
大型语言模型 (LLM) 的快速发展暴露了模型部署和通信方面的关键基础设施挑战。随着模型规模和复杂性的扩大,它们会遇到严重的存储、内存和网络带宽瓶颈。模型大小的指数增长带来了计算和基础设施压力,特别是在数据传输和存储机制方面。当前的模型(如 Mistral)展示了这些挑战的规模,每月产生超过 40 PB 的传输信息,需要大量的网络资源。模型检查点和分布式更新的存储要求可能会累积到原始模型大小的数百或数千倍。
现有的模型压缩研究已经开发出多种方法来减小模型大小,同时尝试保持性能。出现了四种主要的模型压缩方法:修剪、网络架构修改、知识提炼和量化。在这些技术中,量化仍然是最受欢迎的,它刻意牺牲准确性来换取存储效率和计算速度。这些方法的共同目标是降低模型复杂性,但每种方法都有固有的局限性。修剪可能会删除关键的模型信息,提炼可能无法完美捕捉原始模型的细微差别,而量化会引入熵变化。研究人员还开始探索结合多种压缩技术的混合方法。
IBM Research、特拉维夫大学、波士顿大学、麻省理工学院和达特茅斯学院的研究人员提出了 ZipNN,这是一种专为神经网络设计的无损压缩技术。该方法在模型大小缩减方面表现出巨大潜力,在流行的机器学习模型中实现了显著的空间节省。ZipNN 可以将神经网络模型压缩高达 33%,有些情况下缩减量甚至超过原始模型大小的 50%。当应用于 Llama 3 等模型时,ZipNN 的性能比普通压缩技术高出 17% 以上,压缩和解压速度提高了 62%。该方法有可能每月为 Hugging Face 等大型模型分发平台节省 1EB 的网络流量。
ZipNN 的架构旨在实现高效、并行的神经网络模型压缩。该实现主要用 C(2000 行)和 Python 包装器(4000 行)编写,利用 Zstd v1.5.6 库及其 Huffman 实现。核心方法围绕分块方法展开,该方法允许独立处理模型段,使其特别适合具有多个并发处理核心的 GPU 架构。压缩策略在两个粒度级别上运行:块级别和字节组级别。为了增强用户体验,研究人员实现了无缝的 Hugging Face Transformers 库集成,从而实现了自动模型解压缩、元数据更新和本地缓存管理,并带有可选的手动压缩控制。
ZipNN 的实验评估是在一台拥有 10 个内核和 64GB RAM 的 Apple M1 Max 机器上进行的,该机器运行的是 macOS Sonoma 14.3。模型压缩性显著影响了性能变化,FP32 常规模型大约有 3/4 的内容不可压缩,而 BF16 模型中只有 1/2,纯净模型中则更少。与 LZ4 和 Snappy 的比较测试表明,虽然这些替代方案速度更快,但它们并没有节省任何压缩成本。下载速度测量显示出有趣的模式:初始下载速度范围为 10-40 MBps,而缓存下载的速度明显更高,为 40-130 MBps,具体取决于机器和网络基础设施。
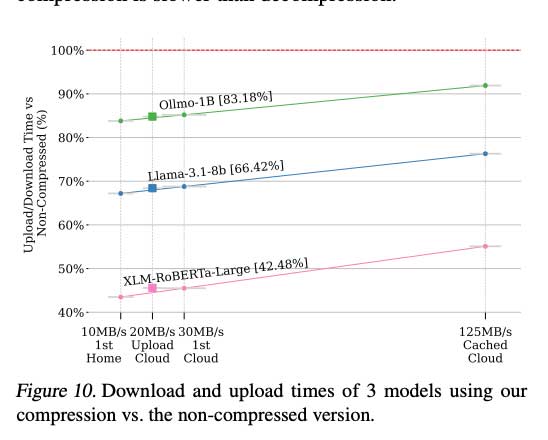
ZipNN 的研究突出了对机器学习模型的当代前景的重要洞察:尽管呈指数级增长和过度参数化,但模型存储和通信仍然存在严重的低效率。该研究揭示了模型架构中存在大量冗余,可以通过有针对性的压缩技术系统地解决。虽然目前的趋势有利于大型模型,但研究结果表明,可以在不损害模型完整性的情况下节省大量空间和带宽。通过根据神经网络架构定制压缩,可以以最小的计算开销实现改进,为模型可扩展性和基础设施效率日益严峻的挑战提供解决方案。
论文地址:https://arxiv.org/abs/2411.05239
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54440.html
