
大型语言模型 (LLM)在人工智能领域取得了重大进展,随着参数和训练数据的增长,它们在各种任务上都表现出色。GPT -3、PaLM和Llama-3.1在具有数十亿个参数的众多应用中表现良好。然而,在低功耗平台上实施时,扩展LLM会给训练和推理查询带来严重困难。虽然它仍处于试验阶段且很少见,但事实证明,随着时间的推移,扩展可以有效地覆盖更多的人,而且随着过程的进展,它变得非常不可持续。还需要实现在计算能力较弱的设备上应用 LLM 的可能性,以解决推理的更基本方面并产生更多的 token。
目前优化大型语言模型的方法包括缩放、剪枝、提炼和量化。缩放通过增加参数来提高性能,但需要更多的资源。剪枝会删除不太重要的模型组件以减小尺寸,但往往会牺牲性能。提炼训练较小的模型来复制较大的模型,但通常会导致密度降低。量化降低了数值精度以提高效率,但可能会降低结果。这些方法无法很好地平衡效率和性能,因此人们转向优化“密度”作为开发大型语言模型的更可持续的指标。
为解决该问题,清华大学和ModelBest Inc.的研究人员提出了“能力密度”的概念,作为一种新指标来评估不同规模的LLM的质量,并描述其在有效性和效率方面的趋势。大型语言模型 ( LLM ) 的密度是有效参数大小与实际参数大小之比。有效参数大小表示参考模型为匹配给定模型的性能所需的参数数量。它使用缩放定律分两步估算:
(1)拟合参数大小和语言模型损失之间的函数;
(2)使用 S 型函数预测下游任务性能。
有效参数大小是在拟合损失和性能后计算出来的。模型密度计算为有效参数大小与实际大小之比,其中密度越高,每个参数的性能越好。它是优化模型的一个非常有用的概念,主要用于在资源有限的设备上部署。
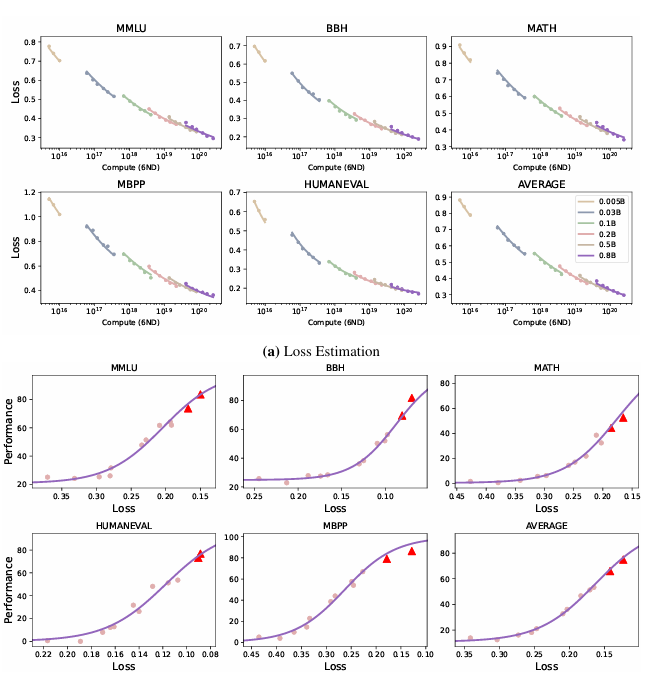
研究人员分析了29 个开源预训练模型,并利用开源工具进行基准测试,在5 次、3次和0 次等小样本设置下,评估了大型语言模型 ( LLM ) 在各种数据集(包括MMLU、BBH、MATH、HumanEval和MBPP)上的性能。使用思路链提示和不同的学习率调度器等技术,使用不同的参数大小、token 长度和数据规模对模型进行训练。
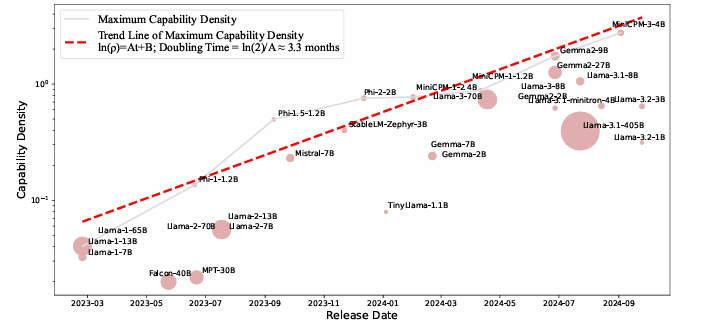
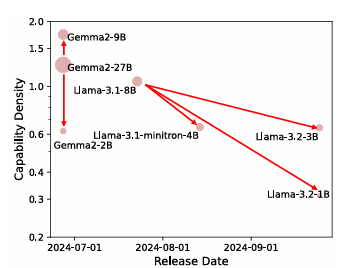
通过在不同大小的 token 上训练模型获得性能扩展曲线,其中在各种配置下测试了Llama、Falcon、MPT、Phi、Mistral和MiniCPM等模型。随着时间的推移,这些模型的密度显著增加,较新的模型(如MiniCPM-3-4B)比旧模型实现更高的密度。线性回归模型表明,LLM 密度大约每95天翻一番。这意味着功能更适中、成本更低的设计很快就能与更大、更复杂的模型竞争,而技术进步将为更高效的设计开辟道路。
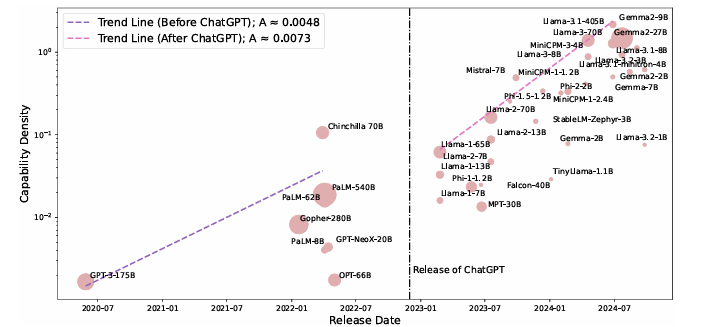
总之,所提出的方法通过展示快速发展和效率改进,突出了LLM中能力密度的指数级增长。对一些广泛使用的LLM基准的评估结果表明, LLM的密度每三个月翻一番。研究人员还提出了通过考虑更深层次的推理转向推理FLOP来评估密度的转变。该方法可用于即将开展的研究,并可能成为LLM领域的转折点!
论文地址:https://arxiv.org/pdf/2412.04315
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54553.html
