
视觉语言模型 (VLM) 已经取得了长足的进步,但在有效推广到不同任务方面,它们仍然面临重大挑战。这些模型通常难以处理各种输入数据类型,例如各种分辨率的图像或需要精细理解的文本提示。除此之外,在计算效率和模型可扩展性之间找到平衡并非易事。这些挑战使得 VLM 难以适用于许多用户,尤其是那些需要适应性强的解决方案的用户,这些解决方案在从文档识别到详细图像字幕制作等各种实际应用中表现始终良好。
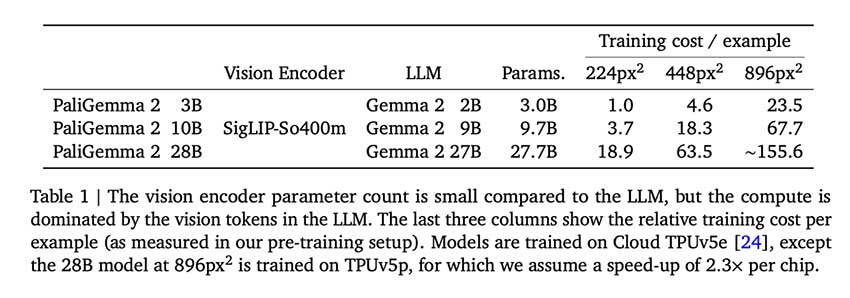
Google DeepMind 最近推出了PaliGemma 2系列,这是一系列全新的视觉语言模型 (VLM),参数大小分别为 30 亿 (3B)、100 亿 (10B) 和 280 亿 (28B)。这些模型支持 224×224、448×448 和 896×896 像素的分辨率。此版本包含九个预训练模型,具有不同的大小和分辨率组合,可用于各种用例。其中两个模型还在包含图像-文本标题对的 DOCCI 数据集上进行了微调,并在 448×448 像素的分辨率下支持 3B 和 10B 的参数大小。由于这些模型是开放重量的,因此可以轻松地直接替代或升级原始 PaliGemma,为用户提供更大的迁移学习和微调灵活性。

技术细节
PaliGemma 2 在原始 PaliGemma 模型的基础上,结合了 SigLIP-So400m 视觉编码器和 Gemma 2 语言模型。这些模型分三个阶段进行训练,使用不同的图像分辨率(224px、448px 和 896px),以便根据每个任务的具体需求实现灵活性和可扩展性。PaliGemma 2 已在 30 多个传输任务上进行了测试,包括图像字幕、视觉问答 (VQA)、视频任务以及 OCR 相关任务,如表格结构识别和分子结构识别。PaliGemma 2 的不同变体在不同条件下表现出色,模型越大、分辨率越高,通常表现更好。例如,28B 变体提供了最高的性能,但它需要更多的计算资源,因此适合于延迟不是主要问题的更苛刻的场景。
PaliGemma 2 系列之所以引人注目,有几个原因。首先,提供不同规模和分辨率的模型使研究人员和开发人员能够根据他们的特定需求、计算资源以及效率和准确性之间的理想平衡来调整性能。其次,这些模型在一系列具有挑战性的任务中表现出色。例如,PaliGemma 2 在涉及文本检测、光学乐谱识别和放射线报告生成的基准测试中取得了最高分。在 OCR 的 HierText 基准测试中,PaliGemma 2 的 896px 变体在单词级识别准确度方面优于以前的模型,显示出精确度和召回率的提高。基准测试结果还表明,增加模型大小和分辨率通常会在各种任务中获得更好的性能,突出了视觉和文本数据表示的有效结合。
Google 的 PaliGemma 2 代表着视觉语言模型向前迈出了有意义的一步。通过提供三个尺度的九种开放权重可用性模型,PaliGemma 2 满足了从资源受限场景到高性能研究任务等广泛的应用和用户需求。这些模型的多功能性及其处理各种传输任务的能力使其成为学术和行业应用的宝贵工具。随着越来越多的用例集成多模式输入,PaliGemma 2 完全有能力为人工智能的未来提供灵活有效的解决方案。
论文地址:https://huggingface.co/collections/google/paligemma-2-release-67500e1e1dbfdd4dee27ba48
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54435.html
