低延迟:CosyVoice 2.0提出了离线和流式一体化建模的语音生成大模型技术,支持双向流式语音合成,在基本不损失效果的情况下首包合成延迟可以达到150ms。
高准确度:CosyVoice 2.0合成音频的发音错误相比于CosyVoice 1.0相对下降30%~50%,在Seed-TTS测试集的hard测试集上取得当前最低的字错误率。合成绕口令、多音字、生僻字上具有明显的提升。
强稳定性:CosyVoice 2.0在零样本语音生成和跨语言语音合成上能够出色地保证音色一致性,特别是跨语言语音合成相比于1.0版本具有明显提升。
自然体验:CosyVoice 2.0合成音频的韵律、音质、情感匹配相比于1.0具有明显提升。MOS评测分从5.4提升到5.53(相同评测某商业化语音合成大模型为5.52)。同时, CosyVoice 2.0对于指令可控的音频生成也进行了升级,支持更多细粒度的情感控制,以及方言口音控制。
代码仓库及体验链接
- GitHub仓库:CosyVoice(https://github.com/FunAudioLLM/CosyVoice)查阅最新更新的CosyVoice 2
- 在线体验DEMO:https://www.modelscope.cn/studios/iic/CosyVoice2-0.5B
- 开源代码:https://github.com/FunAudioLLM/CosyVoice
- 开源模型:https://www.modelscope.cn/models/iic/CosyVoice2-0.5B
核心模型与算法亮点
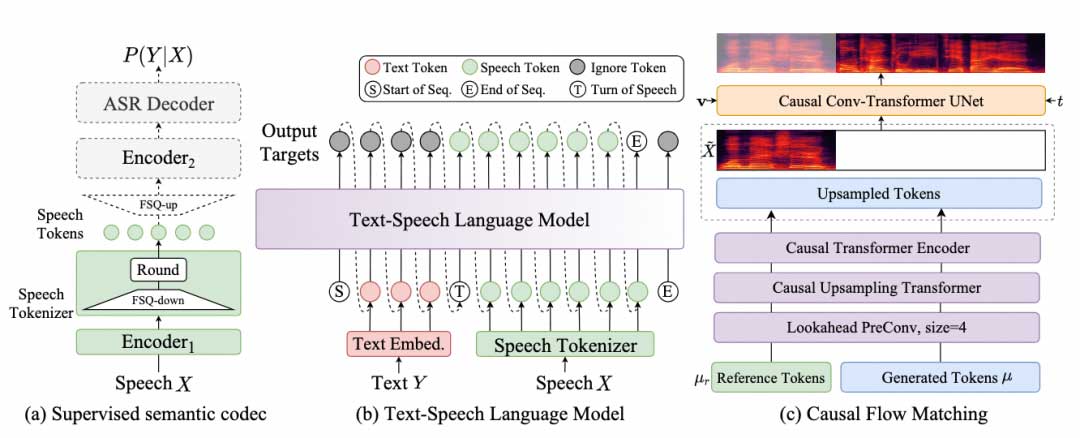
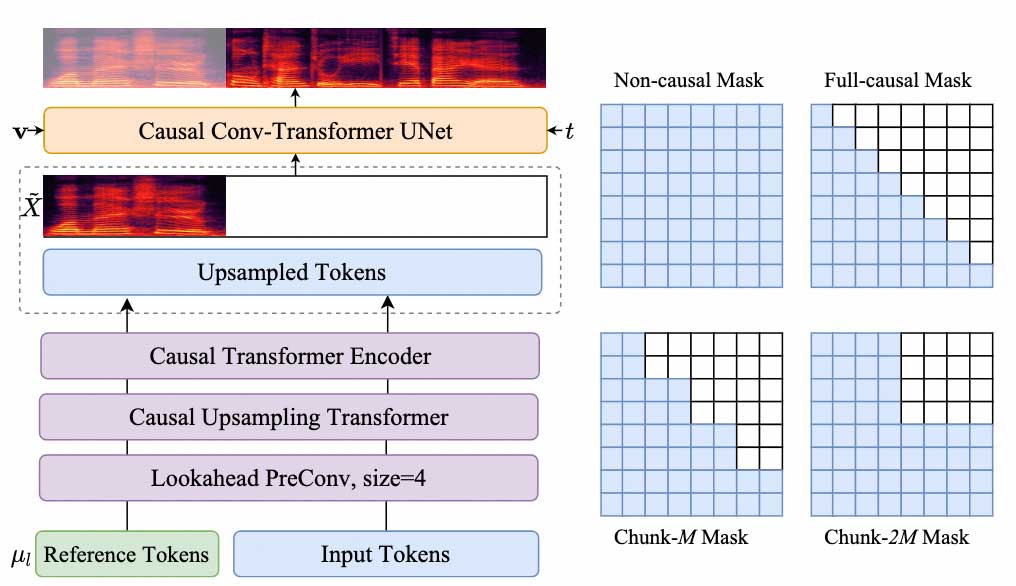
CosyVoice 2.0采用和CosyVoice 1一致的LLM+FM的建模框架,但是在具体实现上进行了如下几个要点的算法优化:
1)LLM backbone:CosyVoice 2.0采用预训练好的文本基座大模型(Qwen2.5-0.5B)替换了原来的Text Encoder + random Transformer的结构。采用LLM进行初始化能够更好的进行文本的语义建模,使得在可控生成,音频和文本的情感匹配,多音字发音上会有明显的收益。
2)FSQ Speech Tokenizer:CosyVoice 1.0采用VQ来提取Supervised semantic codec,码本大小为4096,但是有效码本只有963。CosyVoice 2.0采用了FSQ替换VQ,训练了6561的码本,并且码本100%激活。FSQ-Speech Tokenizer的使用使得CosyVoice 2.0在发音准确性上有明显提升。
3)离线和流式一体化建模方案:目前主流的语音生成大模型(CosyVoice, F5-TTS,MaskGCT,GPT-SoViTs等)均不支持流式语音生成。CosyVoice 2.0提出了如图2所示的离线和流式一体化建模方案,使得LLM和FM均支持流式推理,接收5个文字就可以合成首包音频,延迟大致在150ms。同时合成音质相比于离线合成基本无损。
4)指令可控的音频生成能力升级:优化后的 CosyVoice 2.0 在基模型和指令模型的整合上取得了重要进展,不仅延续了对情感、说话风格和细粒度控制指令的支持,还新增了中文指令的处理能力。其指令控制功能的扩展尤为显著,现已支持多种主要方言,包括粤语、四川话、郑州话、天津话和长沙话等,为用户提供了更丰富的语言选择。此外,CosyVoice 2.0 也引入了角色扮演的功能,如能够模仿机器人、小猪佩奇的风格讲话等。这些功能的提升还伴随着发音准确性和音色一致性的显著改善,为用户带来了更自然和生动的语音体验。
效果体验与部署
目前我们在创空间上提供了cosyvoice2.0语音复刻体验服务,可以支持用户上传音频文件或录音方式进行语音复刻。同时支持流式推理,用户无需等待全部音频合成完毕即可体验效果。
>>>创空间地址:https://www.modelscope.cn/studios/iic/CosyVoice2-0.5B
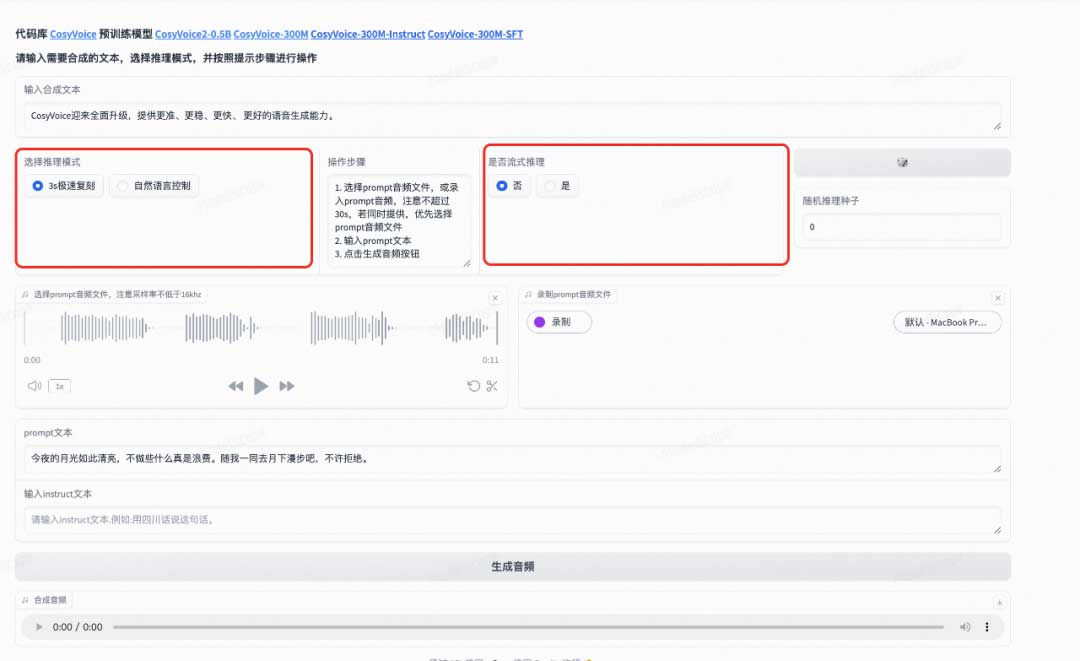
CosyVoice 2支持音色克隆以及自然语言控制的音频生成,可以选择相应的推理模式。
1)3s极速复刻
- 输入待合成文案
- 选择是否流式推理,流式推理具有更低的延迟,离线推理具有更好的上限效果
- 上传prompt音频,或者录制prompt音频
- 点击生成音频,等待一会儿就会听到合成的音频。
2)自然语言控制
- 输入待合成文案
- 上传prompt音频,或者录制prompt音频
- 输入instruct文本:例如“用粤语说这句话”,“用开心的语气说”,“模仿机器人的声音”等
- 点击生成音频,等待一会儿就会听到合成的音频。
同时,通义实验室也开源了cosyvoice2-0.5B的代码以及预训练模型,方便用户进行本地体验或部署。
>>开源代码:https://github.com/FunAudioLLM/CosyVoice
>>开源模型:https://www.modelscope.cn/models/iic/CosyVoice2-0.5B
下载模型后并安装好环境后,本地体验有两种方法:
- 启动webui,执行python webui.py即可;
- 脚本推理,根据readme在python中执行如下代码:

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
