
自回归模型(Autoregressive models)用于生成离散标记序列。在该方法中,下一个标记由给定序列中的前一个标记决定。最近的研究表明,自回归生成连续嵌入序列也是可行的。然而,这种连续自回归模型 (CAM) 以类似的顺序生成这些嵌入,但它们面临着诸如扩展序列生成质量下降等挑战。这种下降是由于推理过程中的错误积累造成的,其中小的预测误差随着序列长度的增加而累积,导致输出质量下降。
传统的自回归图像和音频生成模型依赖于使用 VQ-VAE 将数据离散化为标记,以使模型能够在离散概率空间内工作。这种方法带来了重大缺陷,包括训练 VAE 时产生额外损失以及增加复杂性。虽然连续嵌入效率更高,但它们往往会在推理过程中积累错误,从而导致分布偏移并降低生成的输出质量。最近通过连续嵌入进行训练来绕过量化的尝试未能产生令人信服的结果,因为繁琐的非顺序掩蔽和微调技术会降低效率并限制研究界的进一步使用。
为了解决这个问题,伦敦玛丽女王大学和索尼计算机科学实验室的一组研究人员进行了详细的研究,并提出了一种方法来抵消误差累积,并在不增加复杂性的情况下在连续嵌入的有序序列上训练纯自回归模型。为了克服标准 AM 的缺点,CAM 在训练过程中引入了一种噪声增强策略,以模拟推理过程中发生的错误。该方法结合了整流流 (RF) 和 AM 在连续嵌入方面的优势。
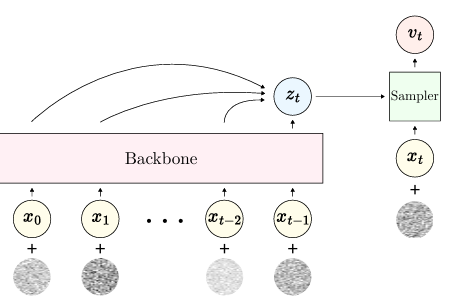
所提出的 CAM 背后的主要概念是在训练期间向序列中注入噪声,以模拟容易出错的推理条件。然后,它应用迭代反向扩散以自回归方式生成序列,逐步改善预测并纠正错误。通过使用噪声序列进行训练,CAM 经过预先训练,在生成较长序列的过程中能够抵御错误累积。此过程提高了生成序列的总体质量,尤其是对于音乐生成等任务而言,每个预测元素的质量对整体输出至关重要。
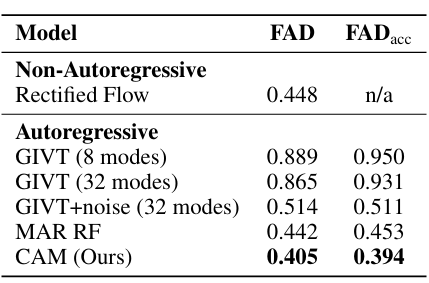
该方法在音乐数据集上进行了测试,并与实验的自回归和非自回归基线进行了比较。研究人员使用约 20,000 个单乐器录音的数据集进行训练和评估,这些录音具有 48 kHz 立体声音频。他们使用 Music2Latent 处理数据,以创建具有 12 Hz 采样率的连续潜在嵌入。基于具有 16 层和 1.5 亿个参数的转换器,CAM 使用 AdamW 进行了 400k 次迭代训练。与 GIVT 或 MAR 等基线相比,CAM 的表现优于其他模型,FAD 为 0.405,FADacc 为 0.394。CAM 为重建声谱和避免长序列中的错误累积提供了更高质量的基础;噪声增强方法也有助于提高 GIVT 分数。
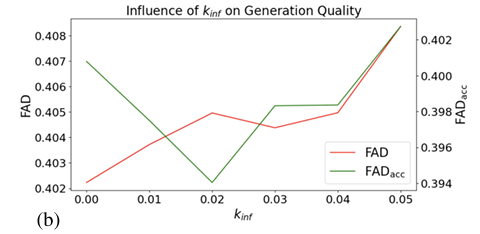
总之,所提出的方法在连续嵌入上训练纯自回归模型,直接解决误差累积问题。在推理时仔细校准的噪声注入技术进一步减少了误差累积。该方法为实时和交互式音频应用开辟了道路,这些应用受益于自回归模型的效率和顺序性,可以用作该领域进一步研究的基线!
论文地址:https://arxiv.org/abs/2411.18447
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54480.html
