
大型语言模型在理解自然语言、解决编程任务和应对推理挑战方面取得了令人瞩目的进步。然而,它们的高计算成本和对大规模数据集的依赖带来了一系列问题。许多数据集缺乏复杂推理所需的多样性和深度,而数据污染等问题可能会影响评估准确性。这些挑战需要更小、更高效的模型,这些模型可以在不牺牲可访问性或可靠性的情况下处理高级问题解决。
为了应对这些挑战,微软研究院开发了 Phi-4,这是一个拥有 140 亿个参数的语言模型,它在推理任务中表现出色,同时节省资源。在 Phi 模型系列的基础上,Phi-4 采用了合成数据生成、课程设计和训练后优化方面的新方法。这些创新使 Phi-4 能够有效地与 GPT-4 和 Llama-3 等更大的模型竞争,尤其是在以推理为重点的任务方面。
Phi-4 高度依赖高质量的合成数据进行训练,这些数据采用多智能体提示和指令反转等方法制作而成。这些数据确保模型能够遇到与现实世界推理任务紧密相关的多样化、结构化的场景。训练后技术(包括拒绝采样和直接偏好优化 (DPO))可进一步微调模型的响应,从而提高准确性和可用性。
技术进步
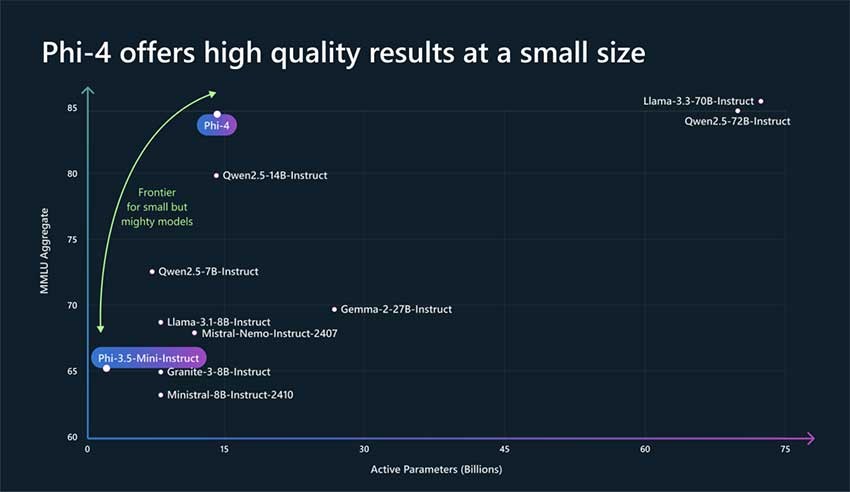
Phi-4 是一种旨在平衡效率和能力的模型。它拥有 140 亿个参数,在保持计算成本合理的同时实现了强大的性能。它的训练强调为推理和解决问题而定制的合成数据,以及经过精心过滤的有机数据集,以保持质量并避免污染。
主要特点包括:
- 合成数据生成:思路链提示等技术可以创建鼓励系统推理的数据集。
- 训练后细化:DPO 中的关键标记搜索通过瞄准关键决策点来确保输出的逻辑一致性。
- 扩展上下文长度:模型的上下文长度在训练中期从 4K 增加到 16K 个 token,从而能够更好地处理长链推理任务。
这些特性确保 Phi-4 解决推理成本和延迟等实际问题,使其非常适合实际应用。
结果和见解
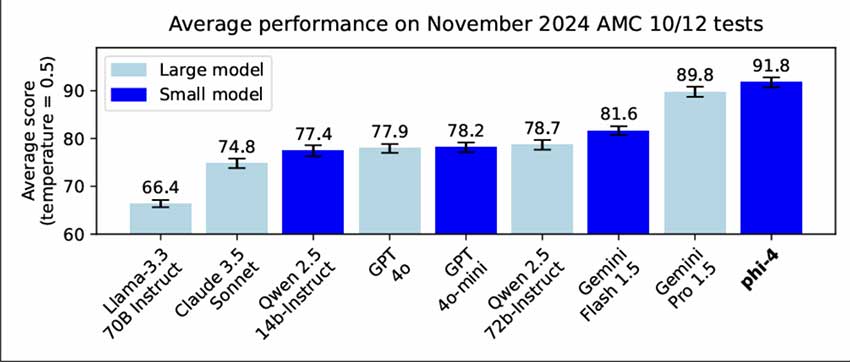
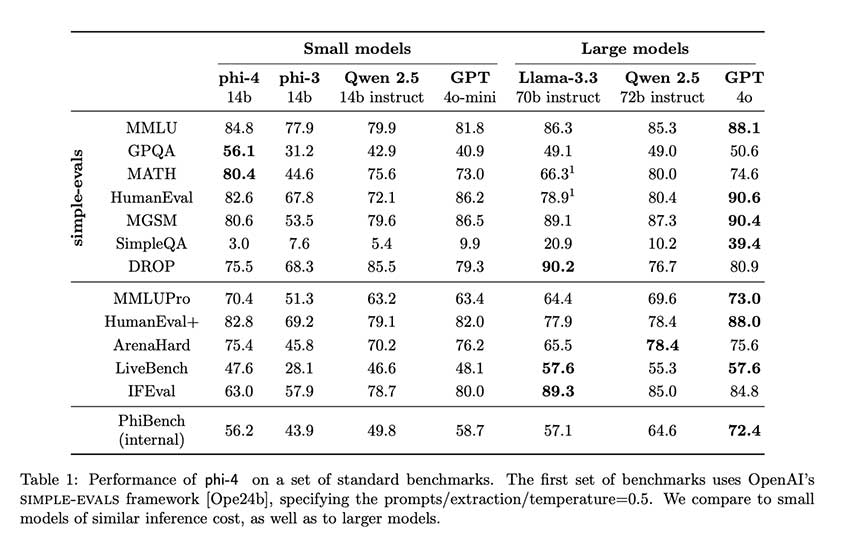
Phi-4 的表现凸显了其在推理密集型任务中的优势。它在多个基准测试中始终优于其教师模型、GPT-4o 甚至更大的模型:
- GPQA:得分 56.1,超过 GPT-4o 的 40.9 和 Llama-3 的 49.1。
- 数学:取得 80.4 分,体现出较高的解决问题能力。
- HumanEval:在编码基准测试中表现出色,得分为 82.6。
此外,Phi-4 在 AMC-10/12 等现实世界数学竞赛中取得了优异成绩,证明了其实用性。这些成果凸显了高质量数据和有针对性的训练方法的重要性。
结论
Phi-4 代表了语言模型设计方面的一次深思熟虑的进化,专注于效率和推理能力。通过强调合成数据和先进的后训练技术,它表明较小的模型可以实现与较大的模型相当的结果。这使得 Phi-4 在创建易于使用且用途广泛的 AI 工具方面迈出了一步。
随着人工智能领域的进步,Phi-4 等模型凸显了针对性创新在克服技术挑战方面的价值。其推理能力与效率之间的平衡为语言建模的未来发展树立了标杆。
详细信息:https://techcommunity.microsoft.com/blog/aiplatformblog/introducing-phi-4-microsoft%E2%80%99s-newest-small-language-model-specializing-in-comple/4357090
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54624.html
