
如今,训练 AI 模型不仅要设计更好的架构,还要有效地管理数据。现代模型需要大量数据集,并且需要将这些数据集快速传送到 GPU 和其他加速器。问题是什么?传统的数据加载系统往往落后,导致一切速度变慢。这些旧系统严重依赖基于流程的方法,难以满足需求,导致 GPU 停机、训练时间更长、成本更高。当您尝试扩展或处理混合数据类型时,这种情况会变得更加令人沮丧。
为了解决这些问题,Meta AI 开发了 SPDL(可扩展且高性能的数据加载),这是一种旨在改善 AI 训练期间数据传递方式的工具。SPDL 使用基于线程的加载,这与传统的基于进程的方法不同,可以加快速度。它可以处理来自各种来源的数据(无论是从云端还是本地存储系统中提取),并将其无缝集成到您的训练工作流程中。
SPDL 在构建时就考虑到了可扩展性。它适用于分布式系统,因此无论您是在单个 GPU 还是大型集群上进行训练,SPDL 都能满足您的需求。它还设计为与最广泛使用的 AI 框架之一 PyTorch 配合使用,使团队更容易采用。而且由于它是开源的,任何人都可以利用它,甚至可以为它的改进做出贡献。
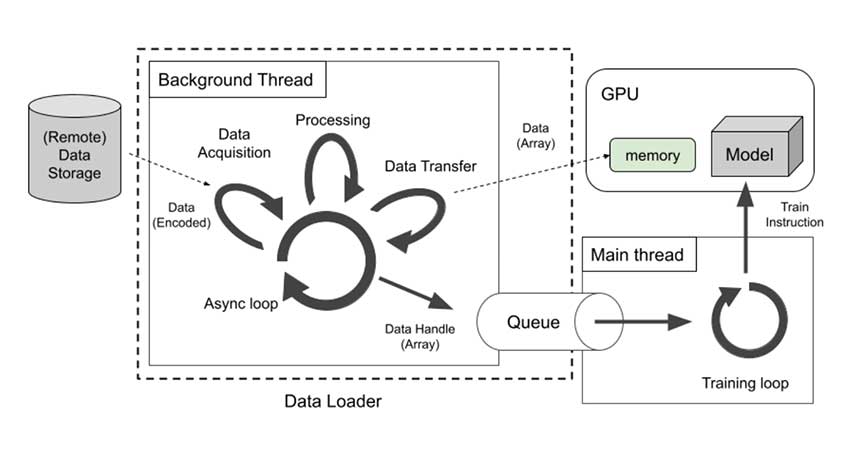
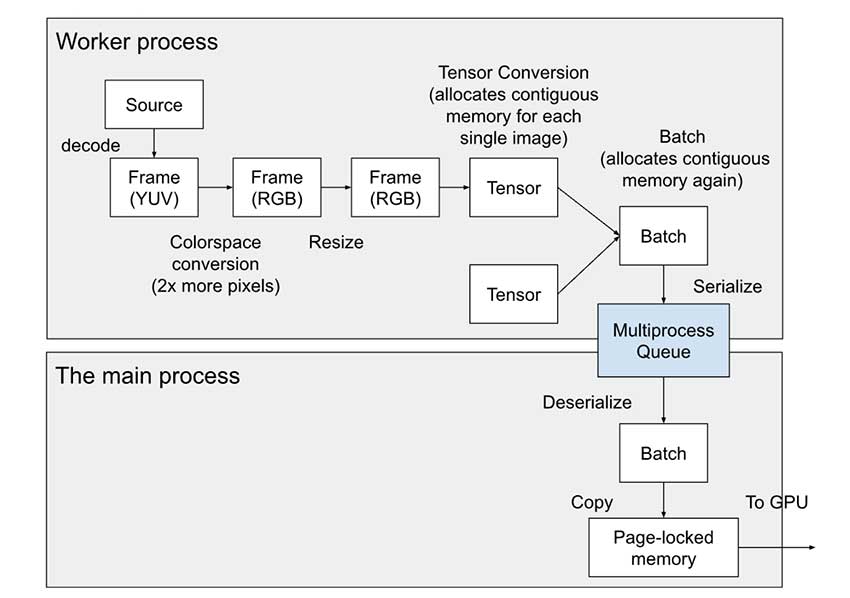
技术细节
SPDL 的主要创新在于其基于线程的架构。通过使用线程而不是进程,它避免了通常会减慢数据传输速度的通信开销。它还采用了预取和缓存等智能技术,确保您的 GPU 始终有数据可供处理。这减少了空闲时间并使整个系统更加高效。
该工具旨在处理大规模训练设置,支持多个 GPU 和节点。其模块化方法使其非常灵活 – 您可以自定义它来处理不同的数据格式,如图像、视频或文本。您还可以定制预处理步骤以满足您的特定需求。
SPDL 提供的功能如下:
- 更快的数据吞吐量:快速将数据传输到 GPU,避免速度变慢。
- 更短的训练时间:保持 GPU 繁忙,从而减少整体训练时间。
- 节省成本:通过更高效地运行,它降低了训练的计算成本。
- 用户友好型设计:与 PyTorch 配合良好并支持各种数据格式,使用起来非常简单。
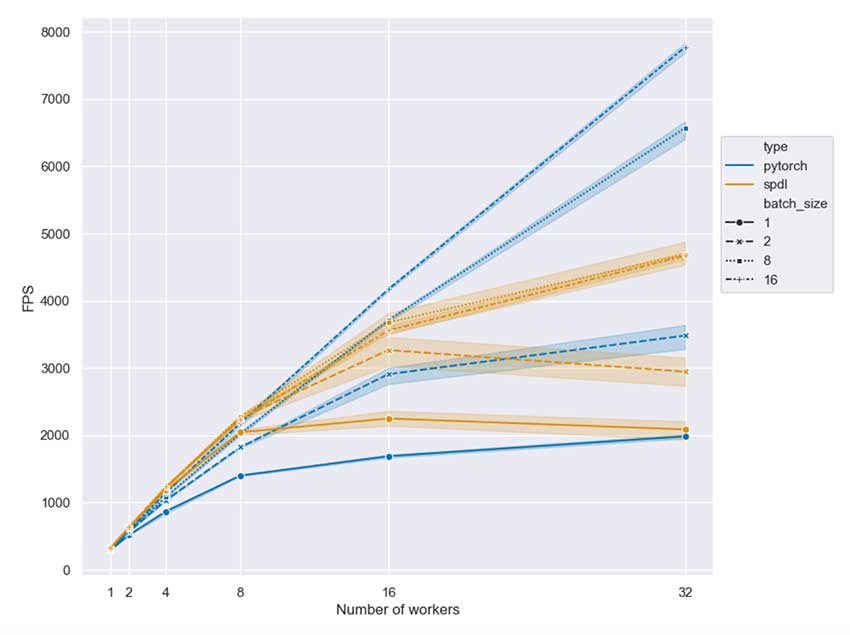
结果和见解
Meta AI 进行了广泛的基准测试,以了解 SPDL 的表现,结果令人印象深刻。与传统的基于流程的数据加载器相比,SPDL 将数据吞吐量提高了 3-5 倍。这意味着大型 AI 模型的训练时间最多可缩短 30%。
SPDL 的突出特点之一是它能够很好地处理高吞吐量数据流而不会引入延迟。这使其成为需要实时处理或频繁更新模型的应用程序的理想选择。Meta 已在其 Reality Labs 部门部署了 SPDL,用于涉及增强现实 (AR) 和虚拟现实 (VR) 的项目。
由于 SPDL 是开源的,更广泛的 AI 社区可以访问和使用它。尝试过它的开发人员已经强调了它的易用性和它提供的明显性能提升。
结论
SPDL 是对当今 AI 训练面临的数据管道挑战的深思熟虑的回应。通过重新思考数据的加载方式,Meta AI 创建了一个工具,使训练更快、更高效、更易于扩展。它的开源性质确保世界各地的研究人员和开发人员都能享受这些好处。
随着 AI 系统的要求越来越高,SPDL 等工具对于保持基础设施的快速发展至关重要。通过消除数据瓶颈,SPDL 不仅可以缩短训练时间,还可以为新的研究可能性打开大门。如果您希望简化 AI 工作流程,SPDL 值得探索。
详细信息:https://github.com/facebookresearch/spdl
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54511.html
